- The OCR Software Blog
- Tesseract OCR Software GUI
- How to get started:
- Tips for better recognition results:
- How to add more languages
- Tesseract
- Содержание
- Графические оболочки (GUI)
- GImageReader
- tessdoc
- Tesseract documentation
- GUIs and Other Projects using Tesseract OCR
- 1. GUIs
- 2. Online OCR services
- 3. Mobile
- 4. Others (Utilities, Tools, Command-Line Interfaces [CLI], etc)
- A. PDF to Searchable PDF tools
- B. Others:
- IMPACT related
The OCR Software Blog
Updates on OCR and Cloud vision.
Tesseract OCR Software GUI
Welcome to the official home page for the (a9t9) Free OCR for Windows Desktop В tool.В As the name suggests, it extracts text from image files and PDF items. It uses the open-source Tesseract OCR engine from HP/Google for OCR processing.
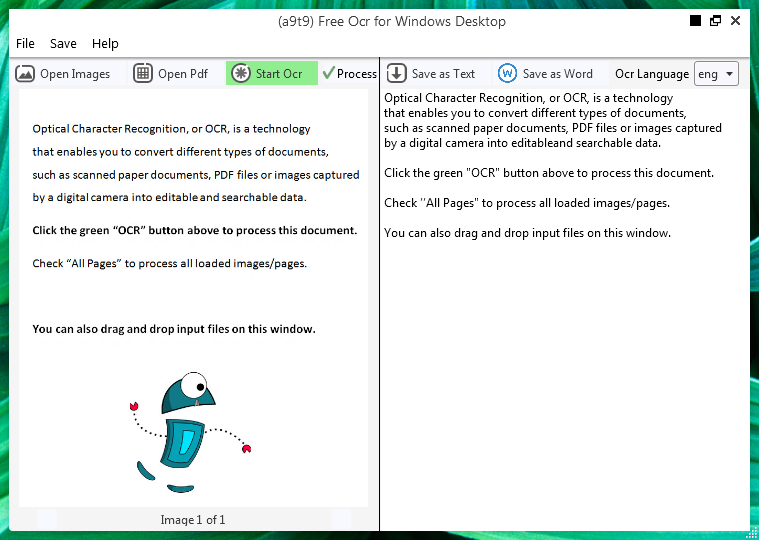 TScreenshot of (a9t9) Free OCR for Windows Desktop — a modern open source Tesseract GUI
TScreenshot of (a9t9) Free OCR for Windows Desktop — a modern open source Tesseract GUI
Why useВ (a9t9) Free OCR for Windows Desktop?
- The application is simple to install/uninstall, and very easy to use
- Free to use
- 100% adware and spyware free
- Uses the well-known Tesseract OCR engine (so essentially it is a modern Tesseract GUI)
- You can improve and customize it — it is open source (GPL)
В If you have not done it yet, download the installer here:
30MB, runs on Win 7 and higher)
 The OCR software includes full PDF support (powered by Ghostscript).
The OCR software includes full PDF support (powered by Ghostscript).
How to get started:
You can open an image or PDF file. The content of the source file will be displayed in the left window. If your document has more than one page, or if you opened multi-page documents, use the arrows at the bottom to navigate between them,
You start the OCR by clicking the green Start Ocr , and you will see the result in the right window. Output text can be saved as a text file or Word document.
Unfortunately the conversion quality is not so great. Behind the scene it uses the Tesseract open-source OCR engine. Its quality varies from language to language — so go ahead and test if it is sufficient for your needs.
Tips for better recognition results:
Tesseract’s output will be very poor quality if the input images are not preprocessed to suit it:
- Images (especially screenshots) must be scaled up such that the text height is at least 20 pixels.
- Any rotation or skew must be corrected or no text will be recognized,
- Dark borders must be manually removed, or they will be misinterpreted as characters.
Still need better text recognition results? Then try these new alternatives:
1. Online OCR — our free web-based OCR app. 2. OCR API — our free web API**, includes OCR command line examples with cURL.
3. Windows 8 OCR software — our free, open-source (GPL) Windows Store OCR app.
Both new services use a different OCR component and have much better text recognition rates than the Tesseract-based OCR desktop software on this page.
For software developers and geeks:
The (a9t9)В Free OCR for Windows Desktop tool is a graphical user interface front-end (GUI) for the Tesseract engine. It isВ written in C#/WPF and the full source code is available as ready-to-compile Microsoft Visual Studio 2013 projectВ on GitHubВ under the GPL V2 open source license. В Feedback of all kind is welcome, especially ideas on how to improve the OCR quality. In theВ Best OCR Software review on this blog the mediocre OCR performance of Tesseract was on of the Five OCR surprisesВ of this test.
How to add more languages
One of the key advantages of the Tessearct engine is the wide variety of supported В OCR languages — it even includes Esperanto! The (a9t9) Free OCR for Windows Desktop installer includes English (ENG), Spanish (SPA) and German (GER). To add more languages just follow these three steps:
- Download the language file you need from Google code, for example Chinese (Traditional).
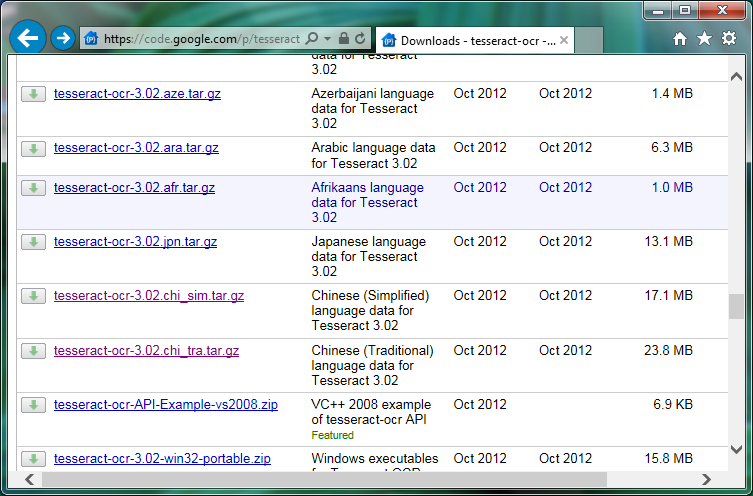 TTesseract language download section
TTesseract language download section
- Un”zip” the download (first the .gz file, and then the .tar file inside). If you have no software to manage compressed archives yet, get free 7zip tool. It is a great choice.
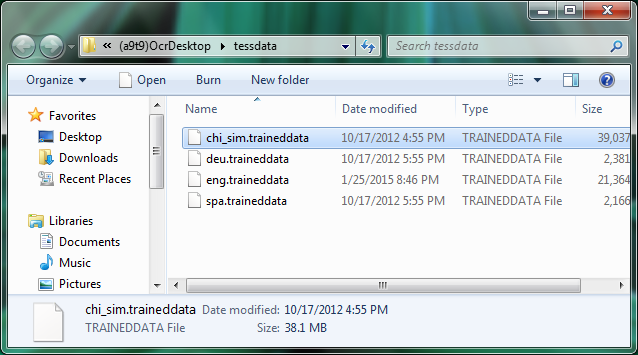 Example: Adding Simplified Chinese as OCR language to the /tessdata folder
Example: Adding Simplified Chinese as OCR language to the /tessdata folder
- Copy the files into the tessdata language folder on your PC. You find that folder easily by opening it from inside the application. In the menu of the OCR software go to the Help > Open Language Folder — and a new Explorer window opens.
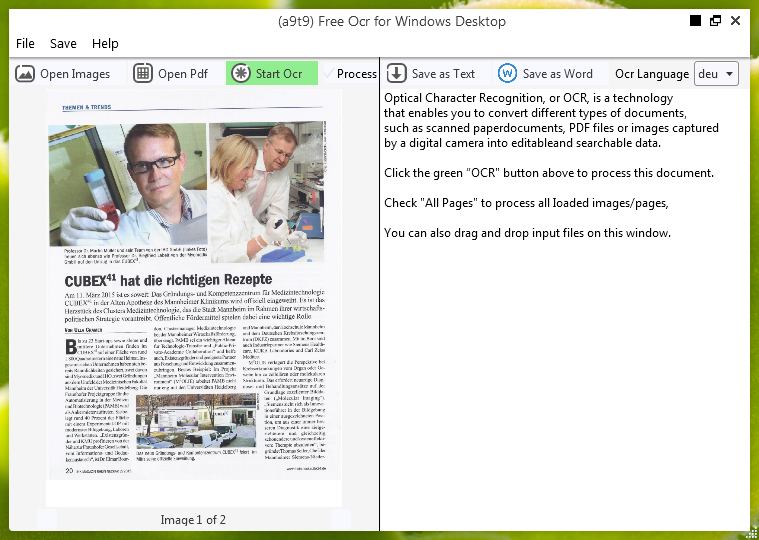
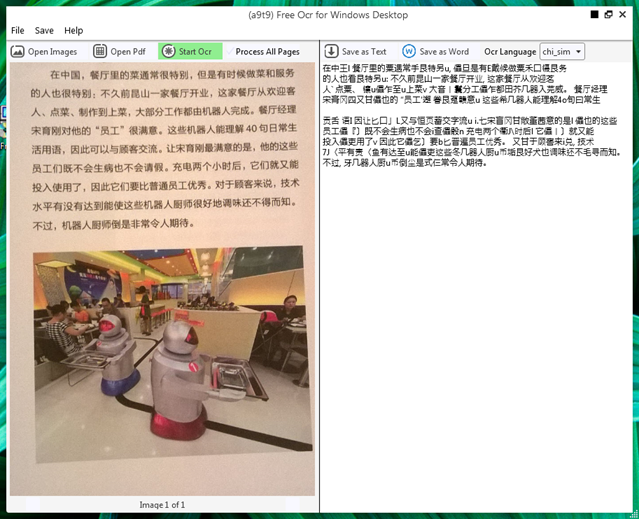 (a9t9) Free OCR for Windows Desktop ocr’ing a mobile phone image of a Chinese magazine article.
(a9t9) Free OCR for Windows Desktop ocr’ing a mobile phone image of a Chinese magazine article.
The Tesseract OCR results are mediocre, but still better than transcribing the text yourself
Now start the software again and the new language appears in the OCR language selection drop down as abbreviated code, e. g. ENG for English, SPA for Spanish, GER for German, POR for Portugese , CHI_TRA for traditional Chinese character support or CHI_SIM for simplified Chinese character support.
Tesseract
 | Эта статья находится в процессе написания. Если вы считаете, что её стоило бы доработать как можно быстрее, пожалуйста, скажите об этом. |
Tesseract — свободная программа для распознавания текстов, разрабатывавшаяся Hewlett-Packard с середины 1980-х по середину 1990-х, а затем 10 лет «пролежавшая на полке». Не так давно (в августе 2006 г) Google купил её и открыл исходные тексты под лицензией Apache 2.0 [1] для продолжения разработки. В настоящий момент программа уже работает с UTF-8, поддержка языков (включая русский с версии 3.0 [2] [3] ) осуществляется с помощью дополнительных модулей [4] .
Содержание
Графические оболочки (GUI)
GImageReader


Кросплатформенный графический интерфейс (GUI) для консольного движка распознавания текста tesseract [4] . Для использования следует:
- Скачать и установить tesseract для windows из репозитория google http://code.google.com
- Скачать и установить графический интерфейс gImageReader из репзитория http://sourceforge.net/
- Опционально можно добавить в программу русский словарь из OpenOffice, скачав его по ссылке openoffice wiki http://wiki.services.openoffice.org и распаковав его в папку %Program Files%\gimagereader\share\myspell\dicts
Распознает нормально, но не чистит от мусора и не форматирует полученный текст.
tessdoc
Tesseract documentation
GUIs and Other Projects using Tesseract OCR
1. GUIs
| Name | Linux | Mac | Windows | License | Description |
|---|---|---|---|---|---|
| normcap | X | X | X | GPL v3 | OCR powered screen-capture tool to capture information instead of images. |
| gImageReader | X | X | GPL v3 | A graphical GTK frontend to tesseract-ocr | |
| TesseractStudio.Net | X | Proprietary | A graphical interface to tesseract 4.0 | ||
| VietOCR | X | X | X | Apache 2.0 | A GUI frontend for Tesseract OCR engine. Supports optical character recognition for Vietnamese and other languages supported by Tesseract |
| NeOCR | X | Freeware | A GUI frontend for Tesseract 4.0 OCR engine. | ||
| Free-Ocr-Windows-Desktop | X | GNU AGPL v3 | Free OCR application for the Windows Desktop — Essentially a graphical user interface (GUI) for the Tesseract OCR engine. The application also includes support for reading and scanned PDF files | ||
| YAGF | X | GPL v3 | A graphical front-end for cuneiform and tesseract | ||
| OCR2Text | X | X | X | MIT | CLI tool for batch-processing PDF to TXT |
| OCRFeeder | X | GPL v3 | OCRFeeder is a document layout analysis and optical character recognition system | ||
| Lector | X | X | GPL v2 | A graphical ocr solution for GNU/Linux based on Python, Qt4 and Tesseract OCR | |
| Tesseract-OCR QT4 gui | X | Apache 2.0 | Tesseract-OCR QT4 gui is a simple GUI for tesseract | ||
| Lime OCR | X | GPL v3 | A simple, free OCR software for Windows using tesseract-ocr engine | ||
| Ocrivist | X | GPL v3 | Ocrivist is a utility which makes it possible to scan and OCR books and other printed documents to PDF or Djvu format | ||
| Tesseract-GUI | X | GPL v2 | Tessract-GUI is not a front-end for tesseract-ocr, it is just a graphical way to use it with simple image manipulation through ImageMagick | ||
| QTesseract | X | LGPL v3 | QT GUI for the Tesseract OCR | ||
| dpScreenOCR | X | X | zlib | Program to recognize text on screen | |
| pmOCR | X | BSD | Batch OCR tool, also file monitor event OCR with tesseract | ||
| tesseract4java | X | X | X | GPLv3 | A cross-platform GUI for training and running Tesseract with advanced features like batch recognition and accuracy evaluation |
| Linux-Intelligent-OCR-Solution(lios) | X | GPLv3 | A GUI for scanning, running and training Tesseract with total accessibility for visually impaired and advanced features like Scanner Brightness optimizer, Text-Cleaner, etc | ||
| SunnyPage OCR | X | Proprietary | A GUI frontend for Tesseract OCR engine with automatic adjustment of image brightness, image processing and PDF support. | ||
| PDF OCR X | X | X | Proprietary | PDF OCR is a simple drag-and-drop utility for Mac OS X and Windows, that converts your PDFs and images into text documents or searchable PDF files | |
| TaxWorkFlow | X | Proprietary | TaxWorkFlow is an accounting practice management application that includes GUI frontend for Tesseract OCR engine. The app supports AVX and allows to create OCR’ed PDF files of selected resolution and compression from PDF files and 100+ image file formats. | ||
| AmhOCR | X | GPLv3 | Tesseract Powered Windows Desktop OCR Application With Multiple Pre/Post Processing GUI |
2. Online OCR services
- OCR.net: Powered by PDF OCR X in back-end. Converts PDFs and Images to Text or searchable PDF.
- WeOCR: is a platform for Web-enabled OCR (Optical Character Reader/Recognition) systems that enables people to use character recognition over networks
- CustomOCR
- Free OCR
- i2OCR
- Indic-OCR OCR Service An online OCR service for Indian languages
3. Mobile
- Android:
- tess-two — A fork of Tesseract Tools for Android tesseract-android-tools that adds some additional functions.
- Tesseract4Android — A fork of tess-two rewritten from scratch to support latest version of Tesseract OCR.
- textfairy Android OCR App with source code at github.com
- Character Recognition Android OCR App with source code at gitorious.org
- tesseract-android-tools: set of Android APIs (archived in Google Code Archive at 2013-01-28)
- Mobile OCR: The goal of Mobile OCR is to create an application for the Android platform that will recognize text from an image taken by the phone’s camera. The application will be fully accessible to low vision and blind users
- Across India: An app which lets users take pictures of sign boards in Indian Languages or English and transliterate it to the language that they can read.
- iOS:
- Tesseract-OCR-iOS — Tesseract OCR iOS is a Framework for iOS7+, compiled also for armv7s and arm64.
- OCR-iOS-Example — a simple example of how to do optical character recognition (OCR) on iOS.
- Tesseract-iPhone-Demo — example based on tesseract 2.04.
- More OS:
- ScanBizCards: Mobile solution for business card scanning. Requirements: iPhone 4/iPhone 3/Android 2.0
- macOS:
- Tesseract macOS — Tesseract OCR framework for macOS, supporting both Objective C and swift. Compiled for both x86 and arm64.
4. Others (Utilities, Tools, Command-Line Interfaces [CLI], etc)
A. PDF to Searchable PDF tools
(ie: any tool which can also handle a non-searchable PDF as an input):
- OCRmyPDF — Adds OCR text layer to scanned PDF files and images, allowing them to be searched. Processes pages in parallel on multi-core CPUs. Keeps exact resolution of original embedded images without recompressing JPEGs, when possible. Includes image several preprocessing options, detailed documentation, and support for many exotic PDFs.
- pdf2pdfocr is a tool to OCR a PDF (or supported images) and add a text layer in the original file making it a searchable PDF. It is a python script that uses tesseract and other open source tools. Linux, macOS and Windows supported.
- pdf2searchablepdf — a tool which allows converting any non-searchable PDF, OR any entire directory of images, to a searchable PDF
B. Others:
- ocr-fileformat — Validate and transform between OCR file formats (hOCR, ALTO, PAGE, FineReader)
- Tess4J — A Java JNA wrapper for Tesseract OCR API.
- Traineddata inspector — to inspect some of the internals of traineddata files
- TopOCR — high Quality OCR for Cameras with tesseract-ocr support (paid product)
- Simple OCR Web Server using python, flask, tesseract-ocr, and leptonica
- Display OCR is OpenCV-Python + python-tesseract real-time image preprocess and OCR of 7 segments font.
- OpenOCR makes it simple to host your own OCR REST API.
- https://github.com/guitarmind/tesseract-web-service is An implementation of RESTful web service for tesseract-OCR using tornado
- RasterEdge .NET Image SDK — OCR Recognition is robust, high-performance recognition application of royalty-free distribution for desktop or server applications.
- DevScope OCR SDK is an Optical Character Recognition toolkit engine based on Tesseract OCR v3 that allows to develop applications using Microsoft .NET framework
- Paperwork — using OCR to grep dead trees the easy way (requires pyocr)
- Aletheia — An Advanced Document Layout and Text Ground-Truthing System for Production Environments
- gscan2pdf a GUI to produce PDFs or DjVus from scanned documents
- Audiveris is an open-source Optical Music Recognition software which processes the image of a music sheet to automatically provide symbolic music information in MusicXML standard.
- Ocrivist is a utility which makes it possible to scan and OCR books and other printed documents to PDF or Djvu format.
- thu-ipv6-login a python script for IPv6 authentication in Tsinghua University with support for OCR of authcode
- Wolfram Mathematica 9.0 use tesseract for recognizing text
- node-dv is a node.js library for processing and understanding scanned documents
- hocr-tools — python tools for manipulating and evaluating the hOCR format for representing multi-lingual OCR results by embedding them into HTML. They include hocr-pdf tool for creating searchable pdf.
- PyPDFOCR — Tesseract-OCR based PDF filing
- ChronoScan is a complete suite for document Scanning & Data Entry
- speedy-ocr utility to simplify scanning and OCR focus to help blind and visually impaired community. It is part of Vinux project.
- Project VIRAL Varico Invoice Recognition with Assisted Learning
- Bindery: A simple GUI for binding post processed scanned pages into digital documents
- Clarify: Clarify helps you OCR ‘image-only’ PDFs. Your input is a PDF that you normally cannot extract text from. The output is text. Clarify is a python module that wraps up tesseract-ocr, xpdf and netpbm. Requirements: python, tesseract-ocr, xpdf, netpbm
- hOcr2Pdf.NET: hOcr2Pdf.NET is a library that programmers can use to create highly compressed, searchable pdf’s for applications. Requirements: .NET 2.0 or higher, Tesseract 3.0, JBig2.exe
- PDFBeads: convert scanned images to a single searchable PDF file based on hOCR files. Requirements: ruby, RMagick, hpricot
- ExactImage/hocr2pdf: creates a Searchable PDF from hOCR input. Requirements: libagg
- HocrConverter: creates PDFs and plain text from hOCR documents. Requirements: python, reportlab
- HocrToPdf.java: java source for very basic hOCR to PDF converter. Compiled version can be found at project modi2hocr. Requirements: java, jericho, iText2
- hOcr2Pdf.NET: is a .NET library to convert .hocr html produced by Tesseract or Cuneiform into searchable pdfs using HtmlAgilityPack and iTextSharp. Requirements: C#.
- Tally-Ho: Tally-Ho is a screen reader intended for sites like google books
- Mayan EDMS: Document management system with tesseract as its base
- Olena: a generic and efficient image processing platform (tesseract is used in its part called scribo)
- ocrodjvu is a wrapper for OCR systems, that allows you to perform OCR on DjVu files
- PaRADIIT (Pattern Redundancy Analysis for Document Image Indexation & Transcription) is a project initiated and sponsored by 2 successive Google DH awards. It aims to turn ancient books, especially from the Renaissance, into accessible digital libraries.
- The ISRI Analytic Tools consist of 17 tools for measuring the performance of and experimenting with OCR output.
- Indic Messenger A Facebook chat bot which can OCR images containing Indian/English text and transliterate it to other Indian scripts.
- LibreOCR A LibreOffice extension which can convert an image to OCT and open in the Writer application.
IMPACT related
- IMPACT project
- IMPACT Centre — a not-for-profit organisation founded to sustain IMPACT outcomes and foster community building
- IMPACT data
- IMPACT tools
- Results of the IMPACT project by PSNC Digital Libraries Team
- Virtual Transcription Laboratory by PSNC
- IMPACT Interoperability Framework — interoperability layer supporting the loose coupling of software components developed during the IMPACT project.
- Inventory-Extraction-Tool Prototype is a prototype with graphical user interface (GUI) that allows for the extraction of a complete list of characters from a document, without reference to a specific language dictionary or a library of fonts.
- Post Correction Tool is interactive post-correction of OCRed documents. Using the information obtained by the Text and Error Profiler the whole correction process is adaptive to the document being processed. In this way, usually huge numbers of systematic errors can be corrected with just a few keystrokes..
- OCR evaluation tool.
- BlackLab is a corpus retrieval engine built on top of Apache Lucene. It allows fast, complex searches with accurate hit highlighting on large, tagged and annotated, bodies of text. It was developed at the Institute of Dutch Lexicology (INL) to provide a fast and feature-rich search interface on our historical and contemporary text corpora.
tessdoc is maintained by tesseract-ocr. This page was generated by GitHub Pages.



