- Понять перезагрузку системы для Azure VM
- Настройка VMs для высокой доступности
- Сведения о здоровье ресурсов
- Действия и события, которые могут привести к перезагрузке VM
- Плановое обслуживание
- Обновления для сохранения памяти
- Инициированные пользователем действия перезагрузки или остановки
- Центр безопасности Azure и обновление Windows
- Другие ситуации, влияющие на доступность вашего VM
- Ошибки сервера хост
- Автоматическое восстановление
- Незапланированное обслуживание
- Сбои в VM
- Принудительное отключение, связанное с хранением
- Другие инциденты
- Перезагрузка виртуальной машины windows
- Описание проблемы
- Как перезапустить зависшую виртуальную машину
- Висит задача create virtual machine snapshot
Понять перезагрузку системы для Azure VM
Виртуальные машины Azure (виртуальные машины) иногда могут быть перезагрузками без видимых причин без подтверждения того, что вы инициировали операцию перезагрузки. В этой статье перечислены действия и события, которые могут привести к перезагрузке VMs, и содержится представление о том, как избежать непредвиденных проблем перезагрузки или уменьшить влияние таких проблем.
Настройка VMs для высокой доступности
Лучший способ защитить приложение, которое работает в Azure, от перезагрузок и простоев VM— настроить VMs для высокой доступности.
Чтобы обеспечить такой уровень избыточности для приложения, рекомендуется группу двух или более компьютеров в наборе доступности. Эта конфигурация гарантирует, что во время запланированного или незапланированного события обслуживания по крайней мере один VM доступен и соответствует 99,95% SLA Azure.
Дополнительные сведения о наборах доступности см. в документе Управление доступностью VMs
Сведения о здоровье ресурсов
Azure Resource Health — это служба, которая предоставляет защиту отдельных ресурсов Azure и предоставляет рекомендации по устранению неполадок. В облачной среде, где невозможно напрямую получить доступ к серверам или элементам инфраструктуры, задача службы Resource Health заключается в сокращении времени, которое вы тратите на устранение неполадок. В частности, цель заключается в сокращении времени, которое вы тратите на определение того, лежит ли корень проблемы в приложении или в событии внутри платформы Azure. Дополнительные сведения см. в дополнительных сведениях, которые см. в «Понять и использовать здоровье ресурсов».
Действия и события, которые могут привести к перезагрузке VM
Плановое обслуживание
Microsoft Azure периодически выполняет обновления по всему миру для повышения надежности, производительности и безопасности инфраструктуры хостов, которая лежит в основе VMs. Многие из этих обновлений, включая обновления с сохранением памяти, выполняются без какого-либо влияния на ваши VMs или облачные службы.
Однако некоторые обновления требуют перезагрузки. В таких случаях VMs закрываются во время исправления инфраструктуры, а затем перезапущены.
Чтобы понять, что такое запланированное обслуживание Azure и как оно может повлиять на доступность ваших VMs Linux, см. в статьях, перечисленных здесь. В статьях данная статья посвящена процессу планового обслуживания Azure и планированию запланированного обслуживания для дальнейшего снижения воздействия.
Обновления для сохранения памяти
Для этого класса обновлений в Microsoft Azure пользователи не оказывают влияния на работающие VMs. Многие из этих обновлений — это компоненты или службы, которые можно обновить, не меся с запущенным экземпляром. Некоторые из них — обновления инфраструктуры платформы в операционной системе хост, которые можно применять без перезагрузки VMs.
Эти обновления для сохранения памяти выполняются с помощью технологии, которая позволяет выполнять живую миграцию на месте. При обновлении VM помещается в приостановленное состояние. Это состояние сохраняет память в оперативной памяти, в то время как операционная система принимающей системы получает необходимые обновления и исправления. VM возобновляется в течение 30 секунд после приостановки. После возобновления работы VM его часы автоматически синхронизируются.
Из-за короткого периода паузы развертывание обновлений с помощью этого механизма значительно снижает влияние на VMs. Однако не все обновления можно развернуть таким образом.
Обновления нескольких экземпляров (для VMs в наборе доступности) применяются по одному домену обновления одновременно.
Машины Linux со старыми версиями ядра подвержены панике ядра во время этого метода обновления. Чтобы избежать этой проблемы, обновим версию ядра 3.10.0-327.10.1 или более поздней версии. Дополнительные сведения см. в примере Azure Linux VM на основе 3.10после обновления узла узла.
Инициированные пользователем действия перезагрузки или остановки
При перезагрузке с портала Azure, Azure PowerShell, интерфейса командной строки или API REST вы можете найти событие в журнале активности Azure.
Если выполнить действие из операционной системы VM, событие можно найти в системных журналах.
Другие сценарии, которые обычно вызывают перезагрузку VM, включают несколько действий по изменению конфигурации. Обычно вы увидите предупреждающее сообщение, указывающее, что выполнение определенного действия приведет к перезагрузке VM. В качестве примеров можно привести любые операции по замене VM, изменение пароля административной учетной записи и установка статического IP-адреса.
Центр безопасности Azure и обновление Windows
Центр безопасности Azure отслеживает ежедневные VMs Windows и Linux для отсутствующих обновлений операционной системы. Центр безопасности извлекает список доступных обновлений безопасности и критически важных обновлений из Windows Update или cлужбы Windows Server Update Services (WSUS), в зависимости от того, какая служба настроена на Windows VM. Центр безопасности также проверяет последние обновления для систем Linux. Если вашему компьютеру не хватает обновления системы, Центр безопасности рекомендует применять обновления системы. Применение этих системных обновлений контролируется через Центр безопасности на портале Azure. После применения некоторых обновлений может потребоваться перезагрузка VM. Дополнительные сведения см. в дополнительных сведениях: Применениеобновлений системы в Центре безопасности Azure.
Как и на локальном сервере, Azure не выдвигает обновления из Windows Update в windows VMs, так как эти машины предназначены для использования пользователями. Однако рекомендуется оставить включенную автоматическую настройку обновления Windows. Автоматическая установка обновлений из Обновления Windows также может привести к перезагрузам после их установки. Дополнительные сведения см. в faq обновления Windows.
Другие ситуации, влияющие на доступность вашего VM
Есть и другие случаи, когда Azure может активно приостанавливать использование VM. Вы будете получать уведомления электронной почты перед этим действием, так что у вас будет возможность устранить проблемы, которые находятся в его данной области. Примеры проблем, влияющих на доступность VM, включают нарушения безопасности и истечение срока действия способов оплаты.
Ошибки сервера хост
VM находится на физическом сервере, который работает внутри центра обработки данных Azure. На физическом сервере помимо нескольких других компонентов Azure выполняется агент, называемый агентом-хостом. Когда эти компоненты программного обеспечения Azure на физическом сервере становятся безответными, система мониторинга запускает перезагрузку хост-сервера для попытки восстановления. Как правило, VM снова доступен в течение пяти минут и продолжает жить на том же хосте, что и ранее.
Ошибки сервера обычно вызваны сбоем оборудования, например сбоем жесткого диска или твердого диска. Azure непрерывно отслеживает эти случаи, определяет основные ошибки и выполняет обновления после внедрения и тестирования смягчения последствий.
Так как некоторые ошибки сервера хост-сервера могут быть специфичные для этого сервера, повторная ситуация перезагрузки VM может быть улучшена вручную, передиплотив VM на другой хост-сервер. Эта операция может быть вызвана с помощью параметра переделокации на странице сведений VM или остановки и перезапуска VM на портале Azure.
Автоматическое восстановление
Если сервер хост-сервера не может перезагрузки по какой-либо причине, платформа Azure инициирует действие автоматического восстановления, чтобы выведет неисправный хост-сервер из ротации для дальнейшего расследования.
Все VMs на этом хосте автоматически перенастрояются на другой здоровый сервер. Этот процесс обычно завершается в течение 15 минут. Дополнительные информацию о процессе автоматического восстановления см. в автозапевке VMs.
Незапланированное обслуживание
В редких случаях группе операций Azure может потребоваться выполнить действия по обслуживанию, чтобы обеспечить общее состояние платформы Azure. Это поведение может повлиять на доступность VM, и обычно приводит к такому же действию автоматического восстановления, как описано ранее.
Внеплановая поддержка включает в себя следующие:
- Срочная дефрагментация узлов
- Срочные обновления сетевого коммутатора
Сбои в VM
VMs может перезапуститься из-за проблем в самом VM. Рабочая нагрузка или роль, выполняемая в VM, может вызвать проверку ошибок в гостевой операционной системе. Для справки о причинах сбоя просмотреть журналы систем и приложений для VMs Windows и серийные журналы для VMs Linux.
Принудительное отключение, связанное с хранением
Виртуальные виртуальные диски в Azure используют виртуальные диски для операционной системы и хранения данных, которые будут организованы в инфраструктуре хранения Azure. Всякий раз, когда на доступность или подключение между виртуальными и связанными виртуальными дисками влияет более 120 секунд, платформа Azure выполняет принудительное отключение виртуальных компьютеров, чтобы избежать повреждения данных. После восстановления подключения к хранилищам автоматически подключаются VMs.
Продолжительность остановки может быть не более пяти минут, но может быть значительно больше. Ниже приводится один из конкретных случаев, связанных с принудительной остановкой хранения:
Превышение ограничений IO
VMs могут быть временно закрыты, когда запросы I/O последовательно отключались, так как объем операций I/O в секунду (IOPS) превышает ограничения I/O для диска. (Стандартное хранилище дисков ограничено 500 IOPS.) Чтобы устранить эту проблему, используйте полосу диска или настройте пространство для хранения внутри гостевого VM в зависимости от рабочей нагрузки.
Другие инциденты
В редких случаях распространенная проблема может затронуть несколько серверов центра обработки данных Azure. Если эта проблема возникает, команда Azure отправляет уведомления по электронной почте затронутым подпискам. Вы можете проверить информационную панель службы Azure и портал Azure о состоянии текущих отключений и прошлых инцидентов.
Перезагрузка виртуальной машины windows
Добрый день! Уважаемые читатели и гости IT блога Pyatilistnik.org. В прошлый раз мы с вами разобрали, вопрос как изменить формат файла в операционных системах Windows. Сегодня я хочу вам рассказать еще об одной интересной и уже порядком часто встречающейся проблеме, как зависание виртуальной машины Vmware ESXI при попытке ее выключить или перезагрузить, так же может быть ошибка «Another task is already in progress«. Давайте разбираться, как можно выкрутиться из такой ситуации.
Описание проблемы
Как я и писал выше есть хост с установленным гипервизором Vmware ESXI 6.5. В какой-то момент система мониторинга присылает сообщение, о том, что одна из виртуальных машин не доступна. Подключившись к vCenter серверу виртуальный сервер имел статус «Power On», «Web Console» так же не отвечала. Я попытался сделать ей принудительное завершение (Power Off), но эффекта это не дало, у меня выскочила ошибка «Cannot power off«
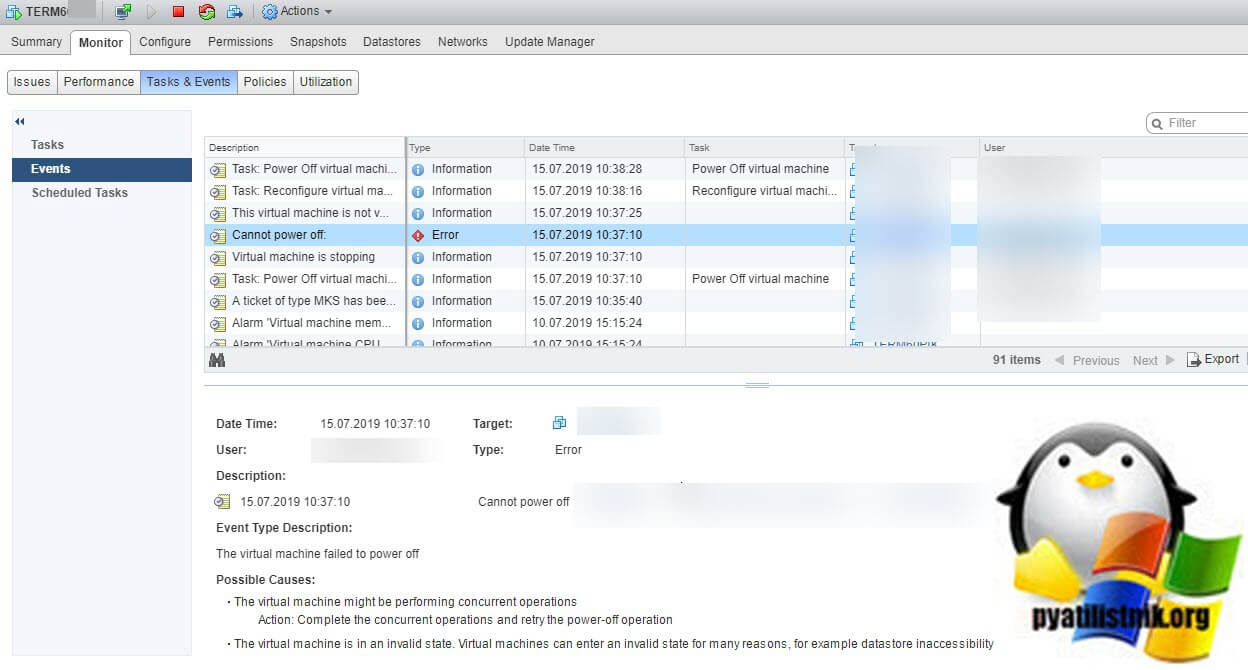
При попытке мигрировать виртуальную машину вы может получить ошибку:
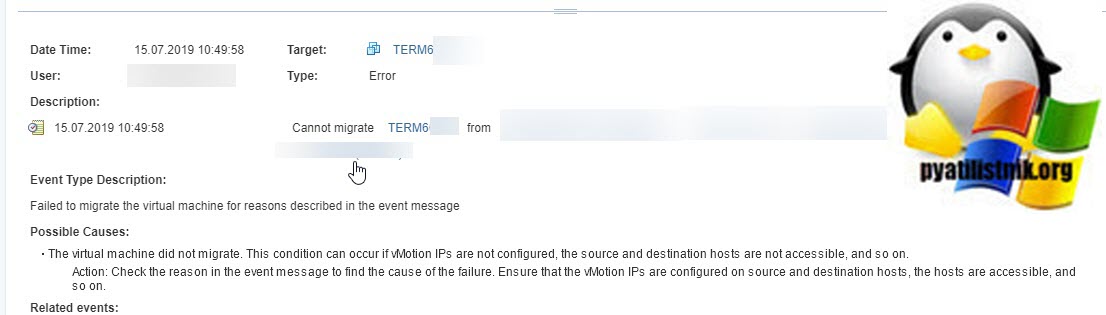
Так же вы можете увидеть ошибку при попытке, выключить или перезапустить виртуалку:
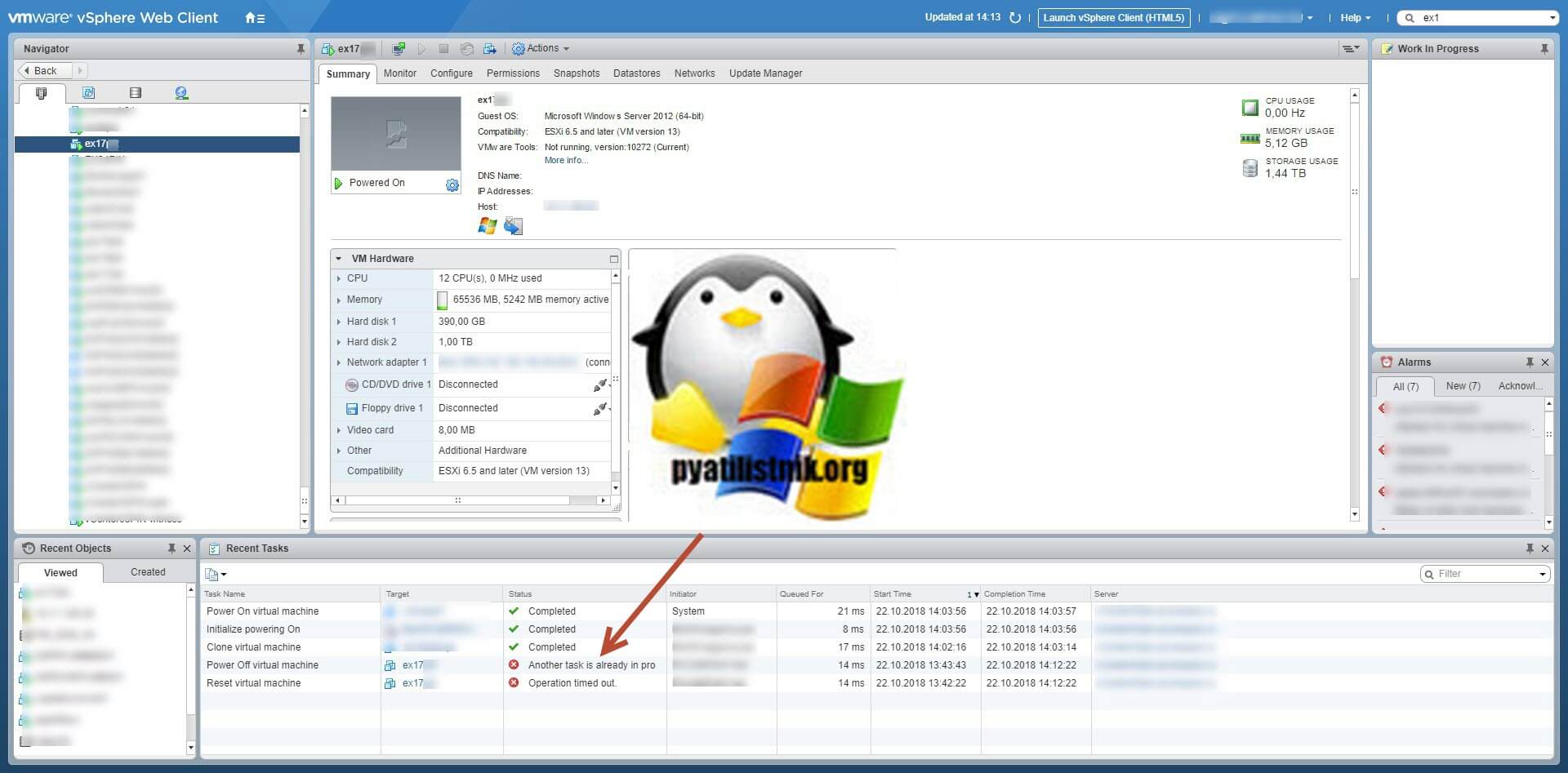
Во всех случаях вам скажут, что данная виртуальная машина имеет некий процесс, который в данный момент не дает выполнить ваши повторные действия. Так же данная виртуалка у меня была членом RDS фермы, при попытке перевода его в режим стока (Drain-Mode) я получил ошибку «Не удалось изменить состояние подключения для сервера».
Как перезапустить зависшую виртуальную машину
Сразу хочу отметить, что если в графическом интерфейсе у вас не выходит, что либо сделать, то у вас остается только командная строка ssh. Включаем на ESXI хосте SSH службу. Далее подключаемся через Putty или MremoteNG. Я подключаюсь через MremoteNG. Первое, что вам необходимо сделать, это как посмотреть список активных процессов, все как в Windows. Для этого есть команда:
В моем примере, я вижу свою виртуальную машину TERM6. Если системные процессы мозолят вам глаза, то вы можете одновременно нажать SHIFT+V, что оставит отображение только виртуальных машин.
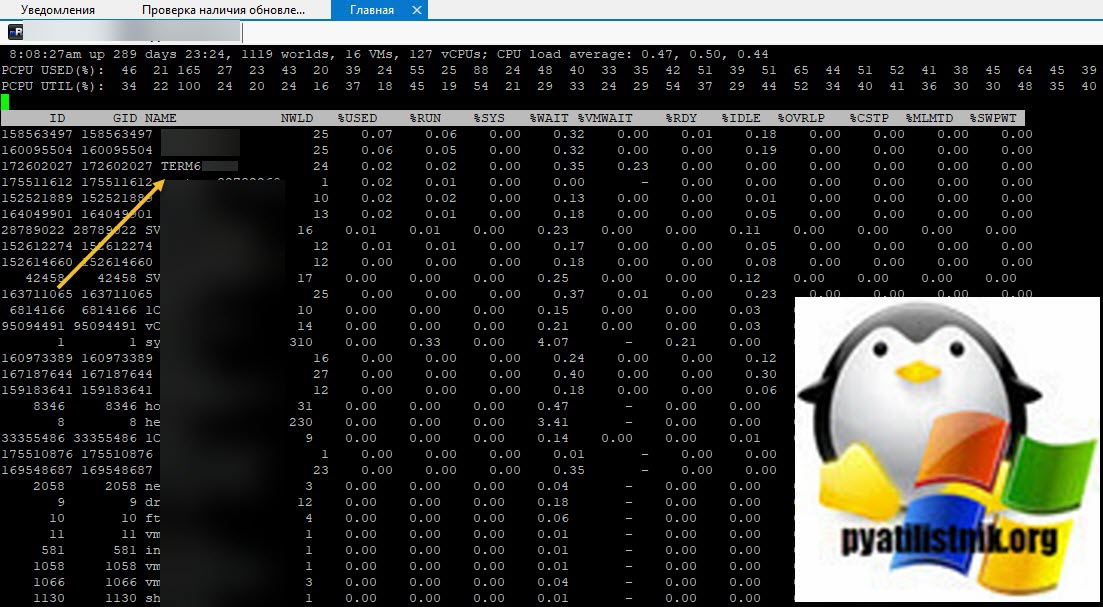
Теперь нам нужно вычислить LWID — Leader World Id, завершив который вы завершите работу нужной виртуалки. ПО умолчанию LWID не отображается, чтобы его включить нажмите клавишу F. У вас откроется меню, где можно добавлять или скрывать поля. Видим, что если нажать клавишу «C«, то у вас будет добавлен LWID- Leader World Id. Нажимаем «C» и «Enter«.
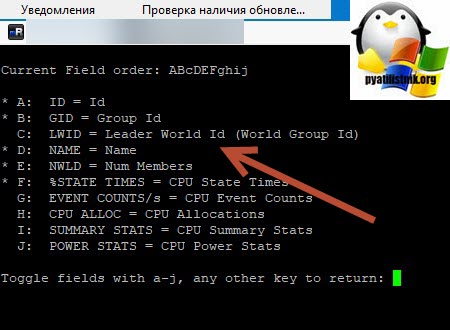
Теперь зная LWID, нажмите клавишу «K«, она вызовет меню «World to kill (WID)», данная операция поможет принудительно завершить процесс LWID. Вбиваем наш LWID и нажимаем «Enter».
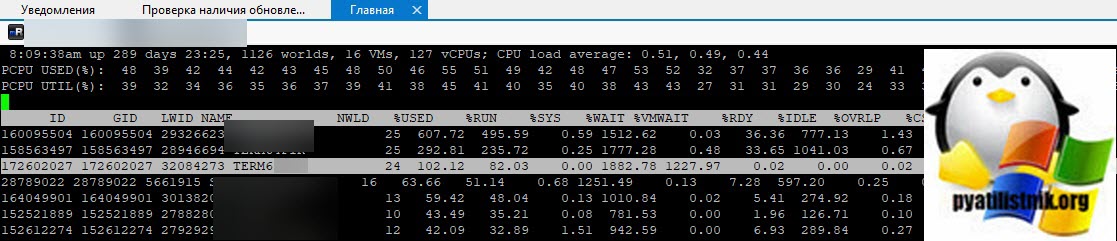
Тут у вас два варианта, чудо произошло (80% вероятности) и чудо не произошло, часто бывает в случаях с ошибкой «Another task is already in progress«
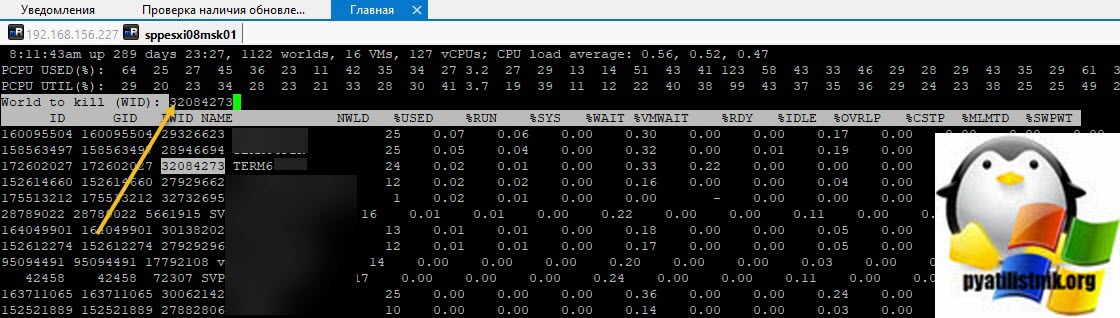
Кстати World ID можно вычисли и просто введя команду:
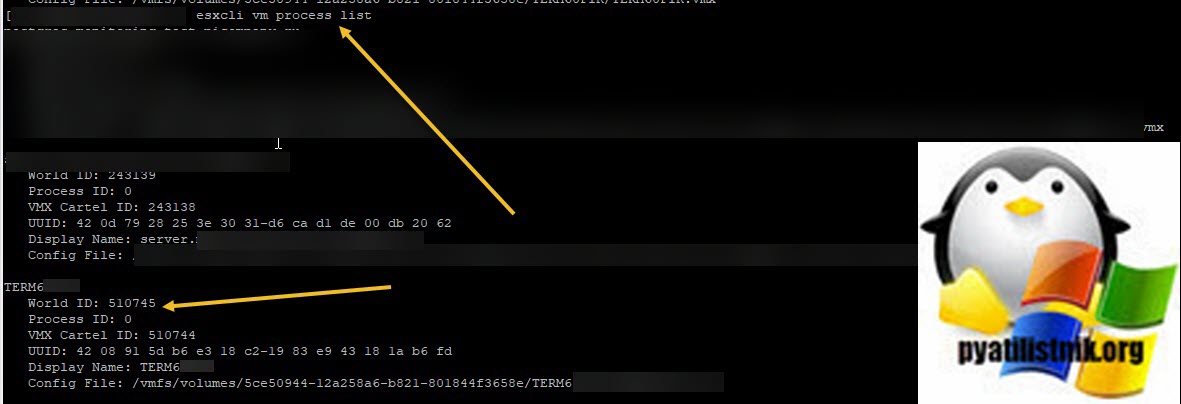
Там вы сможете увидеть World ID, после чего его можно убить командой:
В моем случае чудо произошло, виртуалка перешла в состояние Power OFF, я это вижу в Power-CLI.
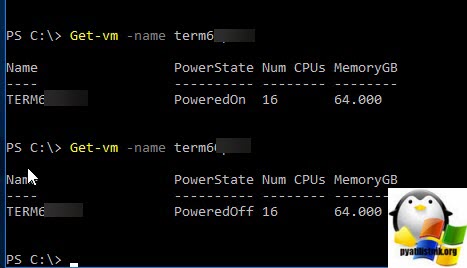
Если принудительное завершение процесса вам не помогло, то делаем вот что, по возможности мигрируйте все остальные виртуальные машины с данного хоста, у вас из-за ошибки останется только сбойная. Все в том же SSH. введите:
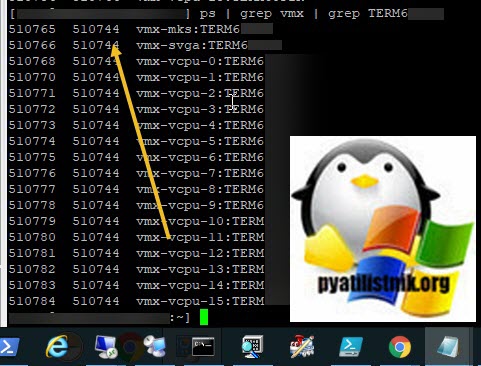
В итоге у вас будет выведен список, где первая колонка это PID процесса, вторая PID родительского процесса, убиваем его для вашей виртуальной машины.
После чего пишем kill PID-родительского процесса. Если не помогло, то пробуем выполнить вот, что (по возможности перевезите другие сервера с данного хоста на другие хосты)
В результате действий хост стал работать нормально, единственное может быть ситуация, что виртуалку придется удалить из inventory и добавить заново. Если и это не помогло, то попробуйте выполнить:
Висит задача create virtual machine snapshot
Еще в своей практике встречал ситуации, что из-за незаконченного задания у меня не выполнялось резервное копирование, задание висело со статусом «create virtual machine snapshot»

Так же вычисляем родительский PID подключившись по SSH, после его завершения, вы увидите сообщение, которое покажет, что с виртуальной машиной теперь можно взаимодействовать.



