- Команда sort в Linux
- Синтаксис
- Опции
- Вывод результатов в файл
- Вывод результатов в обратном порядке
- Сортировка по заданным полям
- Удаление дублирующих записей
- Проверка сортировки
- Заключение
- SORT command in Linux/Unix with examples
- Команда sort в Linux с примерами
- Сохранить результат в другом файле
- Сортировка по номеру столбца
- Проверьте отсортированное состояние файла
- Отсортированные данные
- Удалить повторяющиеся элементы
- Сортировка с помощью конвейера в команде
- Случайная сортировка
- Сортировка данных из нескольких файлов
- Сортировать с присоединением
- Сравнить файлы с помощью сортировки
- Заключение
Команда sort в Linux
sort – простая и очень полезная команда, которая меняет порядок строк в текстовом файле, то есть осуществляет их сортировку по алфавиту или в соответствии с числовыми значениями. По умолчанию правила сортировки следующие:
- строки, начинающиеся с цифр, выводятся раньше строк, начинающихся с букв;
- строки, начинающиеся с букв, выводятся в алфавитном порядке;
- строки, начинающиеся со строчных букв, выводятся раньше строк, начинающихся с таких же заглавных.
Правила сортировки можно изменять при помощи опций. Мы рассмотрим их ниже.
Синтаксис
Основной синтаксис команды следующий
Команда также может быть использована в составе конвейеров (пайпов). Например
Опции
Как видим, сейчас строки выводятся в том же порядке как и были записаны. Для его сортировки в алфавитном порядке выполните команду:
Вы получите следующий результат:
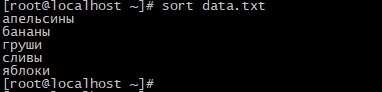
Как видим сейчас строки отсортированы в алфавитном порядке.
Вывод результатов в файл
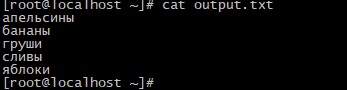
Команда sort не изменяет исходный файл, а просто выводит его содержимое в отсортированном виде. Чтобы сохранить результаты сортировки, воспользуйтесь опцией -o или перенаправлением вывода:
Выведем файл output.txt:
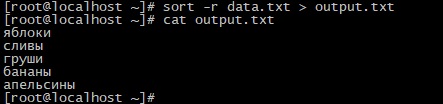
Вывод результатов в обратном порядке
Опция -r позволяет выводить результаты сортировки в обратном порядке:
Сортировка по заданным полям
Для сортировки по определенным полям используется опция –k. Она указывается в следующем формате:
Где ПОЛЕ1 и т.д. – номер поля (столбца), по которому осуществляется сортировка. Для примера создадим новый файл prices.txt со следующим содержимым:
Для его сортировки по второму столбцу можно выполнить следующую команду:
Результат будет следующим
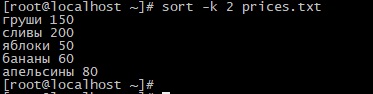
На первый взгляд кажется что команда сработала неправильно. Действительно, кажется что в самом верху должны стоять сливы, а яблоки нижней строкой, да и апельсины дороже банан. Но на самом деле команда sort воспринимает цифры не как число, а как строку, т.е сортировка происходит по первой цифре. Вот тогда все встает на свои места команда вывела последовательность не числовую сортировку «200-150-80-60-50» а строковую «1-2-5-6-8».
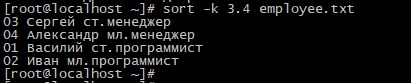
Опцию -k можно задавать в более сложном виде. Каждое поле задается в виде X.Y, где X – номер поля, а Y – начальная позиция поля, с которой начинается сортировка. Для примера создадим файл employee.txt со следующим содержимым:
Если просто указать номер поля, результат сортировки будет следующим:

Значение начальной позиции сортировки 4 заставит команду игнорировать первые 3 буквы и начнет сортировку с 4-й, т.е после «ст.» и «мл.»
Удаление дублирующих записей
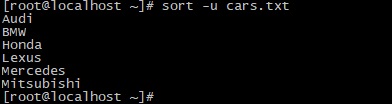
Опция -u удаляет из результатов дублирующие записи и выводит только уникальные поля. Допустим, у нас есть файл cars.txt со следующими данными:
Выведет следующий результат:
Проверка сортировки
Опция -с позволяет проверить, отсортированы ли данные в файле. Если выполнение команды с этой опцией не возвращает никакого результата, значит, строки файла уже упорядочены. Иначе будут выведены строки, нарушающие порядок сортировки. Допустим, файл cars2.txt содержит следующие данные:
Audi
Cadillac
BMW
Dodge
Для проверки выполним следующую команду:
Вот ее результат.
Мы видим, что строка «BMW» нарушает порядок сортировки:
Заключение
Команда sort – простой, но очень мощный и полезный при работе с данными инструмент. У нее есть множество разнообразных опций, помимо уже рассмотренных, которые можно узнать на соответствующей man-странице. Кроме того, ее можно использовать совместно с командами find и join для поиска по большому количеству файлов или объединения результатов.
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Источник
SORT command in Linux/Unix with examples
SORT command is used to sort a file, arranging the records in a particular order. By default, the sort command sorts file assuming the contents are ASCII. Using options in the sort command can also be used to sort numerically.
- SORT command sorts the contents of a text file, line by line.
- sort is a standard command-line program that prints the lines of its input or concatenation of all files listed in its argument list in sorted order.
- The sort command is a command-line utility for sorting lines of text files. It supports sorting alphabetically, in reverse order, by number, by month, and can also remove duplicates.
- The sort command can also sort by items not at the beginning of the line, ignore case sensitivity, and return whether a file is sorted or not. Sorting is done based on one or more sort keys extracted from each line of input.
- By default, the entire input is taken as the sort key. Blank space is the default field separator.
The sort command follows these features as stated below:
- Lines starting with a number will appear before lines starting with a letter.
- Lines starting with a letter that appears earlier in the alphabet will appear before lines starting with a letter that appears later in the alphabet.
- Lines starting with a lowercase letter will appear before lines starting with the same letter in uppercase.
Examples
Suppose you create a data file with name file.txt:
Sorting a file: Now use the sort command
Syntax :
Note: This command does not actually change the input file, i.e. file.txt.
Sort function with mix file i.e. uppercase and lower case: When we have a mix file with both uppercase and lowercase letters then first the upper case letters would be sorted following with the lower case letters.
Example:
Create a file mix.txt
Now use the sort command
Options with sort function:
1. -o Option: Unix also provides us with special facilities like if you want to write the output to a new file, output.txt, redirects the output like this or you can also use the built-in sort option -o, which allows you to specify an output file.
Using the -o option is functionally the same as redirecting the output to a file.
Note: Neither one has an advantage over the other.
Example: The input file is the same as mentioned above.
Syntax:
2. -r Option: Sorting In Reverse Order: You can perform a reverse-order sort using the -r flag. the -r flag is an option of the sort command which sorts the input file in reverse order i.e. descending order by default.
Example: The input file is the same as mentioned above.
Syntax :
3. -n Option: To sort a file numerically used –n option. -n option is also predefined in Unix as the above options are. This option is used to sort the file with numeric data present inside.
Example :
Let us consider a file with numbers:
Syntax:
4. -nr option: To sort a file with numeric data in reverse order we can use the combination of two options as stated below.
Example: The numeric file is the same as above.
Syntax :
5. -k Option: Unix provides the feature of sorting a table on the basis of any column number by using -k option.
Use the -k option to sort on a certain column. For example, use “-k 2” to sort on the second column.
Example :
Let us create a table with 2 columns
Syntax :
6. -c option: This option is used to check if the file given is already sorted or not & checks if a file is already sorted pass the -c option to sort. This will write to standard output if there are lines that are out of order. The sort tool can be used to understand if this file is sorted and which lines are out of order
Example :
Suppose a file exists with a list of cars called cars.txt.
Syntax :
7. -u option: To sort and remove duplicates pass the -u option to sort. This will write a sorted list to standard output and remove duplicates.
This option is helpful as the duplicates being removed give us a redundant file.
Example: Suppose a file exists with a list of cars called cars.txt.
Syntax :
8. -M Option: To sort by month pass the -M option to sort. This will write a sorted list to standard output ordered by month name.
Example:
Suppose the following file exists and is saved as months.txt
Using The -M option with sort allows us to order this file.
Application and uses of sort command:
- It can sort any type of file be it table file text file numeric file and so on.
- Sorting can be directly implemented from one file to another without the present work being hampered.
- Sorting of table files on the basis of columns has been made way simpler and easier.
- So many options are available for sorting in all possible ways.
- The most beneficial use is that a particular data file can be used many times as no change is made in the input file provided.
- Original data is always safe and not hampered.
Источник
Команда sort в Linux с примерами
Команда SORT в Linux используется для упорядочивания записей в определенном порядке в соответствии с используемой опцией. Это помогает в сортировке данных в файле построчно. Команда SORT имеет разные функции, которым она следует в результате команд. Во-первых, строки с номерами будут предшествовать буквенным строкам. Строки с строчными буквами будут отображаться раньше, чем строки с тем же символом в верхнем регистре.
Предпосылка
Вам необходимо установить Ubuntu на виртуальный ящик и настроить его. Пользователи должны быть созданы, чтобы иметь права доступа к приложениям.
Синтаксис
Пример
Это простой пример сортировки файла, имеющего данные об именах. Эти имена расположены не по порядку, и для того, чтобы упорядочить их, вам необходимо их отсортировать.
Итак, рассмотрим файл с именем file1.txt. Мы отобразим содержимое файла с помощью добавленной команды:
Теперь используйте команду для сортировки текста в файле:
Сохранить результат в другом файле
Используя команду сортировки, вы узнаете, что ее результат только отображается, но не сохраняется. Чтобы зафиксировать результат, нам нужно его сохранить. Для этого используется опция —o в команде сортировки.
Рассмотрим пример имени sample1.txt с названиями автомобилей. Мы хотим отсортировать их и сохранить полученные данные в отдельном файле. Во время выполнения создается файл с именем result.txt, и в нем сохраняется соответствующий вывод. Данные из sample1.txt передаются в результирующий файл, а затем с помощью —o соответствующие данные сортируются. Мы отобразили данные с помощью команды cat:
$ sort –o result.txt sample1.txt
Вывод показывает, что данные отсортированы и сохранены в другом файле.
Сортировка по номеру столбца
Сортировка выполняется не только по одному столбцу. Мы можем отсортировать один столбец из-за второго столбца. Приведем пример текстового файла, в котором есть имена и оценки студентов. Мы хотим расположить их в порядке возрастания. Поэтому мы будем использовать в команде ключевое слово —k. В то время как —n используется для числовой сортировки.
Поскольку есть два столбца, поэтому 2 используется с n.
Проверьте отсортированное состояние файла
Если вы не уверены, отсортирован данный файл или нет, удалите это сомнение с помощью команды, которая проясняет путаницу и отображает сообщение. Мы рассмотрим два основных примера:
Теперь рассмотрим несортированный файл с названиями овощей.
В команде будет использоваться ключевое слово —c. Это проверит, отсортированы ли данные в файле или нет. Если данные не отсортированы, то вывод будет отображать номер строки первого слова, в котором присутствует несортированность, а также слово.
Из приведенного вывода вы можете понять, что 3- е слово в файле было неуместным.
Отсортированные данные
В этом случае, когда данные уже организованы, больше ничего делать не нужно. Рассмотрим файл result.txt.
Из результата вы можете видеть, что не отображается сообщение, указывающее на то, что данные в соответствующем файле уже отсортированы.
Удалить повторяющиеся элементы
Вот самый полезный вариант. Это помогает удалить повторяющиеся слова в файле и упорядочить элемент файла. Он также поддерживает согласованность данных в файле.
Представьте, что имя файла file2.txt содержит имена субъектов, но одна тема повторяется несколько раз. Затем команда сортировки будет использовать ключевое слово —u для удаления дублирования и родства:
Теперь вы можете видеть, что повторяющиеся элементы удаляются из вывода и что данные также сортируются.
Сортировка с помощью конвейера в команде
Если мы хотим отсортировать данные файла, предоставив список каталога относительно размеров файлов, мы включим все соответствующие данные каталога. ’Ls’ используется в команде, и -l отобразит его. Pipe поможет в упорядоченном отображении файлов.

Случайная сортировка
Иногда, выполняя какую-либо функцию, можно нарушить аранжировку. Если вы хотите расположить данные в любой последовательности и если нет критериев для сортировки, предпочтительнее случайная сортировка. Рассмотрим файл с именем sample3.txt, содержащий названия континентов.
Соответствующие выходные данные показывают, что файл отсортирован, а элементы расположены в другом порядке.
Сортировка данных из нескольких файлов
Одна из самых полезных команд сортировки — это одновременная сортировка данных из разных файлов. Это можно сделать с помощью команды find. Выходные данные команды find будут действовать как входные данные для команды после канала, который является командой сортировки. Ключевое слово Find используется для выдачи только одного файла в каждой строке, или мы можем сказать, что оно использует разрыв после каждого слова.
Например, давайте рассмотрим три файла с именами sample1.txt, sample2.txt и sample3.txt. Здесь «?» представляет собой любое число, за которым следует слово «образец». Find извлечет все три файла, и их данные будут отсортированы с помощью команды sort с инициативой pipe:
Выходные данные показывают, что данные всех файлов серии sample.txt отображаются и упорядочены в алфавитном порядке.

Сортировать с присоединением
Теперь мы представляем пример, который сильно отличается от тех, которые обсуждались ранее в этом руководстве. В дополнение к сортировке мы использовали join. Этот процесс выполняется таким образом, что оба файла сначала сортируются, а затем объединяются с помощью ключевого слова join.
Рассмотрим два файла, которые вы хотите объединить.
Теперь используйте приведенный ниже запрос, чтобы применить данную концепцию:
Из вывода видно, что данные обоих файлов объединены в отсортированном виде.
Сравнить файлы с помощью сортировки
Мы также можем принять концепцию сравнения двух файлов. Техника такая же, как и для стыковки. Сначала сортируются два файла, а затем данные в них сравниваются.
Рассмотрим те же два файла, что и в предыдущем примере. Sample2.txt и sample3.txt:
Данные сортируются и упорядочиваются поочередно. Начальная строка файла sample2.txt записывается рядом с первой строкой файла sample3.txt.
Заключение
В этой статье мы рассказали об основных функциях и параметрах команды сортировки. Команда сортировки Linux очень полезна для обслуживания данных и фильтрации всех бесполезных элементов из файлов.
Источник



