- Блог белорусского сисадмина
- полезные записки
- Мониторинг логов в Zabbix и возврат триггера в OK
- Мониторинг лог файла в Zabbix
- Введение
- Настройка мониторинга логов
- Создание триггера на событие из лога
- Заключение
- Zabbix Documentation 5.2
- Sidebar
- Table of Contents
- 6 Мониторинг файлов журналов
- Обзор
- Настройка
- Важные замечания
- Извлечение совпадающей части регулярного выражения
- Использование параметра максзадержка
- Действия, если произошла ошибка связи между агентом и сервером
Блог белорусского сисадмина
полезные записки
Мониторинг логов в Zabbix и возврат триггера в OK
Zabbix может многое. Главное — суметь это настроить 🙂 Одна из полезных возможностей — мониторинг лог-файлов на наличие определенных записей. Если вы хотите держать руку на пульсе событий при мониторинге серверов, то без мониторинга логов никак не обойтись: почти все серьезные ошибки пишутся в логи и во многих случаях гораздо эффективнее мониторить один-два лога, чем настраивать отслеживания статуса 50 сервисов, работоспособность которых не всегда легко проверить.
Собственно, в самой настройке мониторинга логов нет ничего сложного: добавляем соответствующий Item, пишем регулярное выражение для триггера и начинаем получать уведомления! Например, мы хотим отслеживать все ошибки из System лога на серверах под управлением OS Windows. Для этого, создаем следующий Item:
Параметры следующие: System — лог, который отслеживаем; второй параметр — регулярное выражение, которое ищем (пропущен, берем все записи); третий — «Error» — важность, согласно классификации ОС; четвертый — любой источник; пятый — @eventlog — макрос, который исключает события с идентификаторами ^(1111|36888|36887|36874)$; шестой — максимальное кол-во строк, которое мы отправляем серверу в секунду (неограниченное); последний параметр — skip — заставляет сервер читать только новые записи лога, а не перечитывать его весь.
В качестве триггера мы используем следующую строку:
Т.е. мы берем любую строку, которая попала в Item и высылаем уведомление.
После такой настройки мы получим первую ошибку из лога и триггер будет висеть в состоянии PROBLEM до скончания веков, т.к. нет события, которое его переводит в состояние OK. Для решения этой проблемы необходимо добавить к триггеру еще одно условие: наличие новых данных в течение промежутка времени, меньшего, чем время опроса Item. Т.е. если мы проверяем лог на ошибки раз в минуту, то нам надо поставить любой промежуток времени, меньший, чем минута. Итоговый триггер будет выглядеть как-то так:
Выглядеть это будет как «нашли что-то в Item» И «за последние 10 секунд были получены новые данные». При следующей проверке триггер перейдет в состояние OK, т.к. за последние 10 секунд новых данных получено не было. Других способов возврата триггера для лога в нормальное состояние в заббиксе версии 2 не предусмотрено.
Мониторинг лог файла в Zabbix

Zabbix умет анализировать любой лог файл, сохранять его в свою базу, рассылать алерты по каким-то событиям. Я решил использовать эту возможность для анализа лог файла утилиты acpupsd для отправки оповещений об отключении электричества. Решается данная задача стандартным функционалом заббикса, описанного в документации.
Введение
Ранее я рассказывал об использовании утилиты управления упсами марки apc — apcupsd. Я показал, как установить apcupsd на hyper-v и xenserver для корректного завершения работы при отключении электричества. Рекомендую ознакомиться, если вас интересует этот вопрос. Его не всегда получается быстро и удобно решить. На помощь приходит apcupsd.
Указанные конфигурации у меня успешно работают, проверено годами. Я решил настроить отправку оповещений на почту через zabbix при пропадании электричества. Да и просто хочется хранить информацию об инцидентах в одном месте. Почтовые сообщения не всегда будут доставлены, нужно следить, чтобы на резервное питание были подключены все устройства, которые обеспечивают связь с интернетом. Частенько бывает, что при выключении электричества у провайдера так же выключается оборудование и связи нет. Либо ваш свитч, к которому подключен сервер, выключится и сообщение не будет доставлено.
Заранее позаботьтесь об этих вещах. Пишу об этом, потому что сам недавно на одном объекте все запитал от упсов, но забыл про свитч. В итоге об отключении электричества я узнал уже после того, как его вернули назад и сервера автоматически поднялись. Если у вас еще не настроен сервер мониторинга, рекомендую мою подробную статью с видео об установке и настройке zabbix на centos 9 или установка zabbix 3.4 на debian 9.
Настройка мониторинга логов
Для того, чтобы мониторить лог файл, на сервере должен быть установлен zabbix agent, а сам сервер добавлен в панель мониторинга. Я буду следить за логом программы apcupsd, который располагается по пути /var/log/apcupsd.events. Идем в веб интерфейс заббикса и добавляем новый итем к интересующему нас хосту. Если у вас таких будет несколько, то создавайте сразу шаблон. В моем случае у меня один сервер, поэтому я буду добавлять новый элемент сразу на него.
Создаем новый итем со следующими параметрами:
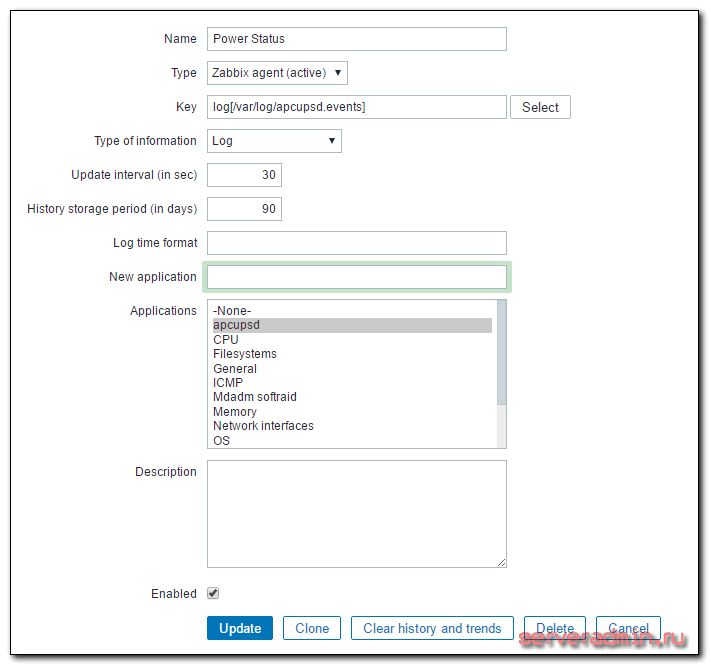
| Name | Имя нового итема. Можете указать любое название. |
| Type | Тип элемента. Обязательно выбираем Zabbix agent (active). По-умолчанию будет другой тип стоять. |
| Key | Ключ данных, log — тип, в квадратных скобках путь до лог файла. |
| Type of information | Указываем тип информации, поступающей в итем. |
Остальные параметры оставляете на свое усмотрение. Рекомендую время обновления итема ставить поменьше, чтобы оперативно получить информацию об инциденте. У меня стоит 30 секунд.
После того, как вы сохраните новый итем, через несколько минут начнут поступать данные. Проверять их как обычно в Latest data. В данной конфигурации будут сохраняться все строки из файла. В моем случае это не страшно, так как записей будет очень мало. Они создаются только по событиям в электро сети, а они случаются редко, поэтому я не стал делать фильтр по строкам или словам.
Но это только пол дела. Мы стали собирать логи, теперь нам нужно настроить отправку оповещения при пропадании электричества.
Создание триггера на событие из лога
Мы будем слать оповещение не только в момент отключения электричества, но и тогда, когда оно снова появится. Так что в триггере будут два условия:
- Условие активации события.
- И условие его прекращения.
Открываем вкладку с триггерами хоста и добавляем туда новый триггер со следующими параметрами:
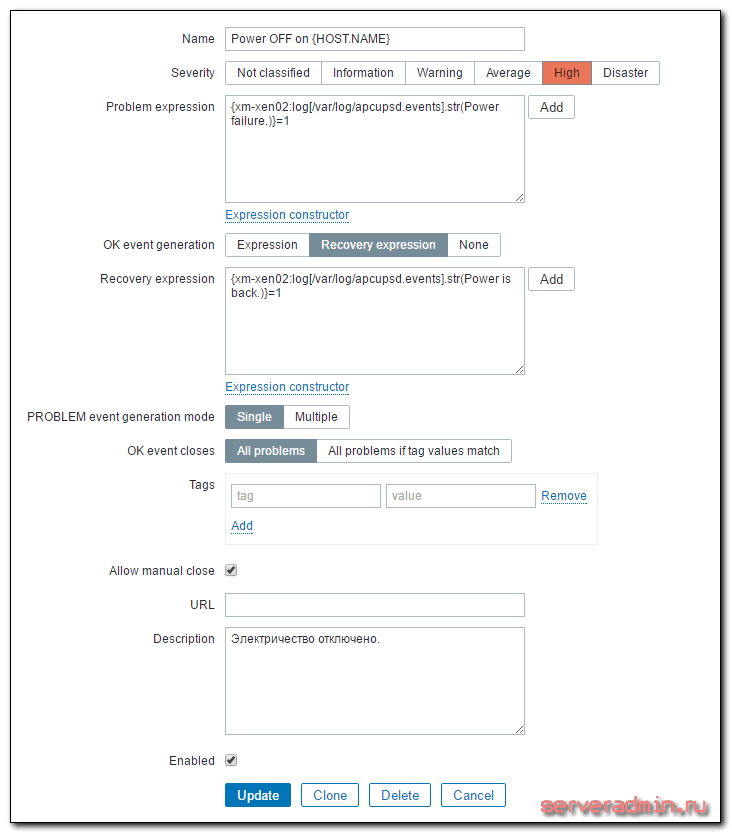
| Name | Имя триггера. Может быть любым. |
| Problem expression | |
| Recovery expression |
Рассказываю подробнее, что тут написано. xm-xen02 — имя сервера. Power failure. — строка в лог файле, которая появляется при отключении электричества. Когда оно возвращается, появляется запись Power is back. В общем виде лог выглядит примерно следующим образом:
Становится понятно, почему я взял именно эти строки. На этом все. После сохранения триггера он начнет работать и следить за итемом, который собирает строки из лога. Как только появятся строки, попадающие под условие, вы получите оповещение.
Заключение
Отладить работу оповещения об отключении электричества достаточно трудно, так как дергать по этому поводу шнур с питанием не хочется. Я пошел другим путем. Во время отладки использовал общий лог файл /var/log/messages и останавливал службу chronyd. Во время остановки, она пишет информацию об этом в лог файл, а при запуске так же сообщает, что запустилась. Я просто настроил итем и триггер на нужные строки и убедился, что все работает как надо. После этого уже сделал по аналогии итемы и триггеры для apcupsd. Рекомендую поступить похожим образом и потестировать функционал.
Zabbix Documentation 5.2
Sidebar
Table of Contents
6 Мониторинг файлов журналов
Обзор
Zabbix можно использовать для централизованного мониторинга и анализа файлов журналов с/без поддержки ротации журналов.
Можно использовать оповещения для предупреждения пользователей, когда файл журнала содержит конкретные строки или шаблоны строк.
Для наблюдения за файлом журнала у вас должно быть:
Настройка
Проверка параметров агента
Настройка элемента данных
Настройте элемент данных для мониторинга журнала.

Все обязательные поля ввода отмечены красной звёздочкой.
Специально для элементов данных наблюдения за журналами вы должны указать:
| Тип | Здесь выберите Zabbix агент (активный). |
| Ключ | Укажите: log[/путь/к/файлу/имя_файла, , , , , , ] или logrt[/путь/к/файлу/регулярное_выражение_описывающее_шаблон_имени_файла, , , , , , ] Zabbix агент фильтрует записи из файла журнала по регулярному выражению, если оно указано. Если требуется только количество совпадающих строк укажите: log.count[/путь/к/файлу/имя_файла, , , , , ] или logrt.count[/путь/к/файлу/регулярное_выражение_описывающее_шаблон_имени_файла, , , , , ]. Убедитесь, что у файла имеются права на чтение для пользователя ‘zabbix’, в противном случае состояние элемента данных будет ‘unsupported’. Для получения более подробных сведений смотрите информацию о ключах log, log.count, logrt и logrt.count в разделе поддерживаемых ключей элементов данных Zabbix агентом. |
| Тип информации | Выберите здесь Журнал (лог) для элементов данных log и logrt или Числовой (целое положительное) для элементов данных log.count и logrt.count. Если используется опциональный параметр вывод , вы можете выбрать подходящий тип информации, отличный от “Журнал (лог)”. Обратите внимание, что выбор не журнального типа информации приведет к потере локального штампа времени. |
| Интервал обновления (в сек) | Этот параметр задает как часто Zabbix агент будет проверять наличие любых изменений в файле журнала. Указав этот параметр равным 1 секунде, вы можете быть уверенными, что получите новые записи как можно скорее. |
| Формат времени журнала | В этом поле вы можете опционально задать шаблон для анализа штампа времени строки журнала. Если оставить пустым, штамп времени не будет анализироваться. Поддерживаемые значения: * y: Год (0001-9999) * M: Месяц (01-12) * d: День (01-31) * h: Час (00-23) * m: Минута (00-59) * s: Секунда (00-59) Например, рассмотрим следующую строку из файла журнала Zabbix агента: “ 23480:20100328:154718.045 Zabbix agent started. Zabbix 1.8.2 (revision 11211).” Она начинается шестью символами обозначающими PID, далее следует дата, время, и остальная часть строки. Форматом времени журнала для этой строки является “pppppp:yyyyMMdd:hhmmss”. Обратите внимание, что символы “p” и “:” являются лишь заменителями и могут быть чем угодно, за исключением “yMdhms”. |
Важные замечания
Извлечение совпадающей части регулярного выражения
Иногда мы можем захотеть извлечь только интересующие значения из требуемого файла вместо того, чтобы получать всю строку, в случае когда найдено совпадение с регулярным выражением.
Начиная с Zabbix 2.2.0, элементы данных файлов журналов расширены возможностью получения извлечения требуемых значений из строк файла. Добавился дополнительный параметр вывод у элементов данных log и logrt .
Использование параметра ‘вывод’ позволяет обозначить подгруппу совпадения в которой мы можем быть заинтересованы.
должно позволить получить количество записей со следующего содержания:
Причина, почему Zabbix вернет только одно число, потому что параметр ‘вывод’ здесь определен как \1 ссылка только на первую интересующую подгруппу: (9+)
Вместе с возможностью извлечения и получения числа, значение можно использовать в определениях триггеров.
Использование параметра максзадержка
Параметр ‘максзадержка’ в элементах данных журналов позволяет игнорировать более старые строки с целью получения наиболее новых строк проанализированных в течении “максзадержка” секунд.
По умолчанию элементы данных мониторинга журналов забирают все новые строки появляющиеся в файлах журналов. Однако, имеются приложения, которые в некоторых ситуациях начинают записывать огромное количество сообщений в свои файлы журналов. Например, если база данных или DNS сервер недоступны, то такие приложения могут флудить файлы журналов тысячами практически идентичных сообщений об ошибке до тех пор пока не восстановится нормальный режим работы. По умолчанию, все эти сообщения добросовестно анализируются и совпадающие строки оправляются на сервер, как настроено в элементах данных log и logrt .
Встроенная защита от перегрузов состоит из настраиваемого параметра ‘макс. кол-во строк’ (защищающий сервер от слишком большого количества приходящих совпадающих строк в журнале) и ограничения в 4*’макс. кол-во строк’ (защищает CPU и I/O хоста от перегрузки агентам одной проверкой). Тем не менее имеется 2 проблемы со встроенным механизмом защиты. Первая, на сервер будет отправлено большое количество потенциально не так информативных сообщений, которые займут место в базе данных. Вторая, по причине ограниченного количества строк анализируемых в секунду агент может отставать на часы от самых новых записей в журнале. Вполне вероятно, что вы захотите как можно быстрее быть информированным о текущей ситуации в файлах журналов вместо ковыряния часами старых записей.
Решение этих двух проблем является использование параметра ‘максзадержка’. Если параметр ‘maxdelay’ > 0, во время каждой проверки измеряются количество обработанных байт, количество оставшихся байт и время обработки. Отталкиваясь от этих значений, агент вычисляет оценочную задержку — как много секунд может потребоваться, чтобы проанализировать все оставшиеся записи в файле журнала.
Если задержка не превышает ‘максзадержка’, тогда агент поступает с анализом файла журнала как обычно.
Если задержка больше чем ‘максзадержка’, тогда агент игнорирует часть файла журнала, “перепрыгивая” эту часть к новой оценочной позиции таким образом, чтобы оставшиеся строки можно было проанализировать за ‘максзадержка’ секунд.
Обратите внимание, что агент даже не читает проигнорированные строки в буфер, но вычисляет приблизительную позицию для прыжка в файле.
Сам факт пропуска строк в файле журнала записывается в файл журнала агента, примерно следующим образом:
Количество “to byte” является оценочным, потому что после “прыжка” агент скорректирует позицию в файл к началу строки в журнале, которая может быть в файле чуть дальше или раньше.
В зависимости от того как скорость роста соотносится к скорости анализа файла журнала, вы можете не увидеть “прыжков”, а можете увидеть редкие или частые “прыжки”, большие или маленькие “прыжки”, или даже маленькие “прыжки” каждую проверку. Колебания загрузки системы и сетевые задержки также влияют на вычисления задержки и, следовательно, “прыжки” вперед чтобы не отставать от параметра “максзадержка”.
Не рекомендуется указывать ‘максзадержка’ logrt с опцией copytruncate подразумевает, что разные файлы журналов имеют разные записи (по крайней мере штампы времени в них отличаются), поэтому MD5 суммы начальных блоков (до первых 512 байт) будут отличаться. Два файла с одинаковыми MD5 суммами начальных блоков означают, что один из них оригинал, а второй — копия.
logrt с опцией copytruncate делает попытку правильной обработки копий файлов журналов без дублирующих сообщений. Тем не менее, такие варианты как создание нескольких копий файлов журналов с одинаковыми штампами времени, ротация файлов журналов чаще чем интервал обновления logrt[] элемента данных, частый перезапуск агента не рекомендуются. Агент пытается справиться со всеми этими ситуациями, но хорошие результаты не гарантируются при всех обстоятельствах.
Действия, если произошла ошибка связи между агентом и сервером
Каждая совпадающая строка с элементов данных log[] и logrt[] и результат проверки каждого элемента данных log.count[] и logrt.count[] требует свободный слот в выделенной 50% области буфера отправки в агенте. Элементы буфера регулярно отправляются серверу (или прокси) и слоты буфера становятся снова пустыми.
Пока имеются свободные слоты в выделенной области для журналов в буфере отправки в агенте и связь между агентом и сервером (или прокси) нарушена, результаты мониторинга журналов накапливаются в буфере отправки. Такое поведение позволяет смягчить кратковременные нарушения связи.
Во время длительных нарушений свящи все слоты журналов становятся занятыми и выполняются следующие действия:



