- Access Linux filesystems in Windows and WSL 2
- Getting started
- Accessing these files with File Explorer
- Limitations
- Give us your feedback!
- Навигация по файловой системе File System Navigation
- Обзор Overview
- Пути Paths
- Создание и составление путей Constructing and composing paths
- Проверка путей Examining paths
- Сравнение путей Comparing paths
- Преобразование между типами пути и строки Converting between path and string types
- Итерация по каталогам и файлам Iterating directories and files
- The basics of file systems
- What is a file system?
- File systems of Windows
- File systems of macOS
- File systems of Linux
- ReiserFS
- Btrfs
- File systems of BSD, Solaris, Unix
- Clustered file systems
Access Linux filesystems in Windows and WSL 2
September 10th, 2020
Starting with Windows Insiders preview build 20211, WSL 2 will be offering a new feature: wsl —mount . This new parameter allows a physical disk to be attached and mounted inside WSL 2, which enables you to access filesystems that aren’t natively supported by Windows (such as ext4).
So, if you’re dual booting with Windows & Linux using different disks, you can now access your Linux files from Windows!
Getting started
To mount a disk, open a PowerShell window with administrator privileges and run:
To list the available disks in Windows, run:
To unmount and detach the disk from WSL 2, run
The disks paths are available under the ‘DeviceID’ columns. Usually under the \\.\\\.\PHYSICALDRIVE* format. Below is an example of mounting a specific partition of a given hard disk into WSL and browsing its files.
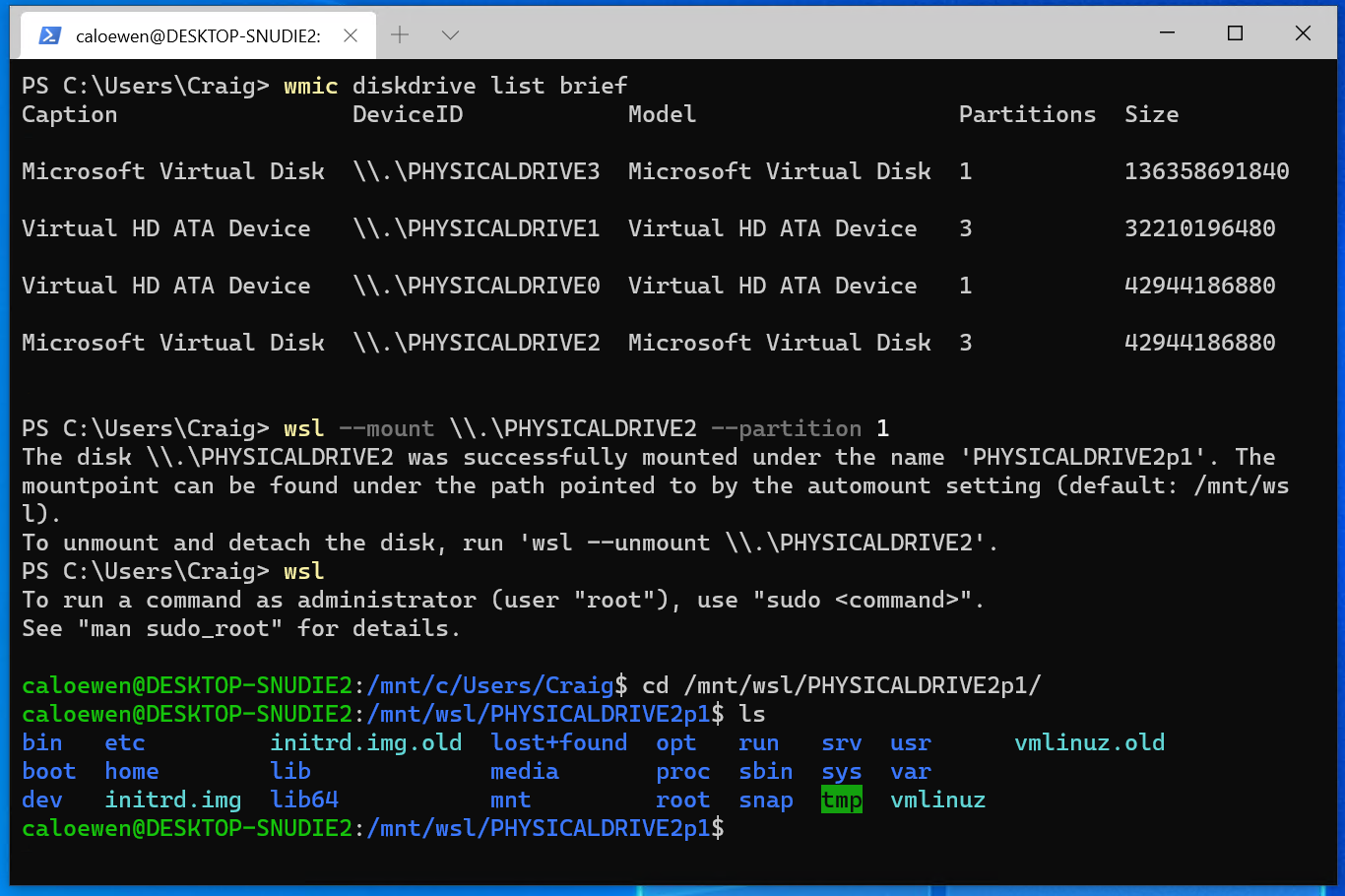
Accessing these files with File Explorer
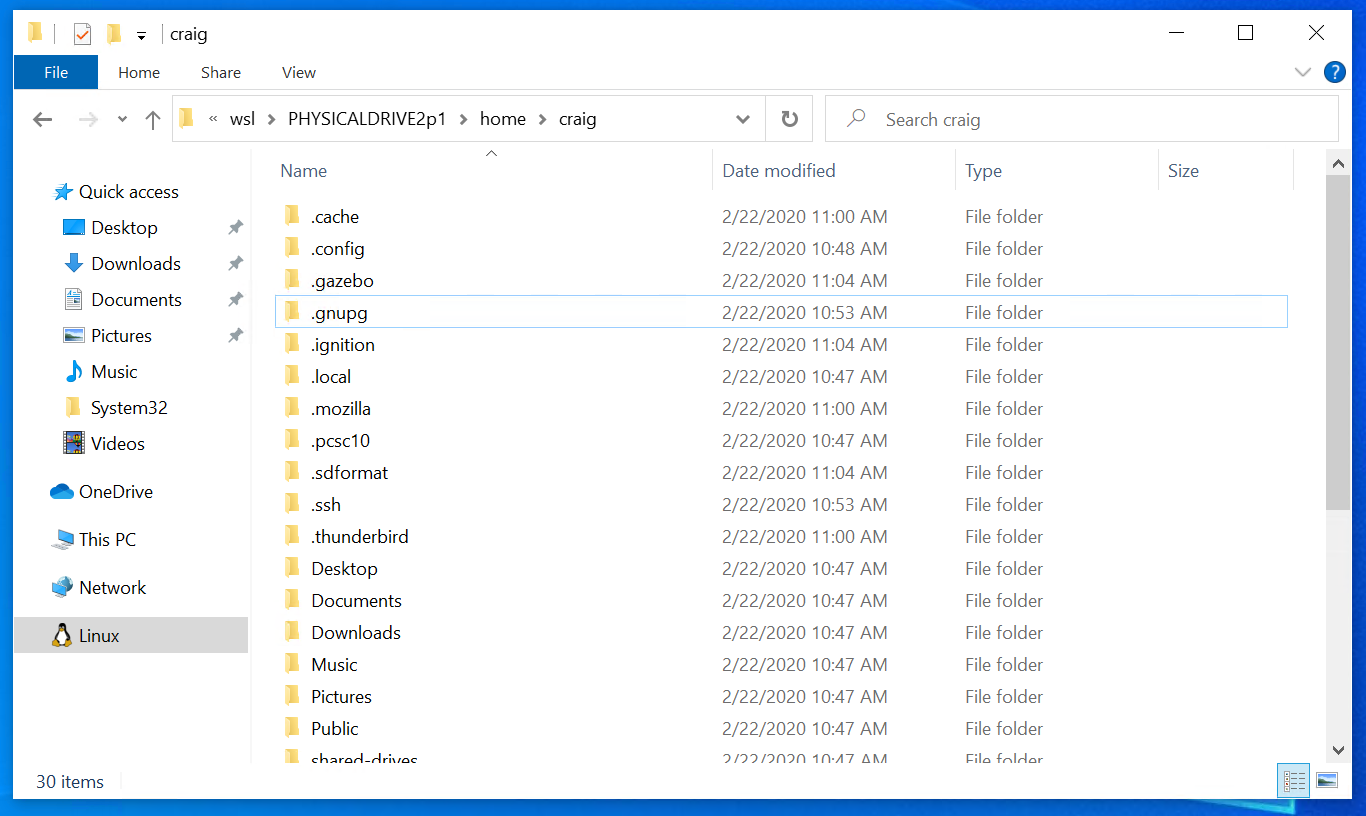
Once mounted, it’s also possible to access these disks through the Windows explorer by navigating to \wsl$ and then to the mount folder.
Limitations
By default, wsl —mount attempts to mount the disk as ext4. To specify a filesystem, or for more advanced scenarios, check out Mount a disk in WSL 2.
Also please note that this feature comes with the limitation that only physical disks can be attached to WSL 2. At this time, it’s not possible to attach a single partition. More details on the limitations here.
Give us your feedback!
If you run into any issues, or have feedback for our team please file an issue on our Github , and if you have general questions about WSL you can find all of our team members that are on Twitter on this twitter list.
Навигация по файловой системе File System Navigation
Заголовок реализует техническую спецификацию файловой системы C++ ISO/IEC TS 18822:2015 (окончательный вариант черновика: ISO/IEC JTC 1/SC 22/WG 21 N4100) и имеет типы и функции, позволяющие создавать независимый от платформы код для навигации по файловой системе. The header implements the C++ File System Technical Specification ISO/IEC TS 18822:2015 (Final draft: ISO/IEC JTC 1/SC 22/WG 21 N4100) and has types and functions that enable you to write platform-independent code for navigating the file system. Поскольку это межплатформенное приложение, оно содержит интерфейсы API, не относящиеся к системам Windows. Because it’s cross-platform, it contains APIs that aren’t relevant for Windows systems. Например, is_fifo(const path&) всегда возвращает значение false в Windows. For example, is_fifo(const path&) always returns false on Windows.
Обзор Overview
Используйте API для следующих задач: Use the APIs for the following tasks:
выполнение итерации по файлам и каталогам в указанном пути; iterate over files and directories under a specified path
получение сведений о файлах, включая время создания, размер, расширение и корневой каталог; get information about files including the time created, size, extension, and root directory
составление, разделение и сравнение путей; compose, decompose, and compare paths
Создание, копирование и удаление каталогов create, copy, and delete directories
копирование и удаление файлов. copy and delete files
Дополнительные сведения о вводе-выводе файлов с помощью стандартной библиотеки см. в разделе Программирование iostream. For more information about File IO using the Standard Library, see iostream Programming.
Пути Paths
Создание и составление путей Constructing and composing paths
Пути в Windows (начиная с XP) изначально хранятся в Юникоде. Paths in Windows (since XP) are stored natively in Unicode. path Класс автоматически выполняет все необходимые преобразования строк. The path class automatically does all necessary string conversions. Он принимает аргументы как для широких, так и для узких символьных массивов, а также для std::string std::wstring типов, отформатированных как UTF8 или UTF16. It accepts arguments of both wide and narrow character arrays, and both std::string and std::wstring types formatted as UTF8 or UTF16. Класс path также автоматически нормализует разделители путей. The path class also automatically normalizes path separators. В аргументах конструктора в качестве разделителя каталогов можно использовать одиночную косую черту. You can use a single forward slash as a directory separator in constructor arguments. Этот разделитель позволяет использовать одни и те же строки для хранения путей в средах Windows и UNIX: This separator lets you use the same strings to store paths in both Windows and UNIX environments:
Для объединения двух путей можно использовать перегруженные операторы / и /= , которые аналогичны операторам + и += в std::string и std::wstring . To concatenate two paths, you can use the overloaded / and /= operators, which are analogous to the + and += operators on std::string and std::wstring . path Объект будет удобным образом предоставлять разделители, если это не так. The path object will conveniently supply the separators if you don’t.
Проверка путей Examining paths
Класс Path имеет несколько методов, возвращающих сведения о различных частях пути. The path class has several methods that return information about various parts of the path itself. Эта информация отличается от сведений о сущности файловой системы, на которую может ссылаться. This information is distinct from the information about the file system entity it might refer to. Можно получить корень, относительный путь, имя файла, расширение файла и другие сведения. You can get the root, the relative path, the file name, the file extension, and more. Можно выполнять итерацию по объекту path для проверки всех папок в иерархии. You can iterate over a path object to examine all the folders in the hierarchy. В следующем примере показано, как выполнить итерацию по объекту пути. The following example shows how to iterate over a path object. И, как получить сведения о его частях. And, how to retrieve information about its parts.
Код создает следующие выходные данные: The code produces this output:
Сравнение путей Comparing paths
Класс path перегружает операторы сравнения на равенство как std::string и std::wstring . The path class overloads the same comparison operators as std::string and std::wstring . При сравнении двух путей необходимо выполнить сравнение строк после нормализации разделителей. When you compare two paths, you make a string comparison after the separators have been normalized. Если пропущена Замыкающая косая черта (или обратная косая черта), она не добавляется и влияет на сравнение. If a trailing slash (or backslash) is missing, it isn’t added, and that affects the comparison. В следующем примере показано, как выполняется сравнение значений пути: The following example demonstrates how path values compare:
Для запуска этого кода вставьте его в полный пример выше перед main и раскомментируйте строку, которая вызывает его в основном объекте. To run this code, paste it into the full example above before main and uncomment the line that calls it in main.
Преобразование между типами пути и строки Converting between path and string types
Объект path может быть неявно преобразован в std::wstring или std::string . A path object is implicitly convertible to std::wstring or std::string . Это означает, что можно передать путь к таким функциям wofstream::open , как, как показано в следующем примере: It means you can pass a path to functions such as wofstream::open , as shown in this example:
Итерация по каталогам и файлам Iterating directories and files
Заголовок предоставляет directory_iterator тип для итерации по отдельным каталогам и recursive_directory_iterator класс для рекурсивного прохода по каталогу и его подкаталогам. The header provides the directory_iterator type to iterate over single directories, and the recursive_directory_iterator class to iterate recursively over a directory and its subdirectories. После создания итератора путем передачи ему объекта path итератор указывает на первое значение directory_entry в пути. After you construct an iterator by passing it a path object, the iterator points to the first directory_entry in the path. Создайте конечный итератор путем вызова конструктора по умолчанию. Create the end iterator by calling the default constructor.
При итерации по каталогу существует несколько типов элементов, которые можно обнаружить. When iterating through a directory, there are several kinds of items you might discover. К этим элементам относятся каталоги, файлы, символические ссылки, файлы сокетов и др. These items include directories, files, symbolic links, socket files, and others. directory_iterator Возвращает свои элементы в виде directory_entry объектов. The directory_iterator returns its items as directory_entry objects.
The basics of file systems

Presently, the computer market offers a huge variety of opportunities for storing information in the digital form. Existing storage devices include internal and external hard drives, memory cards of photo/video cameras, USB flash drives, RAID sets along with other complex storage systems. Pieces of data are kept on them in the form of files, like documents, pictures, databases, email messages, etc. which have to be efficiently organized on the disk and easily retrieved when needed.
The following article provides a general overview of the file system, the major means of data management on any storage, and describes the peculiarities of different file system types.
What is a file system?
Any computer file is stored on a storage medium with a given capacity. In actual fact, each storage is linear space for reading or both reading and writing digital information. Each byte of information on it has its offset from the storage start known as an address and is referenced by this address. A storage can be presented as a grid with a set of numbered cells (each cell is a single byte). Any file saved to the storage gets its own cells.
Generally, computer storages use the pair of a sector and in-sector offset to reference any byte of information on the storage. A sector is a group of bytes (usually 512 bytes), a minimum addressable unit of the physical storage. For example, byte 1040 on a hard disk will be referenced as a sector #3 and offset in sector 16 bytes ([sector]+[sector]+[16 bytes]). This scheme is applied to optimize storage addressing and to use a smaller number to refer to any portion of information located on the storage.
To omit the second part of the address (in-sector offset), files are usually stored starting from the sector start and occupy whole sectors (e.g.: a 10-byte file occupies the whole sector, a 512-byte file also occupies the whole sector, at the same time, a 514-byte file occupies two entire sectors).
Each file is stored in «unused» sectors and can be read later by its known position and size. However, how do we know which sectors are occupied and which are free? Where are the size, position and name of the file stored? This is exactly what the file system is responsible for.
As a whole, a file system is a structured representation of data and a set of metadata describing this data. It is applied to the storage during the format operation. A file system serves for the purposes of the whole storage and is also a part of an isolated storage segment – a disk partition. Usually, a file system operates blocks, not sectors. File system blocks are groups of sectors that optimize storage addressing. Modern file systems generally use block sizes from 1 to 128 sectors (512-65536 bytes). Files are usually stored at the start of a block and take up entire blocks.
Constant write/delete operations in the file system cause its fragmentation. Thus, files are not stored as whole units, but get divided into fragments. For example, a storage is completely occupied by files with the size of about 4 blocks each (e.g. a collection of photos). A user wants to store a file that will take up 8 blocks and therefore deletes the first and the last files. By doing this, he or she frees the space of 8 blocks, however, the first segment is located near to the storage start while the second one – to the storage end. In this case, the 8-block file is split into two parts (4 blocks for each part) and takes the free space «holes». The information about both fragments as parts of a single file is stored in the file system.
In addition to user’s files, the file system also contains its own parameters (such as a block size), file descriptors (including file size, file location, its fragments, etc.), file names and directory hierarchy. It may also store security information, extended attributes and other parameters.
To comply with diverse users’ requirements, such as storage performance, stability and reliability, plenty of file systems are developed to be able to serve different purposes more effectively.
File systems of Windows
Microsoft Windows employs two major file systems: NTFS, the primary format most modern versions of this OS use by default, and FAT, which was inherited from old DOS and has exFAT as its later extension. The ReFS file system was also introduced by Microsoft as a new generation file system for server computers starting from Windows Server 2012. The HPFS file system developed by Microsoft together with IBM can be found only on extremely old machines running Windows NT up to 3.5.
FAT (File Allocation Table) is one of the simplest file system types, which has been around since the 1980s. It consists of the file system descriptor sector (boot sector or superblock), the file system block allocation table (referred to as the File Allocation Table) and plain storage space for storing files and folders. Files in FAT are stored in directories. Each directory is an array of 32-byte records, each defining a file or extended attributes of a file (e.g. a long file name). A file record attributes the first block of a file. Any next block can be found through the block allocation table by using it as a linked list.
The block allocation table contains an array of block descriptors. A zero value indicates that the block is not used and a non-zero one relates to the next block of a file or a special value for the file end.
The numbers in FAT12, FAT16, FAT32 stand for the number of bits used to enumerate a file system block. This means that FAT12 can use up to 4096 different block references, while FAT16 and FAT32 can use up to 65536 and 4294967296 accordingly. The actual maximum count of blocks is even less and depends on the implementation of the file system driver.
FAT12 and FAT16 used to be applied to old floppy disks and do not find extensive employment nowadays. FAT32 is still widely used for memory cards and USB sticks. The system is supported by smartphones, digital cameras and other portable devices.
FAT32 can be used on Windows-compatible external storages or disk partitions with the size under 32 GB (Windows cannot create a FAT32 file system which would be larger than 32 GB, although Linux supports the size up to 2 TB) and doesn’t allow creating files the size of which exceeds 4 GB. To address this issue, exFAT was introduced, which doesn’t have any realistic limitations concerning the size of files or partitions and is frequently utilized on modern external hard drives and SSDs.
NTFS (New Technology File System) was introduced in 1993 with Windows NT and is currently the most common file system for end user computers based on Windows. Most operating systems of the Windows Server line use this format as well.
The file system is quite reliable thanks to journaling and supports many features, including access control, encryption, etc. Each file in NTFS is stored as a file descriptor in the Master File Table and file content. The Master file table contains entries with all information about files: size, allocation, name, etc. The first 16 entries of the Master File Table are retained for the BitMap, which keeps record of all free and used clusters, the Log used for journaling records and the BadClus containing information about bad clusters. The first and the last sectors of the file system contain file system settings (the boot record or the superblock). This file system uses 48 and 64 bit values to reference files, thus being able to support data storages with extremely high capacity.
ReFS (Resilient File System) is the latest development of Microsoft introduced with Windows 8 and now available for Windows 10. The file system architecture absolutely differs from other Windows file systems and is mainly organized in a form of the B+-tree. ReFS has high tolerance to failures due to new features included into the system. The most noteworthy one among them is Copy-on-Write (CoW): no metadata is modified without being copied; data is not written over the existing data – it is placed to another area on the disk. After any file modifications, a new copy of metadata is saved to a free area on the storage, and then the system creates a link from older metadata to the newer copy. Thus, the system stores a significant quantity of older backups in different places providing easy file recovery unless this storage space is overwritten.
HPFS (High Performance File System) was created by Microsoft in cooperation with IBM and introduced with OS/2 1.20 in 1989 as a file system for servers that could provide much better performance when compared to FAT. In contrast to FAT, a file system which simply allocates any first free cluster on the disk for the file fragment, HPFS seeks to arrange the file in contiguous blocks, or at least ensure that its fragments (referred to as extents) are placed maximally close to each other. At the beginning of HPFS, there are three control blocks occupying 18 sectors: the boot block, the super block and the spare block. The remaining storage space is divided into parts of contiguous sectors referred to as bands taking 8 MB each. A band has its own sector allocation bitmap showing which sectors in it are occupied (1 – taken, 0 – free). Each file and directory has its own F-Node located close to it on the disk – this structure contains the information about the location of a file and its extended attributes. A special directory band located in the center of the disk is used for storing directories while the directory structure itself is a balanced tree with alphabetical entries.
Hint: The information concerning data recovery perspectives of the file systems used by Windows can be found in the articles on data recovery specificities of different OS and chances for data recovery. For detailed instructions and recommendations, please, read the manual devoted to data recovery from Windows.
File systems of macOS
Apple’s macOS applies two file systems: HFS+, an extension to their legacy HFS file system used on old Macintosh computers, and APFS, a format employed by modern Macs running macOS 10.14 and later.
HFS+ used to be the primary file system of Apple desktop products, including Mac computers, iPods, as well as Apple X Server products before it was replaced by APFS in macOS High Sierra. Advanced server products also use Apple Xsan file system, a clustered file system derived from StorNext and CentraVision.
The HFS+ file system uses B-trees for placing and locating files. Volumes are divided into sectors, typically 512 bytes in size, which are then grouped into allocation blocks, the number of which depends on the size of the entire volume. The information concerning free and used allocation blocks is kept in the Allocation File. All allocation blocks assigned to each file as extends are recorded in the Extends Overflow File. And, finally, all file attributes are listed in the Attributes file. Data reliability is improved through journaling which makes it possible to keep track of all changes to the system and quickly return it back to the working state in case of unexpected events. Among other supported features are hard links to directories, logical volume encryption, access control, data compression, etc.
The Apple file system is aimed to address fundamental issues present in its predecessor and was developed to efficiently work with modern flash storages and solid-state drives. This 64-bit file system uses the copy-on-write method to increase performance, which allows to copy each block before the changes to it are applied, and offers a lot of data integrity and space-saving features. All the file contents and metadata about files, folders along with other APFS structures are kept in the APFS container. The Container Superblock stores information about the number of blocks in the Container, the block size, etc. Information about all allocated and free blocks of the Container is managed with the help of Bitmap Structures. Each volume in the Container has its own Volume Superblock which provides information about this volume. All files and folders of the volume are recorded in the File and Folder B-Tree, while the Extents B-Tree is responsible for extents – references to file contents (file start, its length in blocks).
Hint: The details related to the possibility of data recovery from these file systems can be found in the articles about the peculiarities of data recovery depending on the operating system and chances for data recovery. If you’re interested in the practical side of the procedure, please, refer to the guide on data recovery from macOS.
File systems of Linux
Open-source Linux aims at implementing, testing and using different types of file systems. The most popular Linux file systems include:
Ext2, Ext3, Ext4 are simply different versions of the «native» Linux Ext file system. This file system falls under active developments and improvements. Ext3 file system is just an extension of Ext2 that uses transactional file writing operations with a journal. Ext4 is a further development of Ext3, extended with the support of optimized file allocation information (extents) and extended file attributes. This file system is frequently used as a «root» file system for most Linux installations.
ReiserFS
ReiserFS — an alternative Linux file system optimized for storing a huge number of small files. It has a good capability for files search and enables compact allocation of files by storing tails of files or simply very small files along with metadata in order to avoid using large file system blocks for this purpose. However, this file system is no longer actively developed and supported.
XFS — a robust journaling file system that was initially created by Silicon Graphics and used by the company’s IRIX servers. In 2001, it made its way to the Linux kernel and is now supported by most Linux distributions, some of which, like Red Hat Enterprise Linux, even use it by default. This file system is optimized for storing very big files and file systems on a single host.
JFS — a file system developed by IBM for the company’s powerful computing systems. JFS1 usually stands for JFS, JFS2 is the second release. Currently, this file system is open-source and implemented in most modern Linux versions.
Btrfs
Btrfs — a file system based on the copy-on-write principle (COW) that was designed by Oracle and has been supported by the mainline Linux kernel since 2009. Btrfs embraces the features of a logical volume manager, being able to span multiple devices, and offers much higher fault tolerance, better scalability, easier administration, etc. together with a number of advanced possibilities.
F2FS – a Linux file system designed by Samsung Electronics that is adapted to the specifics of storage devices based on the NAND flash memory that are widely used in modern smartphones and other computing systems. The file system works on the basis of the log-structured file system approach (LFS) and takes into account such peculiarities of flash storage as constant access time and a limited number of data rewriting cycles. Instead of creating one large chunk for writing, F2FS assembles the blocks into separate chunks (up to 6) that are written concurrently.
The concept of «hard links» used in this kind of operating systems makes most Linux file systems similar in that the file name is not regarded as a file attribute and rather defined as an alias for a file in a certain directory. A file object can be linked from many locations, even multiply from the same directory under different names. This can lead to serious and even insurmountable difficulties in recovery of file names after file deletion or file system damage.
Hint: The information concerning the possibility of successful recovery of data from the mentioned file systems can be found in the articles describing the specifics of data recovery from different operating systems and chances for data recovery. To get a grasp on how the procedure should be carried out, please, use the manual on data recovery from Linux.
File systems of BSD, Solaris, Unix
The most common file system for these operating systems is UFS (Unix File System) also often referred to as FFS (Fast File System).
Currently, UFS (in different editions) is supported by all Unix-family operating systems and is a major file system of the BSD OS and the Sun Solaris OS. Modern computer technologies tend to implement replacements for UFS in different operating systems (ZFS for Solaris, JFS and derived file systems for Unix etc.).
Hint: The information about the likelihood of a successful result when it comes to data recovery from these file systems can be found in the articles about OS-specific peculiarities of data recovery and chances for data recovery. The process itself is described in the instruction dedicated to data recovery from Unix, Solaris and BSD.
Clustered file systems
Clustered file systems are used in computer cluster systems. These file systems support distributed storage.
Distributed file systems include:
ZFS – Sun company «Zettabyte File System» — a file system developed for distributed storages of Sun Solaris OS.
Apple Xsan – the Apple company evolution of CentraVision and later StorNext file systems.
VMFS – «Virtual Machine File System» developed by VMware company for its VMware ESX Server.
GFS – Red Hat Linux «Global File System«.
JFS1 – the original (legacy) design of IBM JFS file system used in older AIX storage systems.
Common properties of these file systems include distributed storages support, extensibility and modularity.
To learn about other technologies used to store and manipulate data, please, refer to the storage technologies section.



