Пишем модуль ядра Linux: GPIO с поддержкой IRQ
Данная статья посвящена разработке GPIO (General-Purpose Input/Output) модуля ядра Linux. Как и в предыдущей статье мы реализуем базовую структуру GPIO драйвера с поддержкой прерываний (IRQ: Interrupt Request).
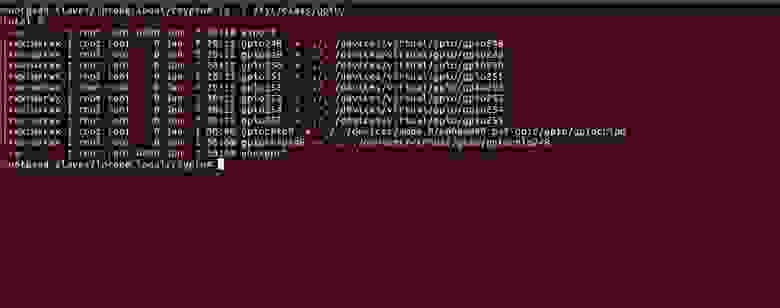
Входные данные аналогичны предыдущей статье: разработанный GPIO блок для нового процессора «зашитый» на ПЛИС и запущенный Linux версии 3.18.19.
Для того чтобы разработать GPIO драйвер, нам потребуется выполнить следующие шаги:
- Понять принцип взаимодействия GPIO драйвера с user space интерфейсом;
- Добавить модуль ядра в сборку и описать аппаратную часть в device tree;
- Реализовать базовый скелет драйвера, а также его точки входа и извлечения;
- Реализовать функциональную часть GPIO драйвера;
- Добавить к реализации драйвера поддержку IRQ.
Примеры GPIO драйверов можно посмотреть тут.
Шаг первый
Для начала познакомимся с принципом взаимодействия GPIO драйвера через консоль пользователя.
С помощью небольшого bash скрипта, создадим в /sysfs элементы управления каждого GPIO. Для этого в командой строке нужно написать следующий скрипт:
Далее посмотрим какие возможности предоставляет /sysfs для конфигурации каждого GPIO:
В данный момент нас интересуют следующие поля:
- direction — задает направление линии. Может принимать значения «in» или «out»;
- value — позволяет выставить высокий или низкий сигнал на линии (если direction установлен в «out»), в противном случае (direction установлен в «in») позволяет прочитать состояние линии;
- edge — позволяет настроить событие по которому происходит прерывание. Может принимать следующие значения: «none», «rising», «falling» или «both».
После беглого знакомства с интерфейсом взаимодействия драйвера через sysfs, можно рассмотреть как драйвер обрабатывает команды пользователя. В ядре Linux есть структура gpio_chip которая описывает функционал gpio контроллера. В ней присутствуют следующие поля:
- direction_input: настраивает линию на вход. Вызывается при следующей записи: echo «in» > /sys/class/gpio/gpio248/direction;
- direction_output: настраивает линию на выход. Вызывается при следующей записи: echo «out» > /sys/class/gpio/gpio248/direction;
- get: считывает установленное на линии значение. Вызывается при следующей записи: cat /sys/class/gpio/gpio248/value;
- set: устанавливает значение на линии. Вызывается при следующей записи: echo 1/0 > /sys/class/gpio/gpio248/value;
Для описания конфигурации IRQ в Linux существует структура irq_chip, которая содержит следующие поля:
- irq_set_type: настраивает тип события по которому будет происходить прерывание. Вызывается при следующей записи: echo > «rising»/«falling»/«both» > /sys/class/gpio/gpio248/edge;
- irq_mask: запрещает прерывания. Вызывается при следующей записи: echo «none» > /sys/class/gpio/gpio248/edge;
- irq_unmask: разрешает прерывание по событию, которое было установлено в irq_set_type. Вызывается сразу после выполнения irq_set_type.
Шаг второй
Теперь можно добавить драйвер в сборку и описать аппаратную часть, выполнив уже стандартные действия. Первым делом создадим исходный файл:
После добавим конфигурацию драйвера в drivers/gpio/Kconfig:
Добавим в сборку драйвер в drivers/gpio/Makefile:
И, наконец, добавим в devicetree (*.dts) описание GPIO блока:
Более подробную информацию про devicetree можно прочитать тут.
Шаг третий
Перейдем к самой интересной для нас части!
Разработку драйвера начнем с подключения необходимых заголовочных файлов и описания полного скелета драйвера без поддержки IRQ. Далее последовательно будем наполнять каждую функцию кодом и сопровождать необходимыми пояснениями.
Как видно из реализации, скелет драйвера выглядит достаточно просто и содержит не так много необходимых функций и структур.
Для того чтобы описать будущий драйвер нам потребуются следующие элементы:
- platform_driver skel_gpio_driver — описывает точку входа skel_gpio_probe при загрузке драйвера и skel_gpio_remove при его извлечении из ядра;
- struct of_device_id skel_gpio_of_match — содержит таблицу, которая описывает аппаратную часть GPIO блока;
- struct skel_gpio_chip — содержит необходимые поля для управления драйвером GPIO блоком.
Далее, чтобы загрузить/извлечь драйвер в/из Linux, необходимо реализовать указанные в структуре skel_gpio_driver методы .probe и .remove.
Функция skel_gpio_remove просто удаляет зарегистрированный GPIO драйвер из ядра, поэтому рассмотрим основные моменты в skel_gpio_probe:
- devm_kzalloc — выделяет память под структуру skel_gpio_chip;
- platform_get_resource — читает адрес начала регистровой карты GPIO из devicetree;
- devm_ioremap_resource — выполняет mapping физического адреса на виртуальный;
- of_property_read_u32 — читает количество доступных GPIO из devicetree;
- skel_gc->gchip.* — заполняет необходимые для работы поля структуры;
- gpiochip_add — добавляет GPIO контроллер в драйвер;
До сих пор не было описано почему же используется такие магические числа как 248… 255. Запись skel_gc->gchip.base = -1; просит ядро динамически выделить номера используемых GPIO. Чтобы узнать данные номера в конце драйвера добавлен вывод:
Конечно, Linux предоставляет возможность задать номера вручную, но давайте посмотрим на комментарий в исходном коде:
Шаг четвертый
Рассмотрим функциональную часть драйвера, а именно реализуем следующие методы:
.direction_output, .direction_input, .get и .set. Далее будет показан аппаратно-зависимый код, который в большинстве случаев будет отличаться.
Метод skel_gpio_direction_input выполняет следующие действия:
- Вызывается при следующей команде echo «in» > /sys/class/gpio/gpioN/direction;
- Считывает регистр SKEL_GPIO_PAD_DIR, который отвечает за установку направления пина GPIO;
- Устанавливает необходимую маску;
- Записывает полученное значение обратно в SKEL_GPIO_PAD_DIR.
Метод skel_gpio_direction_output выполняет действия аналогичные skel_gpio_direction_inut за исключением того, что вызывается при следующих командах:
- echo «out» > /sys/class/gpio/gpioN/direction;
- echo «high» > /sys/class/gpio/gpioN/direction, при этом устанавливает значение value в 1;
- echo «low» > /sys/class/gpio/gpioN/direction, при этом устанавливает значение value в 0.
value — значение, определяющее уровень сигнала на выходной линии.
Метод skel_gpio_set выполняет следующие действия:
- Вызывается при следующей команде echo 1/0 > /sys/class/gpio/gpioN/value;
- Считывает регистр SKEL_GPIO_WR_DATA, который показывает значение текущего сигнала на линии;
- Устанавливает или сбрасывает необходимый бит по offset;
- Записывает полученное значение обратно в SKEL_GPIO_WR_DATA.
Метод skel_gpio_get считывает значение сигнала на линии, прочитав регистр SKEL_GPIO_RD_DATA.
После того как мы описали все необходимые методы и структуры, можно собрать все вместе и взглянуть на итоговый вариант.
Реализованный драйвер содержит необходимый функционал для управления GPIO, но в данный момент в драйвере отсутствует поддержка работы с прерываниями, поэтому можно перейти к следующему шагу.
Шаг пятый
Добавление IRQ в GPIO драйвер можно разделить на три шага:
- Описание поддерживаемых методов в структурах данных ядра;
- Включение поддержки IRQ в момент загрузки драйвера в систему;
- Реализация поддерживаемых методов.
Первоначально опишем необходимый набор операций:
Следовательно драйвер может разрешать(skel_gpio_irq_unmask)/запрещать(skel_gpio_irq_mask) прерывания и указать тип события по которому оно будет генерироваться (skel_gpio_irq_set_type).
Далее опишем единственный метод, который отвечает за сопоставление виртуального irq number с аппаратным.
Затем укажем ядру, что загружаемый драйвер поддерживает работу с IRQ. Для этого необходимо добавить в probe функцию следующий код:
В выше приведенном коде происходит:
- Выделение и инициализация области под irq_domain;
- Считывание номера прерывания с devicetree;
- mapping между виртуальным и аппаратным прерыванием;
- Регистрация обработчика прерывания и установка данных на передачу в обработчик;
Приступим к реализации некоторых выше описанных методов.
skel_gpio_to_irq — создает mapping между аппаратным и виртуальным прерыванием. Если же данный mapping уже был создан, то возвращает номер созданного виртуального прерывания.
skel_irq_handler — обработчик прерывания, который:
- Считывает регистр статуса прерывания;
- Считывает регистр маски прерывания;
- Выделяет прерывания ожидающие обработки;
- Для каждого GPIO в котором возникло прерывание вызывает generic_handle_irq.
Вот и все, в данной статье мы узнали как происходит взаимодействие GPIO драйвера с виртуальной файловой системой sysfs, реализовали базовую структуру GPIO драйвера, а также рассмотрели методы которые требуются для поддержки IRQ.
В статье не приведена реализация методов skel_gpio_irq_unmask, skel_gpio_irq_mask и skel_gpio_irq_set_type по двум причинам. Во-первых, данные методы просты в реализации. Во-вторых, аппаратно-зависимы. Они отвечают за разрешение или запрет прерываний по определенным событиям, которые поддерживает GPIO контроллер.
Пожалуйста, если вы нашли ошибки/неточности, или вам есть что добавить — напишите в ЛС или в комментарии.
Источник
Пишем простой модуль ядра Linux

Захват Золотого Кольца-0
Linux предоставляет мощный и обширный API для приложений, но иногда его недостаточно. Для взаимодействия с оборудованием или осуществления операций с доступом к привилегированной информации в системе нужен драйвер ядра.
Модуль ядра Linux — это скомпилированный двоичный код, который вставляется непосредственно в ядро Linux, работая в кольце 0, внутреннем и наименее защищённом кольце выполнения команд в процессоре x86–64. Здесь код исполняется совершенно без всяких проверок, но зато на невероятной скорости и с доступом к любым ресурсам системы.
Не для простых смертных
Написание модуля ядра Linux — занятие не для слабонервных. Изменяя ядро, вы рискуете потерять данные. В коде ядра нет стандартной защиты, как в обычных приложениях Linux. Если сделать ошибку, то повесите всю систему.
Ситуация ухудшается тем, что проблема необязательно проявляется сразу. Если модуль вешает систему сразу после загрузки, то это наилучший сценарий сбоя. Чем больше там кода, тем выше риск бесконечных циклов и утечек памяти. Если вы неосторожны, то проблемы станут постепенно нарастать по мере работы машины. В конце концов важные структуры данных и даже буфера могут быть перезаписаны.
Можно в основном забыть традиционные парадигмы разработки приложений. Кроме загрузки и выгрузки модуля, вы будете писать код, который реагирует на системные события, а не работает по последовательному шаблону. При работе с ядром вы пишете API, а не сами приложения.
У вас также нет доступа к стандартной библиотеке. Хотя ядро предоставляет некоторые функции вроде printk (которая служит заменой printf ) и kmalloc (работает похоже на malloc ), в основном вы остаётесь наедине с железом. Вдобавок, после выгрузки модуля следует полностью почистить за собой. Здесь нет сборки мусора.
Необходимые компоненты
Прежде чем начать, следует убедиться в наличии всех необходимых инструментов для работы. Самое главное, нужна машина под Linux. Знаю, это неожиданно! Хотя подойдёт любой дистрибутив Linux, в этом примере я использую Ubuntu 16.04 LTS, так что в случае использования других дистрибутивов может понадобиться слегка изменить команды установки.
Во-вторых, нужна или отдельная физическая машина, или виртуальная машина. Лично я предпочитаю работать на виртуальной машине, но выбирайте сами. Не советую использовать свою основную машину из-за потери данных, когда сделаете ошибку. Я говорю «когда», а не «если», потому что вы обязательно подвесите машину хотя бы несколько раз в процессе. Ваши последние изменения в коде могут ещё находиться в буфере записи в момент паники ядра, так что могут повредиться и ваши исходники. Тестирование в виртуальной машине устраняет эти риски.
И наконец, нужно хотя бы немного знать C. Рабочая среда C++ слишком велика для ядра, так что необходимо писать на чистом голом C. Для взаимодействия с оборудованием не помешает и некоторое знание ассемблера.
Установка среды разработки
На Ubuntu нужно запустить:
Устанавливаем самые важные инструменты разработки и заголовки ядра, необходимые для данного примера.
Примеры ниже предполагают, что вы работаете из-под обычного пользователя, а не рута, но что у вас есть привилегии sudo. Sudo необходима для загрузки модулей ядра, но мы хотим работать по возможности за пределами рута.
Начинаем
Приступим к написанию кода. Подготовим нашу среду:
Запустите любимый редактор (в моём случае это vim) и создайте файл lkm_example.c следующего содержания:
Мы сконструировали самый простой возможный модуль, рассмотрим подробнее самые важные его части:
- В include перечислены файлы заголовков, необходимые для разработки ядра Linux.
- В MODULE_LICENSE можно установить разные значения, в зависимости от лицензии модуля. Для просмотра полного списка запустите:
Впрочем, пока мы не можем скомпилировать этот файл. Нужен Makefile. Такого базового примера пока достаточно. Обратите внимание, что make очень привередлив к пробелам и табам, так что убедитесь, что используете табы вместо пробелов где положено.
Если мы запускаем make , он должен успешно скомпилировать наш модуль. Результатом станет файл lkm_example.ko . Если выскакивают какие-то ошибки, проверьте, что кавычки в исходном коде установлены корректно, а не случайно в кодировке UTF-8.
Теперь можно внедрить модуль и проверить его. Для этого запускаем:
Если всё нормально, то вы ничего не увидите. Функция printk обеспечивает выдачу не в консоль, а в журнал ядра. Для просмотра нужно запустить:
Вы должны увидеть строку “Hello, World!” с меткой времени в начале. Это значит, что наш модуль ядра загрузился и успешно сделал запись в журнал ядра. Мы можем также проверить, что модуль ещё в памяти:
Для удаления модуля запускаем:
Если вы снова запустите dmesg, то увидите в журнале запись “Goodbye, World!”. Можно снова запустить lsmod и убедиться, что модуль выгрузился.
Как видите, эта процедура тестирования слегка утомительна, но её можно автоматизировать, добавив:
в конце Makefile, а потом запустив:
для тестирования модуля и проверки выдачи в журнал ядра без необходимости запускать отдельные команды.
Теперь у нас есть полностью функциональный, хотя и абсолютно тривиальный модуль ядра!
Немного интереснее
Копнём чуть глубже. Хотя модули ядра способны выполнять все виды задач, взаимодействие с приложениями — один из самых распространённых вариантов использования.
Поскольку приложениям запрещено просматривать память в пространстве ядра, для взаимодействия с ними приходится использовать API. Хотя технически есть несколько способов такого взаимодействия, наиболее привычный — создание файла устройства.
Вероятно, раньше вы уже имели дело с файлами устройств. Команды с упоминанием /dev/zero , /dev/null и тому подобного взаимодействуют с устройствами “zero” и “null”, которые возвращают ожидаемые значения.
В нашем примере мы возвращаем “Hello, World”. Хотя это не особенно полезная функция для приложений, она всё равно демонстрирует процесс взаимодействия с приложением через файл устройства.
Вот полный листинг:
Тестирование улучшенного примера
Теперь наш пример делает нечто большее, чем просто вывод сообщения при загрузке и выгрузке, так что понадобится менее строгая процедура тестирования. Изменим Makefile только для загрузки модуля, без его выгрузки.
Теперь после запуска make test вы увидите выдачу старшего номера устройства. В нашем примере его автоматически присваивает ядро. Однако этот номер нужен для создания нового устройства.
Возьмите номер, полученный в результате выполнения make test , и используйте его для создания файла устройства, чтобы можно было установить коммуникацию с нашим модулем ядра из пространства пользователя.
(в этом примере замените MAJOR значением, полученным в результате выполнения make test или dmesg )
Параметр c в команде mknod говорит mknod, что нам нужно создать файл символьного устройства.
Теперь мы можем получить содержимое с устройства:
или даже через команду dd :
Вы также можете получить доступ к этому файлу из приложений. Это необязательно должны быть скомпилированные приложения — даже у скриптов Python, Ruby и PHP есть доступ к этим данным.
Когда мы закончили с устройством, удаляем его и выгружаем модуль:
Заключение
Надеюсь, вам понравились наши шалости в пространстве ядра. Хотя показанные примеры примитивны, эти структуры можно использовать для создания собственных модулей, выполняющих очень сложные задачи.
Просто помните, что в пространстве ядра всё под вашу ответственность. Там для вашего кода нет поддержки или второго шанса. Если делаете проект для клиента, заранее запланируйте двойное, если не тройное время на отладку. Код ядра должен быть идеален, насколько это возможно, чтобы гарантировать цельность и надёжность систем, на которых он запускается.
Источник



