- Реализация стека на Python
- Создаем стек на Python
- Хотите больше материалов по Python
- Проверка нашего стека
- Бонус: интеграция метода max()
- Python stack size windows
- Implementation
- Implementation using list:
- Python threading.stack_size() has no effect
- 3 Answers 3
- Python stack size windows
- Implementation
- Implementation using list:
- Python consumes a lot of memory or how to reduce the size of objects?
- Class instance
- Instance of class with __slots__
- Tuple
- Namedtuple
- Recordclass: mutable namedtuple without cyclic GC
- Dataobject
- Cython
- Numpy
- Conclusion
Реализация стека на Python
На собеседовании вам вполне могут предложить написать код для реализации стека или очереди. Да, на работе вам, вероятно, за всю карьеру не случится этого делать, но задачи для вайтбоардинга отличаются своей нежизненностью. Несмотря на это, такие задачи — отличный способ продемонстрировать, что вы умеете реализовывать классы (т. е. создавать вещи, которые делают то, что вы сказали им делать).
Концепции стеков и очередей довольно простые. Стек (англ. stack — стопка) похож на стопку тарелок. Если у вас есть такая стопка, убирать тарелки вы будете, начиная сверху. Таким образом, последняя тарелка, которую вы положили на стопку, будет убрана первой. Вероятно, вы слышали термин LIFO — Last In First Out («последним пришел, первым ушел»).

А в очередях все наоборот: первый элемент в очереди удаляется тоже первым. Представьте себе очередь в Starbucks. Первый человек в очереди всегда получает свой кофе первым.
Создаем стек на Python
Итак, давайте рассмотрим упрощенный пример задачи, которую вам могут дать на техническом собеседовании. Советуем параллельно с чтением писать этот код в своем редакторе.
Задача начинается со слова «Реализуйте». Это намекает на то, что от вас ожидается создание класса. Если вы не привыкли еще работать с классами, можете считать их чем-то вроде шаблона объекта. При инициации нового объекта класса Stack он будет иметь все свойства и методы, которые мы определим для этого класса.
Начнем с определения класса, а затем добавим метод __init__ . Кроме того мы добавим пустые методы pop() и push() . Ключевое слово pass нужно только для того, чтобы Python не ругался на наличие пустых методов.
Отлично, теперь у нас есть класс Stack . Давайте определим метод __init__ , который будет устанавливать все свойства стека при инициализации. То есть, при рождении каждого нового стека мы будем наделять его кое-чем. Есть идеи, чем именно?
Стек по сути своей — список (в Python массивы называются списками) с особыми свойствами: вы можете добавлять или удалять только самый недавний элемент. Исходя из этого, мы представим стек как список и назовем его stack . Чтобы определить свойство класса, в Python используется ключевое слово self . Для доступа к этому ключевому слову его нужно передать в качестве аргумента в метод.
Хорошо, теперь давайте перейдем к методу push() . Он тоже будет принимать self в качестве аргумента, чтобы мы могли иметь доступ к только что определенной переменной stack . Кроме того, он будет принимать item — элемент, который мы хотим добавить на вершину стека.
При добавлении и удалении элементов из стека его вершиной будем считать конец списка. В Python это все облегчает, поскольку мы можем использовать метод .append() для добавления элемента в конец списка:
Метод pop() будет аналогичным. В Python есть метод .pop() , удаляющий последний элемент списка. Очень удобно! Этот метод возвращает удаляемый элемент. Мы будем сохранять этот элемент в переменную removed , а затем возвращать переменную.
Но погодите! У нас есть проблема. Что, если в стеке не останется элементов для удаления? К счастью, в условии задачи нам напомнили о такой ситуации:
Все, что нам нужно сделать, это добавить условное выражение для проверки этого крайнего случая. Для этого перед запуском .pop мы добавим предложение if , проверяющее, не пуст ли стек. Единственный тип null в Python — это None , так что его мы и вернем, если стек все же пуст.
Вот и все! Повторим:
Есть еще одна вещь, на которую следует обратить внимание. Все наши методы должны иметь постоянную временную сложность — O(1) . Это означает, что их работа должна занимать одинаковое время, независимо от длины стека. Если бы нам пришлось, к примеру, перебирать список в цикле, временная сложность была бы O(n) , где n — длина списка. Но нам ничего такого делать не пришлось, так что все в порядке.
Хотите больше материалов по Python
Подписывайтесь на нас в Телеграм
Проверка нашего стека
Надеемся, вы не только читали статью, но и параллельно писали этот код. Но в таком случае вы, вероятно, заметили, что при его запуске ничего не происходит.
Как уже было сказано, классы — это своего рода шаблоны объектов. Мы создали шаблон. Теперь давайте проверим его, создав объект. Вы можете это сделать или в оболочке Python, или внизу вашего файла stack.py. Для простоты назовем стек s .
Теперь давайте протестируем наш прекрасный метод push() , добавив в стек несколько чисел.
Если мы выведем наш s.stack , мы получим [1, 2, 3]. Отлично. Давайте теперь проверим метод pop() .
Если мы теперь выведем s.stack , мы получим [1, 2]. Обратите внимание, что удалился только последний элемент, при этом вернулось значение 3. Но что будет, если мы продолжим удалять элементы? Нам нужно увидеть, вернет ли наш метод None . Для этого мы повторим ту же команду несколько раз, а затем выведем значение return .
Итак, вы реализовали свой первый стек на Python. Можно сказать, изучили свою первую структуру данных.
Бонус: интеграция метода max()
Подобная задача давалась кандидату на интервью в Amazon. Но там запрашивался еще один дополнительный метод:
Чтобы это сработало, нам нужно кое-что изменить в нашем классе Stack . Начнем с __init__ . Давайте добавим переменную max для отслеживания максимального значения в стеке. Условие предлагает нам вернуть нулевое значение, если стек пуст. Поэтому мы инициализируем переменную как None .
Круто. Теперь давайте обновим метод push() . Нам нужно проверить два варианта:
- Является ли этот элемент первым элементом, добавляемым в стек. В этом случае текущее значение max — None , и нам нужно инициализировать переменную первым добавляемым значением.
- Если max уже имеет какое-то значение, нам нужно сравнить его со значением добавляемого элемента и соответственно обновить.
В обоих случаях мы будем устанавливать новое значение max для добавляемого элемента. Это удачный момент для применения однострочного условия с or .
А теперь давайте взглянем на pop() . Опять же, нам нужно проверить два варианта:
- Является ли удаляемый элемент последним в стеке. Если стек пуст, нужно установить max в None .
- Если удаляемый элемент равен значению max , нужно перебрать в цикле список и найти новое значение.
С первым случаем все просто. После вызова .pop() для списка мы проверяем, стала ли длина списка равной нулю.
Для проверки второго случая мы используем цикл for . Начнем с установки для max значения, которое, как мы знаем, уже есть в стеке, — первого значения. Затем переберем в цикле весь список и сверим каждое значение с первым. Если значение будет больше self.max , будем обновлять self.max новым, большим значением.
И в конце мы будем возвращать значение, которое удалили из стека. Целиком наш метод будет выглядеть так:
Наконец, давайте реализуем метод max() . Назначение этого метода — просто возвращать значение определенной нами переменной max. Но в Python мы можем просто получить доступ к этому значению вне определения класса, вызвав s.max . Зачем же нам писать целый метод, чтобы просто вернуть его?
Это пережиток объектно-ориентированного программирования на Java. Традиционно считается best practice делать все переменные приватными. Если бы вы создавали, скажем, радио, вы бы не захотели, чтобы пользователи копались в проводах. Пользователь должен пользоваться регуляторами и кнопками снаружи. В Java вы бы инициализировали поле max ключевым словом private . Затем вы бы написали метод max или get_max() , возвращающий это значение, и это был бы единственный способ доступа к нему.
В Python мы можем делать переменные приватными, просто определяя их с двойным символом подчеркивания перед именем: __max . Хотите ли вы это делать, зависит от вас. На интервью лучше спросить интервьюера, чего он ждет. Тот факт, что вы вообще зададите этот вопрос, сам по себе будет говорить в вашу пользу. К тому же, в итоге вы сделаете именно то, что от вас ожидалось.
Теперь можно протестировать наш код, добавляя и удаляя элементы и проверяя при этом, правильно ли обновляется переменная max .
Python stack size windows

A stack is a linear data structure that stores items in a Last-In/First-Out (LIFO) or First-In/Last-Out (FILO) manner. In stack, a new element is added at one end and an element is removed from that end only. The insert and delete operations are often called push and pop.
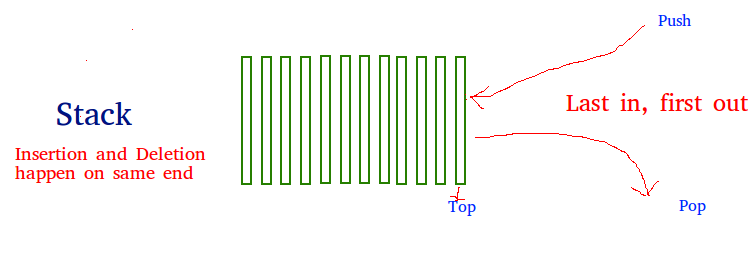
The functions associated with stack are:
- empty() – Returns whether the stack is empty – Time Complexity : O(1)
- size() – Returns the size of the stack – Time Complexity : O(1)
- top() – Returns a reference to the top most element of the stack – Time Complexity : O(1)
- push(g) – Adds the element ‘g’ at the top of the stack – Time Complexity : O(1)
- pop() – Deletes the top most element of the stack – Time Complexity : O(1)
Implementation
There are various ways from which a stack can be implemented in Python. This article covers the implementation of stack using data structures and modules from Python library.
Stack in Python can be implemented using following ways:
- list
- collections.deque
- queue.LifoQueue
Implementation using list:
Python’s buil-in data structure list can be used as a stack. Instead of push(), append() is used to add elements to the top of stack while pop() removes the element in LIFO order.
Unfortunately, list has a few shortcomings. The biggest issue is that it can run into speed issue as it grows. The items in list are stored next to each other in memory, if the stack grows bigger than the block of memory that currently hold it, then Python needs to do some memory allocations. This can lead to some append() calls taking much longer than other ones.
Python threading.stack_size() has no effect
I am trying to reduce the stack size for a python script in order to produce more threads. I am setting it like this
And putting it at the import level, before any threads get started The problem is that, it has no effect. With or without it, i can start the exact number of threads. I am using Python 2.7 x86 on a Windows 7 machine x64, over 2.4GB RAM available.
Any thoughts on why it has no effect ? I am really looking for a solution, rather than comments on the number of threads I need to spawn.
I suspect it has to do with the .pyc files related to threading, I remember i faced this situation where deleting thoose .pyc files and letting python recompile them on the next run would apply the changes, but I do not know what files to temper with regarding threading.
Would appreciate any help I can get.
P.S. Please do not recommend using Twisted or Asyncore, I know they are better, but I need to make the best of it regarding the current situation, rather than to redesign the entire code.
3 Answers 3
The minimum thread stack size on Windows is probably at least 64kB. Quoting:
So trying to set it to 32kB will probably look a lot like trying to set it to 64kB.
Additionally, CPython implements threading.stack_size on Windows so that it only controls the initially committed stack. It does not try to control the reserve memory for the stack. From the same location:
This means that each of your threads uses up the reserve memory size in virtual memory. You didn’t mention how many threads you manage to create before encountering an error but I suspect it’s just enough to exhaust addressable memory in your process (which is probably a 32 bit process even though you’re running it on Windows 7 x86-64 because the CPython build/distribution is x86(-32)).
That is, even though you (your threads) are not using the memory and even though you have more physical memory on the system, Python can’t address the extra memory with its tiny 32 bit pointers and so new threads beyond the limit you’re encountering can’t have their reserve memory allocated (because there are no addresses left to assign to it).
If you want to be able to change the per-thread reserved memory then you probably need to call CreateThread or _beginthreadex differently than CPython calls it. This probably means need to get CPython changed.
That said, and at the risk of having you yell at me, I seriously doubt you need more than the 1500 threads you can already create.
Python stack size windows
A stack is a linear data structure that stores items in a Last-In/First-Out (LIFO) or First-In/Last-Out (FILO) manner. In stack, a new element is added at one end and an element is removed from that end only. The insert and delete operations are often called push and pop.
The functions associated with stack are:
- empty() – Returns whether the stack is empty – Time Complexity : O(1)
- size() – Returns the size of the stack – Time Complexity : O(1)
- top() – Returns a reference to the top most element of the stack – Time Complexity : O(1)
- push(g) – Adds the element ‘g’ at the top of the stack – Time Complexity : O(1)
- pop() – Deletes the top most element of the stack – Time Complexity : O(1)
Implementation
There are various ways from which a stack can be implemented in Python. This article covers the implementation of stack using data structures and modules from Python library.
Stack in Python can be implemented using following ways:
- list
- collections.deque
- queue.LifoQueue
Implementation using list:
Python’s buil-in data structure list can be used as a stack. Instead of push(), append() is used to add elements to the top of stack while pop() removes the element in LIFO order.
Unfortunately, list has a few shortcomings. The biggest issue is that it can run into speed issue as it grows. The items in list are stored next to each other in memory, if the stack grows bigger than the block of memory that currently hold it, then Python needs to do some memory allocations. This can lead to some append() calls taking much longer than other ones.
Python consumes a lot of memory or how to reduce the size of objects?
A memory problem may arise when a large number of objects are active in RAM during the execution of a program, especially if there are restrictions on the total amount of available memory.
Below is an overview of some methods of reducing the size of objects, which can significantly reduce the amount of RAM needed for programs in pure Python.
Note: This is english version of my original post (in russian).
For simplicity, we will consider structures in Python to represent points with the coordinates x , y , z with access to the coordinate values by name.
In small programs, especially in scripts, it is quite simple and convenient to use the built-in dict to represent structural information:
With the advent of a more compact implementation in Python 3.6 with an ordered set of keys, dict has become even more attractive. However, let’s look at the size of its footprint in RAM:
It takes a lot of memory, especially if you suddenly need to create a large number of instances:
| Number of instances | Size of objects |
|---|---|
| 1 000 000 | 240 Mb |
| 10 000 000 | 2.40 Gb |
| 100 000 000 | 24 Gb |
Class instance
For those who like to clothe everything in classes, it is preferable to define structures as a class with access by attribute name:
The structure of the class instance is interesting:
| Field | Size (bytes) |
|---|---|
| PyGC_Head | 24 |
| PyObject_HEAD | 16 |
| __weakref__ | 8 |
| __dict__ | 8 |
| TOTAL: | 56 |
Here __weakref__ is a reference to the list of so-called weak references to this object, the field __dict__ is a reference to the class instance dictionary, which contains the values of instance attributes (note that 64-bit references platform occupy 8 bytes). Starting in Python 3.3, the shared space is used to store keys in the dictionary for all instances of the class. This reduces the size of the instance trace in RAM:
As a result, a large number of class instances have a smaller footprint in memory than a regular dictionary ( dict ):
| Number of instances | Size |
|---|---|
| 1 000 000 | 168 Mb |
| 10 000 000 | 1.68 Gb |
| 100 000 000 | 16.8 Gb |
It is easy to see that the size of the instance in RAM is still large due to the size of the dictionary of the instance.
Instance of class with __slots__
A significant reduction in the size of a class instance in RAM is achieved by eliminating __dict__ and __weakref__ . This is possible with the help of a «trick» with __slots__ :
The object size in RAM has become significantly smaller:
| Field | Size (bytes) |
|---|---|
| PyGC_Head | 24 |
| PyObject_HEAD | 16 |
| x | 8 |
| y | 8 |
| z | 8 |
| TOTAL: | 64 |
Using __slots__ in the class definition causes the footprint of a large number of instances in memory to be significantly reduced:
| Number of instances | Size |
|---|---|
| 1 000 000 | 64 Mb |
| 10 000 000 | 640 Mb |
| 100 000 000 | 6.4 Gb |
Currently, this is the main method of substantially reducing the memory footprint of an instance of a class in RAM.
This reduction is achieved by the fact that in the memory after the title of the object, object references are stored — the attribute values, and access to them is carried out using special descriptors that are in the class dictionary:
To automate the process of creating a class with __slots__ , there is a library [namedlist] (https://pypi.org/project/namedlist). The namedlist.namedlist function creates a class with __slots__ :
Another package [attrs] (https://pypi.org/project/attrs) allows you to automate the process of creating classes both with and without __slots__ .
Tuple
Python also has a built-in type tuple for representing immutable data structures. A tuple is a fixed structure or record, but without field names. For field access, the field index is used. The tuple fields are once and for all associated with the value objects at the time of creating the tuple instance:
Instances of tuple are quite compact:
They occupy 8 bytes in memory more than instances of classes with __slots__ , since the tuple trace in memory also contains a number of fields:
| Field | Size (bytes) |
|---|---|
| PyGC_Head | 24 |
| PyObject_HEAD | 16 |
| ob_size | 8 |
| [0] | 8 |
| [1] | 8 |
| [2] | 8 |
| TOTAL: | 72 |
Namedtuple
Since the tuple is used very widely, one day there was a request that you could still have access to the fields and by name too. The answer to this request was the module collections.namedtuple .
The namedtuple function is designed to automate the process of generating such classes:
It creates a subclass of tuple, in which descriptors are defined for accessing fields by name. For our example, it would look something like this:
All instances of such classes have a memory footprint identical to that of a tuple. A large number of instances leave a slightly larger memory footprint:
| Number of instances | Size |
|---|---|
| 1 000 000 | 72 Mb |
| 10 000 000 | 720 Mb |
| 100 000 000 | 7.2 Gb |
Recordclass: mutable namedtuple without cyclic GC
Since the tuple and, accordingly, namedtuple -classes generate immutable objects in the sense that attribute ob.x can no longer be associated with another value object, a request for a mutable namedtuple variant has arisen. Since there is no built-in type in Python that is identical to the tuple that supports assignments, many options have been created. We will focus on [recordclass] (https://pypi.org/project/recordclass), which received a rating of [stackoverflow] (https://stackoverflow.com/questions/29290359/existence-of-mutable-named-tuple-in -python / 29419745). In addition it can be used to reduce the size of objects in RAM compared to the size of tuple -like objects..
The package recordclass introduces the type recordclass.mutabletuple , which is almost identical to the tuple, but also supports assignments. On its basis, subclasses are created that are almost completely identical to namedtuples, but also support the assignment of new values to fields (without creating new instances). The recordclass function, like the namedtuple function, allows you to automate the creation of these classes:
Class instances have same structure as tuple , but only without PyGC_Head :
| Field | Size (bytes) |
|---|---|
| PyObject_HEAD | 16 |
| ob_size | 8 |
| x | 8 |
| y | 8 |
| y | 8 |
| TOTAL: | 48 |
By default, the recordclass function create a class that does not participate in the cyclic garbage collection mechanism. Typically, namedtuple and recordclass are used to generate classes representing records or simple (non-recursive) data structures. Using them correctly in Python does not generate circular references. For this reason, in the wake of instances of classes generated by recordclass , by default, the PyGC_Head fragment is excluded, which is necessary for classes supporting the cyclic garbage collection mechanism (more precisely: in the PyTypeObject structure, corresponding to the created class, in the flags field, by default, the flag Py_TPFLAGS_HAVE_GC` is not set).
The size of the memory footprint of a large number of instances is smaller than that of instances of the class with __slots__ :
| Number of instances | Size |
|---|---|
| 1 000 000 | 48 Mb |
| 10 000 000 | 480 Mb |
| 100 000 000 | 4.8 Gb |
Dataobject
Another solution proposed in the recordclass library is based on the idea: use the same storage structure in memory as in class instances with __slots__ , but do not participate in the cyclic garbage collection mechanism. Such classes are generated using the recordclass.make_dataclass function:
The class created in this way, by default, creates mutable instances.
Another way – use class declaration with inheritance from recordclass.dataobject :
Classes created in this way will create instances that do not participate in the cyclic garbage collection mechanism. The structure of the instance in memory is the same as in the case with __slots__ , but without the PyGC_Head :
| Field | Size (bytes) |
|---|---|
| PyObject_HEAD | 16 |
| x | 8 |
| y | 8 |
| y | 8 |
| TOTAL: | 40 |
To access the fields, special descriptors are also used to access the field by its offset from the beginning of the object, which are located in the class dictionary:
The sizeo of the memory footprint of a large number of instances is the minimum possible for CPython:
| Number of instances | Size |
|---|---|
| 1 000 000 | 40 Mb |
| 10 000 000 | 400 Mb |
| 100 000 000 | 4.0 Gb |
Cython
There is one approach based on the use of [Cython] (https://cython.org). Its advantage is that the fields can take on the values of the C language atomic types. Descriptors for accessing fields from pure Python are created automatically. For example:
In this case, the instances have an even smaller memory size:
The instance trace in memory has the following structure:
| Field | Size (bytes) |
|---|---|
| PyObject_HEAD | 16 |
| x | 4 |
| y | 4 |
| y | 4 |
| пусто | 4 |
| TOTAL: | 32 |
The size of the footprint of a large number of copies is less:
| Number | Size |
|---|---|
| 1 000 000 | 32 Mb |
| 10 000 000 | 320 Mb |
| 100 000 000 | 3.2 Gb |
However, it should be remembered that when accessing from Python code, a conversion from int to a Python object and vice versa will be performed every time.
Numpy
Using multidimensional arrays or arrays of records for a large amount of data gives a gain in memory. However, for efficient processing in pure Python, you should use processing methods that focus on the use of functions from the numpy package.
An array of N elements, initialized with zeros, is created using the function:
The size of the array in memory is the minimum possible:
| Number of objects | Size |
|---|---|
| 1 000 000 | 12 Mb |
| 10 000 000 | 120 Mb |
| 100 000 000 | 1.20 Gb |
Normal access to array elements and rows will require convertion from a Python object to a C int value and vice versa. Extracting a single row results in the creation of an array containing a single element. Its trace will not be so compact anymore:
Therefore, as noted above, in Python code, it is necessary to process arrays using functions from the numpy package.
Conclusion
On a clear and simple example, it was possible to verify that the Python programming language (CPython) community of developers and users has real possibilities for a significant reduction in the amount of memory used by objects.



