Отказоустойчивый кластер Hyper-V c хранилищем iSCSI на Windows Server 2016
В данной статье мы опишем развертывания кластера Hyper-V, на операционной системой ОС Windows 2016.
В примере рассмотрим вариант с двумя серверами, два сервера с ролью Hyper-V и один iSCSI.
Серверам кластера даем имена SRV-1 и SRV-2, хранилищу — iSCSI Storage.
На SRV-1 и SRV-2 устанавливаем роль Hyper-V и Failover Cluster.
 Добавляем роль Hyper-V
Добавляем роль Hyper-V- Добавляем компонент Failover Cluster
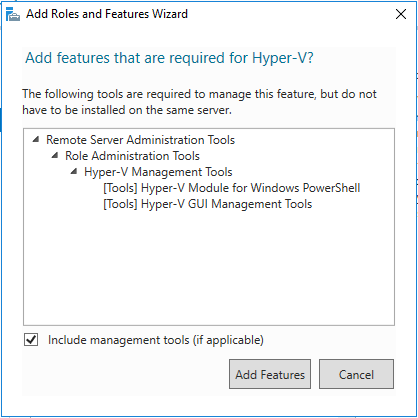 Добавляем роль Hyper-V
Добавляем роль Hyper-V Добавляем компонент Failover Cluster
Добавляем компонент Failover ClusterНа серверах SRV-1 и SRV-2 запускаем службу iSCSI Initiator.
Переходим на сервер iSCSI Storage. Из раздела File and iSCSI Services устанавливаем роль iSCSI Target Server.
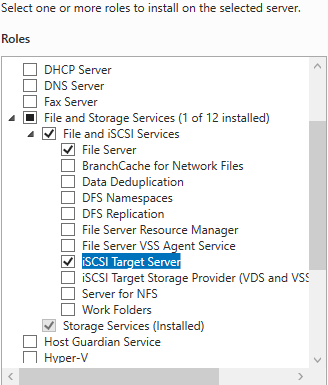 Добавляем роль iSCSI Target Server
Добавляем роль iSCSI Target Server
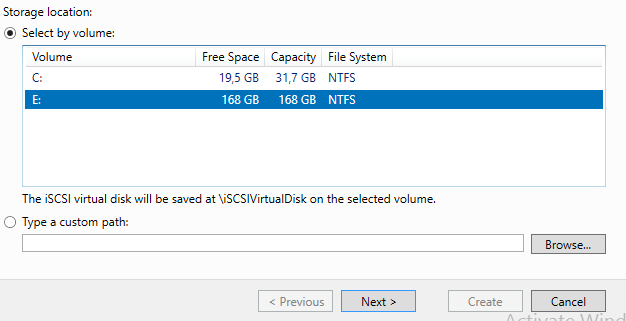
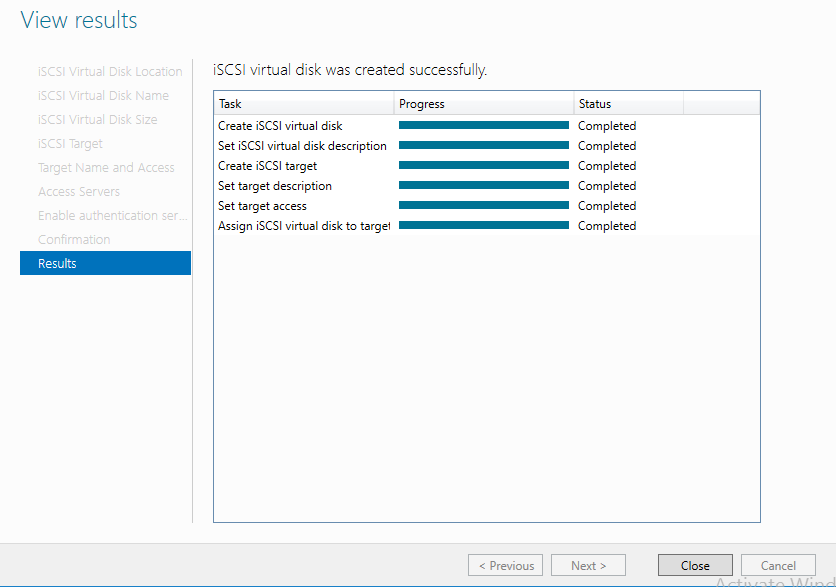
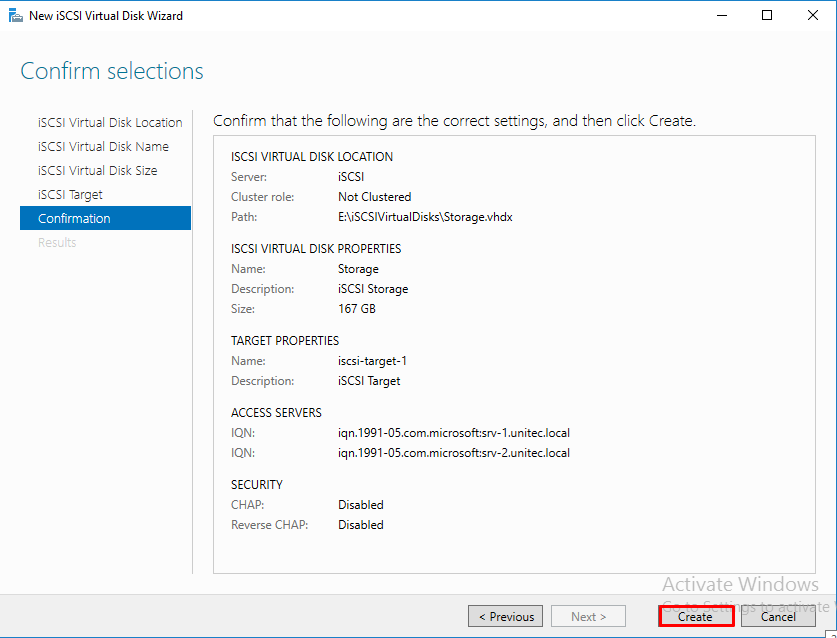
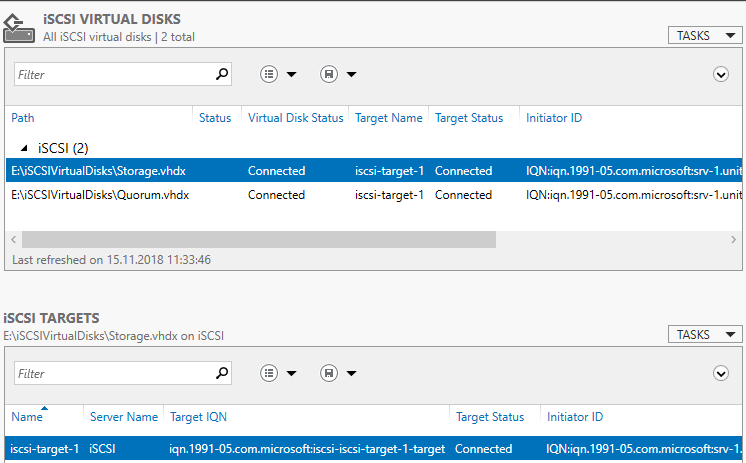
На сервере iSCSI Storage в Server Manager находим iSCSI и создаем 2 виртуальных диска.
Диск свидетеля кворума и диск для хранения виртуальных машин.
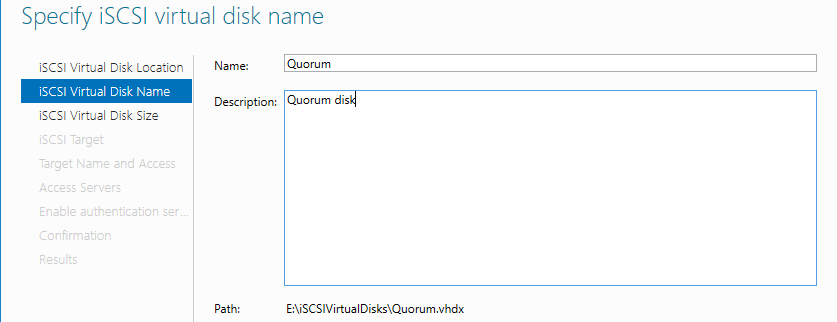
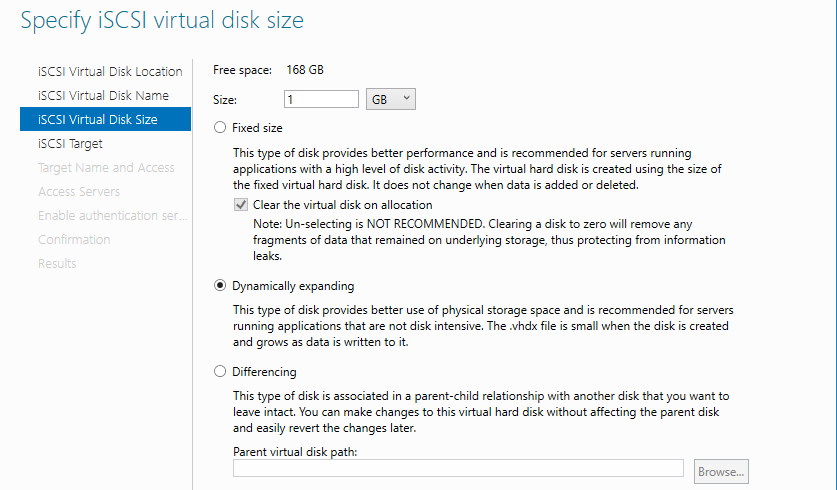
Диск-свидетель — это служебный ресурс кластера, для него достаточно выделить минимальный размер, в нашем случае 1ГБ. Даем ему название Quorum, диску для хранения виртуальных машин даем название — Storage и задаем соответствующий размер.

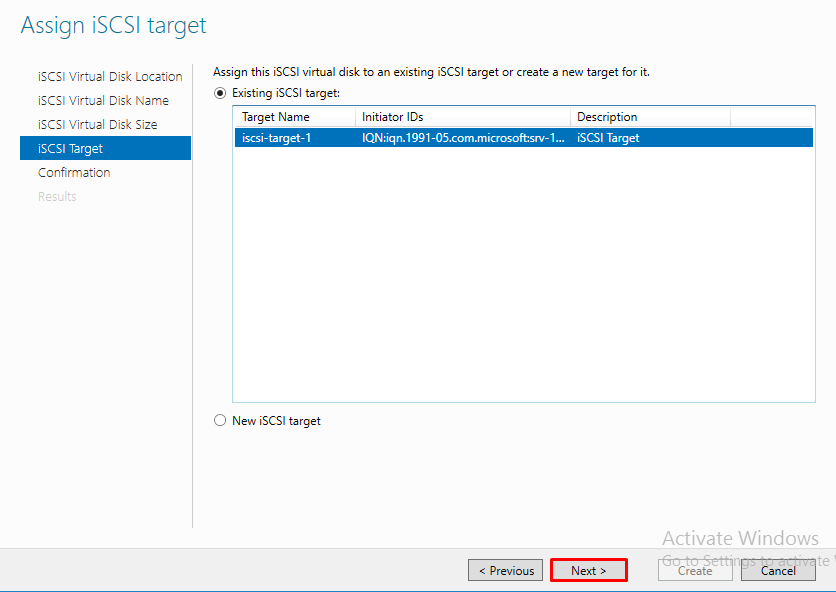
Создаем iSCSI таргет. Задаем имя iSCSI таргета.
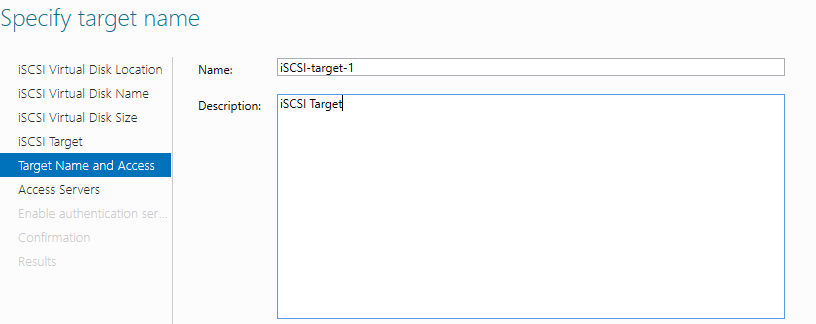
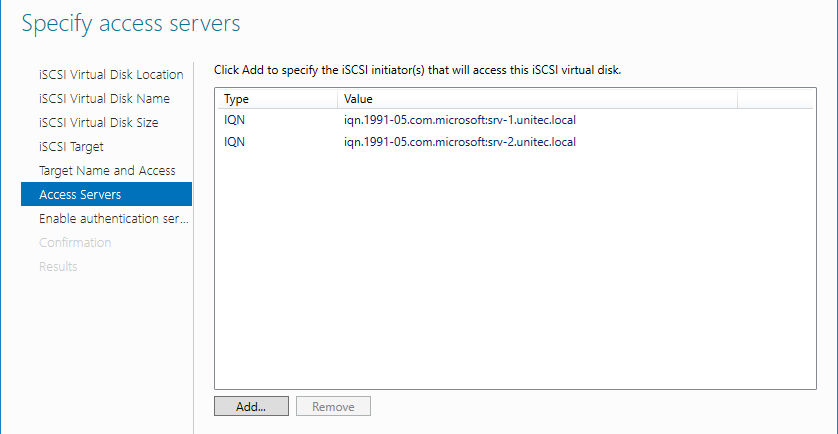
Добавляем сервера, которые могут подключаться к этим дискам (iSCSI инициаторы).
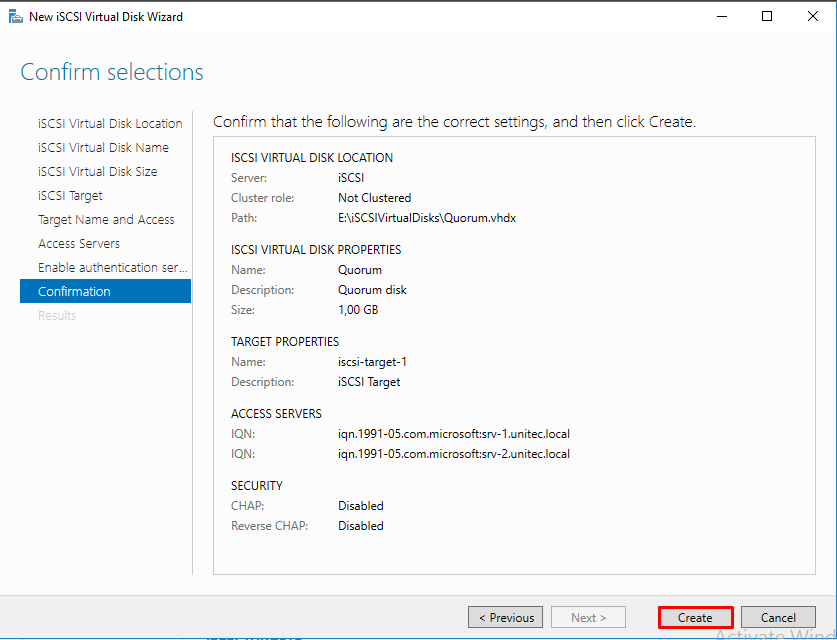
CHAP пропускаем.
Следующим шагом, создаем второй диск, называем его Storage и подключаем к уже созданному iSCSI таргет.
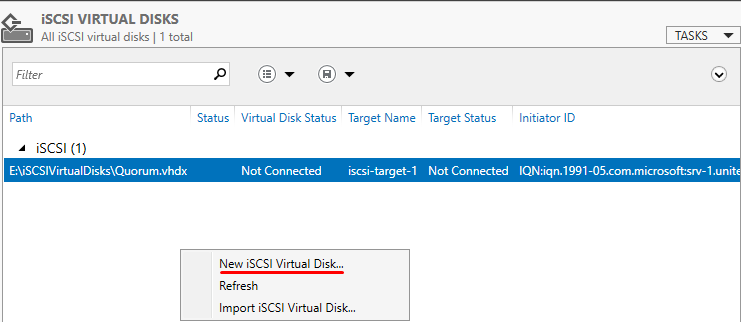

В Server Manager мы видим созданный таргет и инициаторы, но диски пока не подключены.
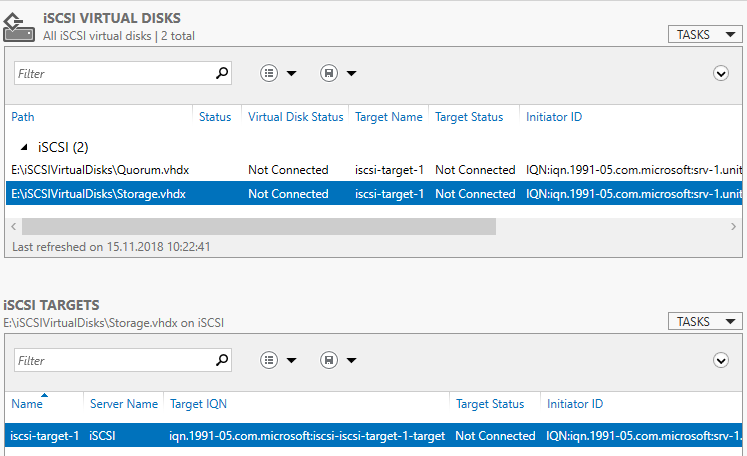
Возвращаемся на сервера SRV-1 и SRV-2.
Запускаем оснастку iSCSI Initiator. Добавляем таргет и подключаемся к нему.
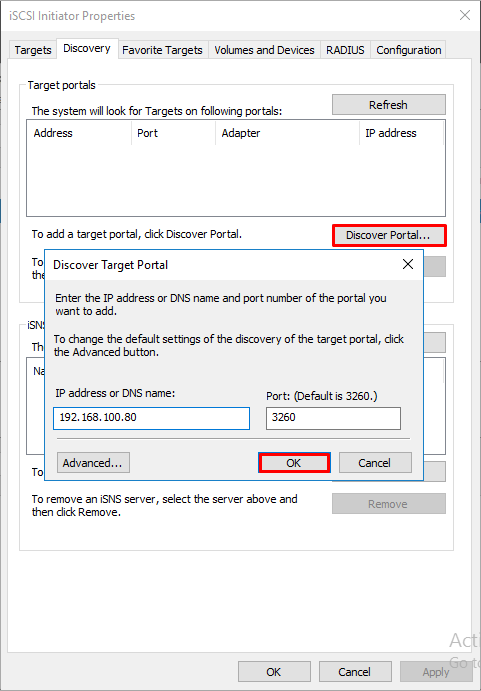


В Disk Management мы видим 2 новых диска. Инициализируем и форматируем новые диски. На втором сервере форматирование не нужно, только инициализация.
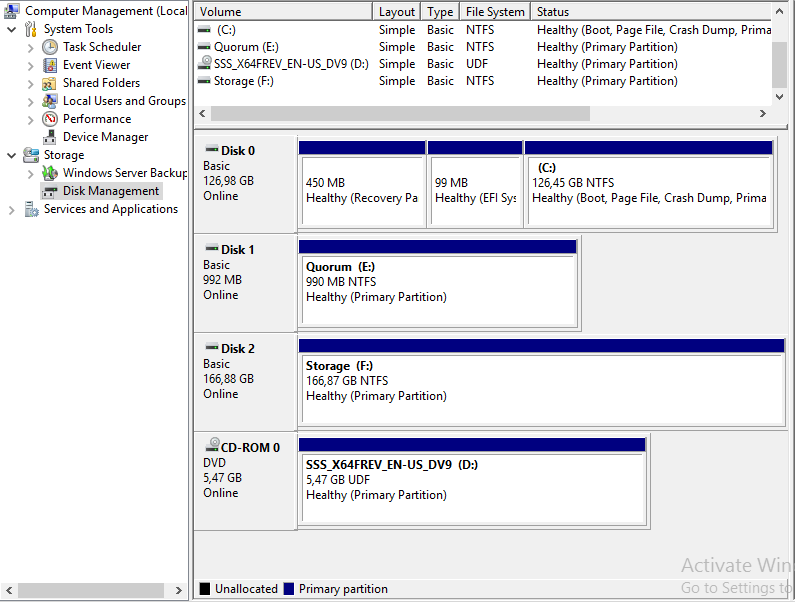
Здесь вернемся на сервер iSCSI Storage и убедимся, что все подключено.
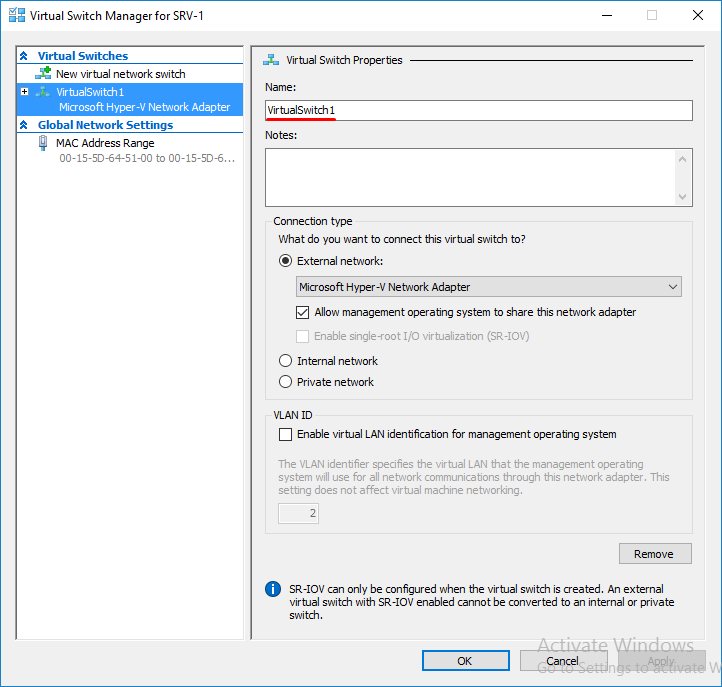
Переходим в диспетчер Hyper-V на серверах SRV-1 и SRV-2 и настраиваем виртуальный коммутатор. Обязательно даем одинаковое название коммутаторам на обоих серверах.
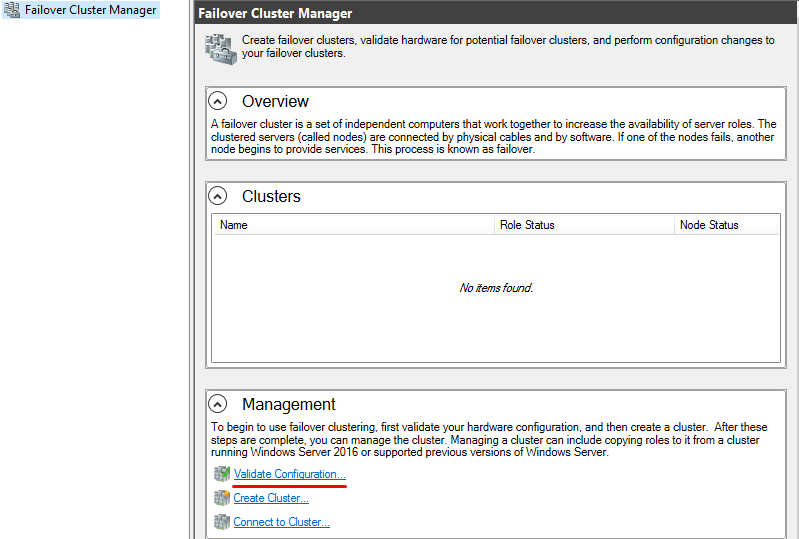
Открываем оснастку Failover Cluster Manager и приступаем к созданию кластера.
Вначале запускаем проверку. Если проверка не выдала ошибок, создаем кластер.

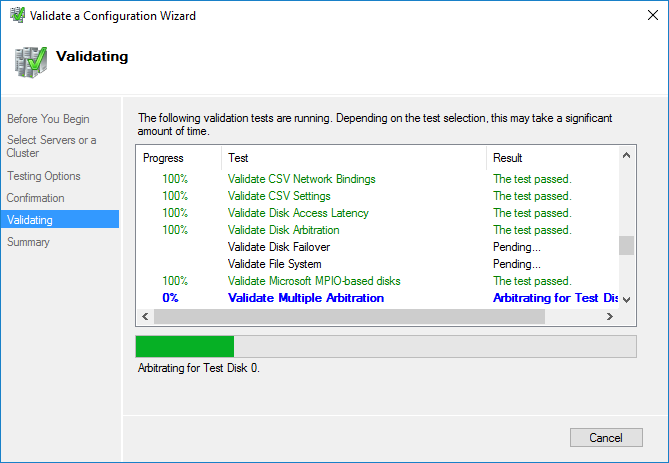
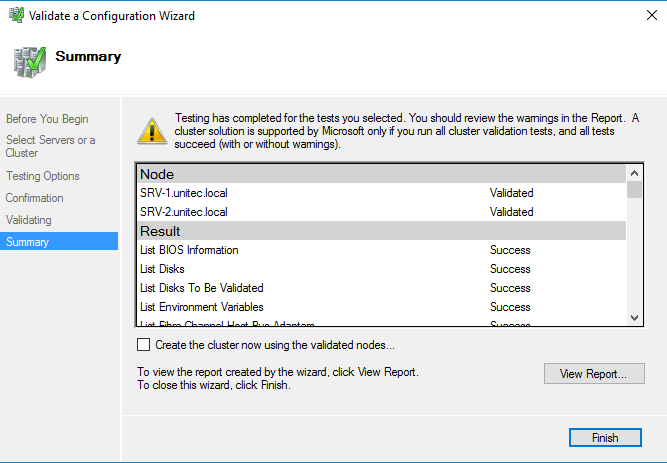
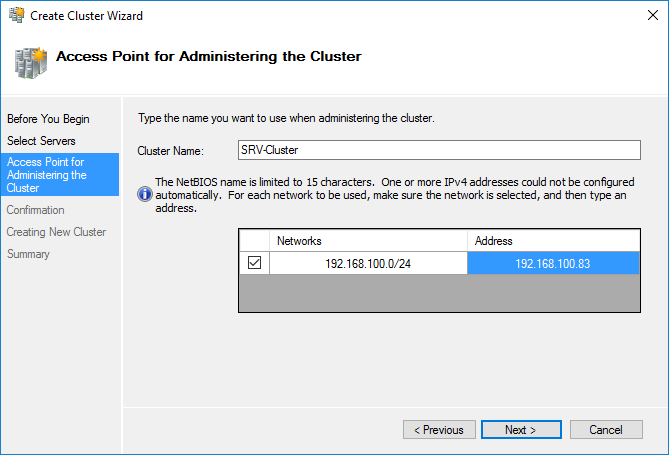
После проверки создаем кластер. При создании кластера для него создается виртуальный объект, которому даем имя и IP-адрес. В AD в том же OU, в котором находятся сервера появится новая машина.
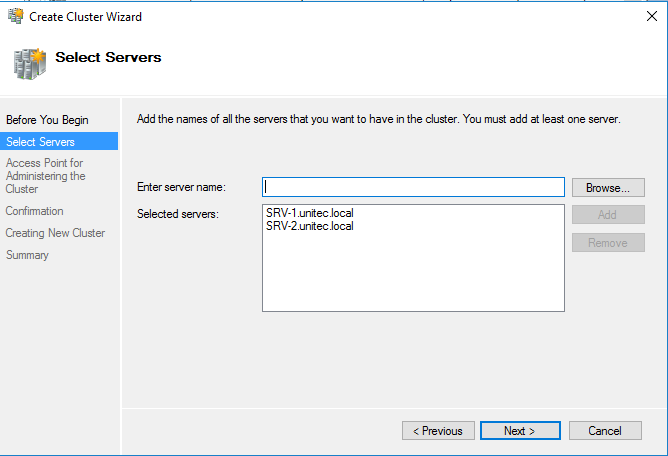
Добавляем диски.
В Failover Cluster Manager переходим в Storage -> Disk -> справа выбираем add Disk и добавляем диски.
Далее указываем Disk Quorum (диск-свидетель)

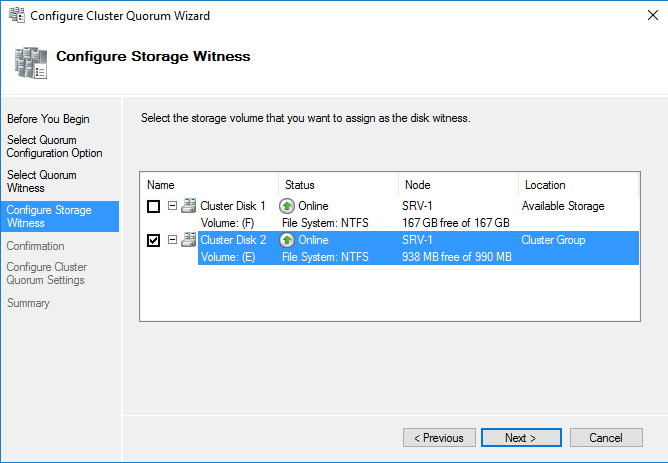
И добавляем Disk Storage в общие тома кластера.
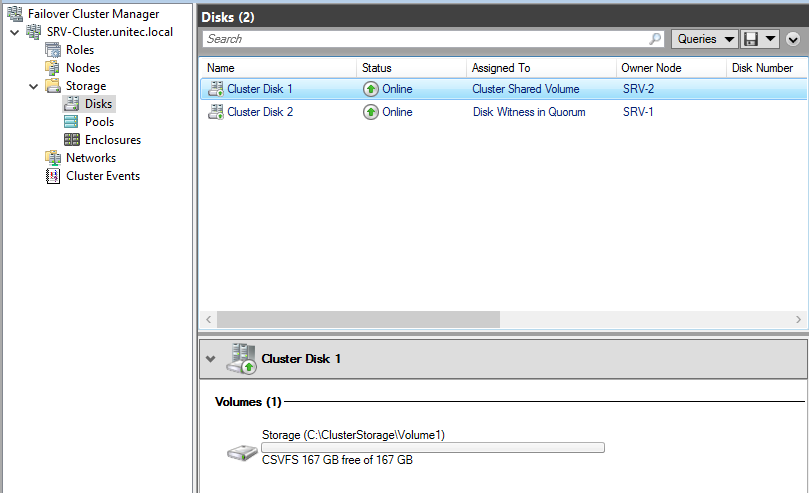
Для того, чтобы диск мог использоваться сразу несколькими участниками кластера на нем создается CSVFS — реализуемая поверх NTFS кластерная файловая система. Общие хранилища становятся доступны на всех узлах кластера на C:\ClusterStorage\VolumeN
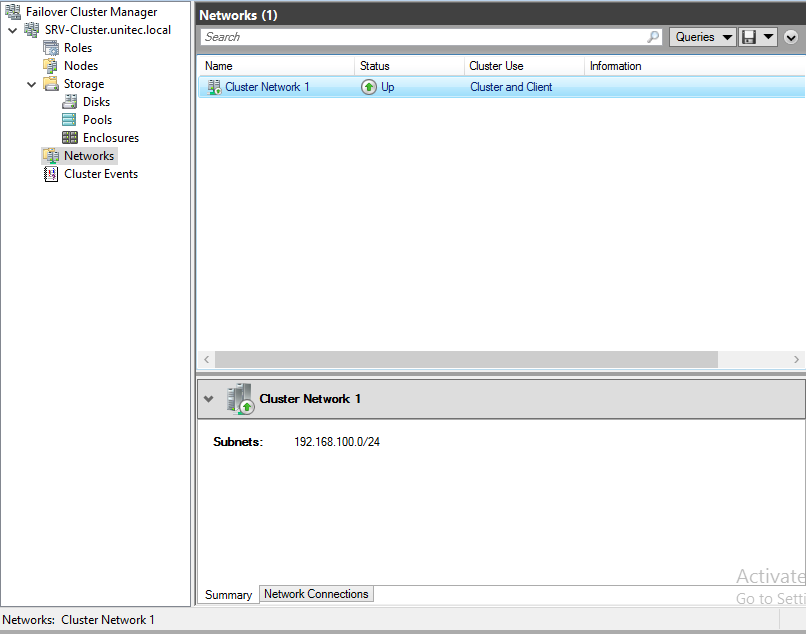
Настраиваем сеть
Перейдем к настройкам сети, для этого перейдем в раздел Networks. Для сети, которая подключена к сети предприятия указываем Разрешить кластеру использовать эту сеть и Разрешить клиентам подключаться через эту сеть. Для сети хранения данных просто оставим Разрешить кластеру использовать эту сеть, таким образом обеспечив необходимую избыточность сетевых соединений.
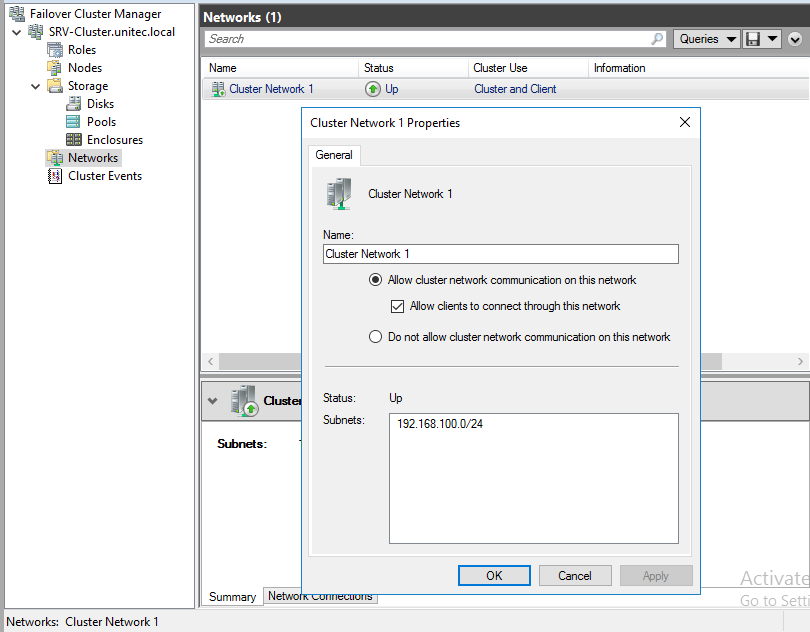
На этом настройка кластера окончена.
Теперь все виртуальные машины должны создаваться не в диспетчере Hyper-V, а в Failover Cluster Manager. Для создания новой машины заходим в Roles -> Virtual Machines -> New Virtual Machine. Выбираем узел, на котором будет находится машина.
В качестве расположения виртуальной машины обязательно укажите один из общих томов кластера C:\ClusterStorage\VolumeN.
В параметрах машины Automatic Start Action указываем Automatically Start и задержку старта, что бы избежать перегрузки системы.
В свойствах виртуальной машины (Properties) указываем предпочтительные узлы, в порядке убывания и настраиваем Failover (обработку отказов и восстановление размещения).
На этом настройка виртуальной машины закончена.
Проверяем миграцию виртуальной машины
Move -> Live Migration -> выбираем ноду.
Проанализируем созданный кластер с
BPA (Best Practices Analyzer, Анализатором наилучших решений).
Переходим в Server Manager -> Hyper-V -> справа Tasks -> Start BPA Scan.
Вот что показал мне тест.
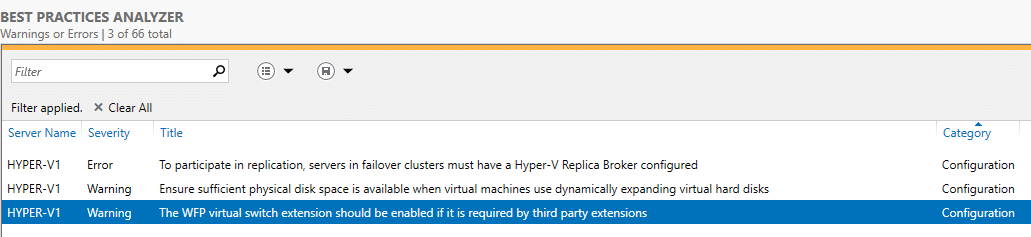
По первому пункту — у меня нет необходимости в создании реплики.
По второму пункту — считаю, что машины с динамическими дисками экономят место на диске и состояние диска с виртуальными машинами всегда можно посмотреть и предусмотреть расширение.
По третьему пункту — Расширение виртуального коммутатора WFP должно быть включено, если оно требуется сторонними расширениями.
Отказоустойчивая кластеризация в Windows Server Failover Clustering in Windows Server
Применяется к: Windows Server 2019, Windows Server 2016 Applies to: Windows Server 2019, Windows Server 2016
Отказоустойчивый кластер — это группа независимых компьютеров, которые работают совместно в целях повышения доступности и масштабируемости кластерных ролей (ранее называемых кластерными приложениями и службами). A failover cluster is a group of independent computers that work together to increase the availability and scalability of clustered roles (formerly called clustered applications and services). Кластерные серверы (называемые «узлы») соединены физическими кабелями и программным обеспечением. The clustered servers (called nodes) are connected by physical cables and by software. При сбое на одном из узлов кластера его функции немедленно передаются другим узлам (этот процесс называется отработкой отказа). If one or more of the cluster nodes fail, other nodes begin to provide service (a process known as failover). Кроме того, за кластерными ролями ведется профилактическое наблюдение, чтобы обеспечить их правильную работу. In addition, the clustered roles are proactively monitored to verify that they are working properly. Если они не работают, выполняется перезагрузка или перемещение на другой узел. If they are not working, they are restarted or moved to another node.
Отказоустойчивые кластеры также предоставляют функции общего тома кластера (CSV), которые образуют согласованное распределенное пространство имен, используемое кластерными ролями для доступа к общему хранилищу со всех узлов. Failover clusters also provide Cluster Shared Volume (CSV) functionality that provides a consistent, distributed namespace that clustered roles can use to access shared storage from all nodes. Благодаря функции отказоустойчивой кластеризации пользователи сталкиваются с минимальным количеством проблем в работе службы. With the Failover Clustering feature, users experience a minimum of disruptions in service.
Отказоустойчивая кластеризация имеет много возможностей практического применения, в том числе следующие: Failover Clustering has many practical applications, including:
Настройка растянутого кластера (stretch-cluster) на Windows server 2016
В данной статье мы рассмотрим как настроить отказоустойчивый растянутый кластер на базе Windows Server 2016.
В нашем сценарии кластер будет растянут между двумя дата центрами, при этом между хранилищами с помощью технологии storage replica будет настроена репликация данных.
Предположим у нас есть 2 сайта, в одном ДЦ у нас будет 2-е активные ноды кластера, в другом 2-е запасные, на случай отказа основного ДЦ.

Перед настройкой серверов убедимся что мы соблюдаем следующие условия:
Используется лес доменных служб Active Directory (использовать Windows Server2016 не обязательно).
Есть минимум два сервера с установленным выпуском Windows Server2016 Datacenter.
Имеется два набора общего хранилища, использующие SAS JBOD , сеть SAN стандарта Fibre Channel, общие VHDX-файлы или цель iSCSI.
Хранилище должно содержать жесткий диск и твердотельный накопитель, а также поддерживать постоянное резервирование.
Доступ к каждому набору хранилищ нужно предоставить только для двух серверов (асимметричная конфигурация).
Каждый набор хранилищ должен допускать создание по меньшей мере двух виртуальных дисков: один для реплицируемых данных и один для журналов.
На всех дисках данных в физическом хранилище необходимо использовать одинаковый размер секторов. На всех дисках с журналами в физическом хранилище необходимо использовать одинаковый размер секторов.
На каждом сервере должно быть создано по меньшей мере одно подключение 1Гбит Ethernet для синхронной репликации, но желательно использовать RDMA.
Правила всех задействованных брандмауэров и маршрутизаторов должны разрешать двунаправленный трафик ICMP, SMB (порт 445, а также 5445 для SMB Direct) и WS-MAN (порт 5985) между всеми узлами.
Сеть между серверами должна иметь достаточную пропускную способность для ваших рабочих нагрузок ввода-вывода, а средняя задержка приема-передачи должна составлять 5мс для синхронной репликации.
Для асинхронной репликации рекомендации по задержке приема и передачи отсутствуют.
При настройке я буду использовать следующие сервера расположенные в 2-х разных ДЦ (LA и Mexico)
Site Mexico:
m-srv-cl2
m-srv-cl1
Site LA:
l-srv-cl1
l-srv-cl2
Редакция Windows Server должна быть Datacenter Edition, если у вас редакция Standard выполните следующий Powershell скрипт:
Далее после установки правильной редакции , установите необходимые роли и фичи следующим скриптом:
После установки ролей Storage-Replica,Failover-Clustering,FS-FileServer перейдем к настройке дисков.
Подключите общее хранилище к каждому серверу внутри одного ДЦ
Соблюдайте следующие требования:
Необходимо создать два тома на каждой полке: один для данных и один для журналов.
Диски журналов и данных следует инициализировать как GPT, а не MBR.
Два тома данных должны иметь одинаковый размер.
Два тома журналов должны иметь одинаковый размер.
Все реплицируемые диски данных должны иметь одинаковый размер сектора.
Все диски журналов должны иметь одинаковый размер сектора.
Тома журналов должны использовать хранилище на базе флэш-памяти и параметры устойчивости, обеспечивающие высокую производительность.
Майкрософт рекомендует, чтобы хранилище журналов работало так же быстро или быстрее, чем хранилище данных.
Томы журнала никогда не должны использоваться для других задач.
В качестве дисков данных можно использовать жесткие диски, твердотельные накопители или их многоуровневое сочетание.
Диски можно организовать как зеркальные массивы, массивы с контролем четности, RAID1 или 10, RAID5 или RAID50.
Том журнала должен иметь размер по умолчанию не менее 9ГБ, но может отличаться как в большую, так и в меньшую сторону в зависимости от требований к ведению журнала.
Тома должны форматироваться с помощью файловой системы NTFS или ReFS.
Роль файлового сервера необходима только для работы Test-SRTopology, так как она открывает порты брандмауэра, необходимые для тестирования.
Для дисковых полок JBOD:
Убедитесь, что каждый набор узлов в парах серверов может видеть только дисковые полки своего сайта (асимметричное хранилище) и что подключения SAS правильно настроены.
Для хранилища iSCSI:
Убедитесь, что каждый набор узлов в парах серверов может видеть только дисковые полки своего сайта (асимметричное хранилище). При работе с iSCSI следует использовать несколько сетевых адаптеров.
Для хранилища Fibre Channel в сети SAN:
Убедитесь, что каждый набор узлов в парах серверов может видеть только дисковые полки своего сайта (асимметричное хранилище) и что правильно выбраны зоны узлов.
Подготовьте хранилище в соответствии с документацией поставщика.
Теперь зайдем на сервера в каждом ДЦ и по аналогии настроим общие диски, открываем консоль управления дисками и начинаем
Переводим диск в online


Инициализируем диск как GPT, это обязательное требование

Создаем новый раздел

Не назначаем букву диску

Форматируем диск в NTFS и задаем ему Label

Проделываем тоже самое на втором диске для логов.
Запускаем консоль cluadmin.msc и создаем новый кластер

Добавляем наши узлы кластера

Запускаем тестирование кластера и дожидаемся окончания проверки


Вводим имя кластера и подключаем доступные хранилища


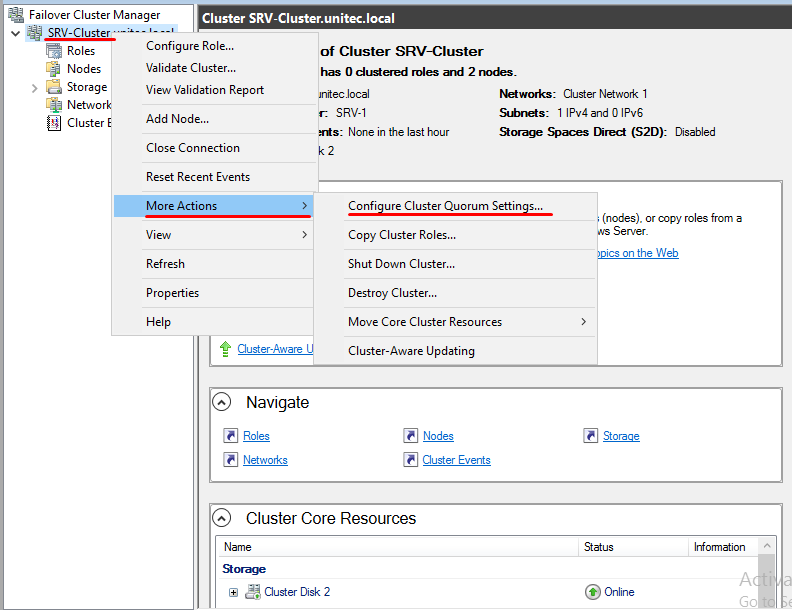
Перейдем к настройке кворума

Выбираем quorum witness

В качестве кворума будем использовать сетевую шару

Далее просто укажите сетевой путь к шаре и завершите работу мастера.



