- Распараллеливание задач в Linux
- Первый способ: распараллеливание средствами mencoder
- Второй способ: распараллеливание средствами Bash
- Третий способ: распараллеливание средствами GNU make
- PDSH: Параллельное выполнение команд на нескольких Linux-серверах
- Установка PDSH и дополнительных модулей
- Настройка сервера управления pdsh и управляемых Linux-серверов.
- Примеры использования pdsh для запуска команд на множестве серверов
- Многозадачность в shell-скриптах
- JOB CONTROL
- Завершение фоновых процессов
- Процессы
- Запуск дочерних процессов
- Сигналы
Распараллеливание задач в Linux
Потребовалось мне перекодировать некоторое количество видео-файлов. Для этого я написал следующий сценарий:
recode() <
mencoder -o $2 $1 -ovc x264 -x264encopts bitrate=22000:keyint=50 -oac mp3lame -lameopts vbr=3:br=320 -fps 50
>
recode input/00108.mts 00108.avi
recode input/00109.mts 00109.avi
.
.
Казалось-бы все готово, но я заметил, что загружен только один процессор из двух, а это значит, что этот процесс можно ускорить, раза в два.
Первый способ: распараллеливание средствами mencoder
Можно задать опции mencoder. Для x264 кодека есть возможность указать количество потоков:
- threads=
Использовать потоки для кодирования одновременно на нескольких процессорах (по умолчанию: 1). Это немного ухудшает качество кодирования. 0 или ‘auto’ — автоматически определить количество процессоров и использовать соответствующее количество потоков.
Способ хороший, но не универсальный и возможно ухудшение качества результата.
Второй способ: распараллеливание средствами Bash
Способ прост, запускаем процессы параллельно, например так:
(recode input/00108.mts 00108.avi
recode input/00109.mts 00109.avi
.
. ) &
(recode input/00108.mts 00110.avi
recode input/00109.mts 00111.avi
.
. )
Недостаток метода в том, что из-за того что файлы разного размера, время на их обработку может существенно различаться и в итоге один процессор может разгрузиться значительно раньше другого.
Третий способ: распараллеливание средствами GNU make
Мне хотелось каким-то образом улучшить сценарий, чтобы всегда параллельно работало две задачи и по мере их завершения запускались новые. Размышляя как бы мне это сделать, я вспомнил, что существует замечательная утилита сборки, которая может делать именно то, что мне надо. Получилось следующее:
all: 00108.avi 00109.avi 00110.avi 00111.avi 00118.avi 00119.avi 00120.avi 00123.avi
Получилось на удивление просто и коротко. В начале перечисляется список всех файлов, которые я хочу получить. За ним следует путь до исходных файлов и правило сборки. Запускать командой «make -j 2», чтобы работало одновременно 2 процесса.
Источник
PDSH: Параллельное выполнение команд на нескольких Linux-серверах
В данной статье я расскажу вам, как управлять большим парком Linux серверов из консоли одного сервера, выполнять удаленно команды на других серверах и получать их результаты, проверять состояние серверов и выполнять параллельно однотипные работы с помощью утилиты pdsh. Разберемся в ее установке, настройке и параллельном запуске команд на нескольких серверах.
PDSH (parallel distributed shell) — высокопроизводительная утилита для параллельного запуска команд на большом количестве Linux-серверов через ssh. По умолчанию pdsh позволяет поддерживать 32 параллельных соединения с управляемыми северами. Для pdsh есть несколько полезных модулей расширения, которые мы также рассмотрим в этой статье.
С помощью pdsh вы можете:
- Обновлять ПО на серверах;
- Установить необходимые модули или утилиты;
- Запустить какой-то bash скрипт;
- Проверить наличие обновлений и многое другое.
Установка PDSH и дополнительных модулей
Сначала нужно установить утилиту pdsh и нужные модули. В CentOS установка выполняется через менеджер пакетов yum:
yum install epel-release -y – подключаем репозиторий Epel
yum install pdsh pdsh-mod-genders -y — устанавливаем pdsh и модуль genders для него.
В целом для настройки pdsh больше ничего и не нужно. Мы установили сам pdsh, а так же установили дополнительный модуль pdsh-mod-genders, о котором я расскажу чуть позже, когда мы перейдем к запуску команд на удаленных серверах.
Настройка сервера управления pdsh и управляемых Linux-серверов.
Чтобы не вводить каждый раз пароли для подключения к удаленным серверам, мы выполним генерацию ключа ssh на сервере управления с установленным pdsh и добавим его на управляемые сервера.
Запустив команду ssh-keygen -q на все вопросы просто жмем Enter. Ключ готов, теперь осталось скопировать его на управляемые Linux-сервера. В качестве примера я взял 2 сервера с Linux CentOS.
На управляемых серверах создайте директорию для ssh ключа (если таковой нет):
Скопируем ключ в данный каталог, я это делаю через echo:
echo -e «ваш ключ с файла /root/.ssh/id_rsa.pub» >> /root/.ssh/authorized_keys

Ключ добавлен, нужно проверить проходит ли соединение с pdsh-сервера:
Примеры использования pdsh для запуска команд на множестве серверов
Так как ряд серверов может отличаться по hostname , я для себя сделал такую схему настройки PDSH. В файл hosts на управляющем сервере с pdsh я добавляю каждый управляемый сервер и присваиваю ему удобное мне имя, например:
Где вместо звездочек нужно указать IP destination-серверов.
Чтобы pdsh мог подключиться на заданные имена серверов, в файле /root/ssh/known_hosts к ключу каждого управляемого сервера, через запятую нужно добавить желаемое имя сервера, которое мы указали в /etc/hosts. Например:

После этого вы сможете подключаться по тому hostname, которое выбрали для удобства, это нам пригодится, если у нас будет 100500 серверов, которые именуются вразнобой.
Для запуска команды на удаленном сервере через pdsh используется такой конструкция:
pdsh -w server1 ‘команда’ — я всегда советую брать в кавычки запускаемые команды, так как если вы будете использовать спецсимволы, bash на сервере с pdsh выполнит команду после спецсимвола локально.
Например, чтобы узнать время на удаленных серверах, можно выполнить команду для каждого из них.
pdsh -w server1 ‘date’
pdsh -w server2 ‘date’
Или выполнить одну команду сразу для списка серверов:
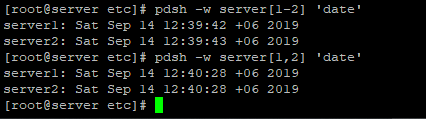
pdsh -w server1,server2 ‘date’
Если нужно выполнить команду на 10-ти серверах, получится довольно длинная команда с перечислением всех серверов, что неудобно. Т.к. мы задали собственные hostname для серверов, и pdsh это понимает, при вызове pdsh можно укажите конкретные сервера или диапазон серверов в квадратных скобках:
pdsh -w server2 ‘date’ — диапазон серверов в моем случае 2 сервера. Может быть от 1 до 20, выглядеть будет так: pdsh -w server3 ‘date’
pdsh -w server[1,2] ‘date’ — конкретные сервера 1 и 2, можно выбрать например 3-4 сервера и команды будет выглядеть следующим образом: pdsh -w server[1,2,7,9] ‘date’
Для более удобного форматирования вывод результатов команд с удаленных серверов можно использовать конструкцию:
pdsh -w server15 ‘uptime’ | sort -n
Рассмотрим ранее установленный модуль pdsh-mod-gendors. Чтобы воспользоваться им, создадим сам файл:
Для чего же он нужен? Genders – это файл с собственным синтаксисом для описания ролей pdsh. Как его можно применить в работе? Например:
- У вас есть 10 серверов с Ubuntu. Мы объединим их в одну группу Ubuntu, пусть их хостнеймы будут ubuntu1-10.
В файл /etc/genders прописываем следующие строки:
Т.е. в файле /etc/genders вы можете создать различные группы Linux серверов. Чтобы pdsh читал данные из файла genders при запуске вместо ключа –w нужно указывать –g.
В моем случае сервера по-прежнему два, но это ничего не меняет:
[root@server etc]# pdsh -g centos ‘date’
Так гораздо удобнее и команда выполняется на всех серверах в группе.
По умолчанию pdsh позволяет запускать до 32 параллельных сессий на разных серверах. Количество одновременно запущенных команд указывается с помощью ключа –f. Например, при -f 1 пока команда не выполнится на первом сервере, ко второму она не перейдет.
На примере нашей команды это выглядит так:
pdsh -g ubuntu ‘date’ -f 1
Так же можно применять ключи -t и -u:
- -t – установить время ожидания подключения в секундах;
- -u – установить время ожидания выполнения удаленной команды.
И в заключении я хотел бы привести несколько примеров, как вы можете использовать pdsh при управлении группами серверов Linux.
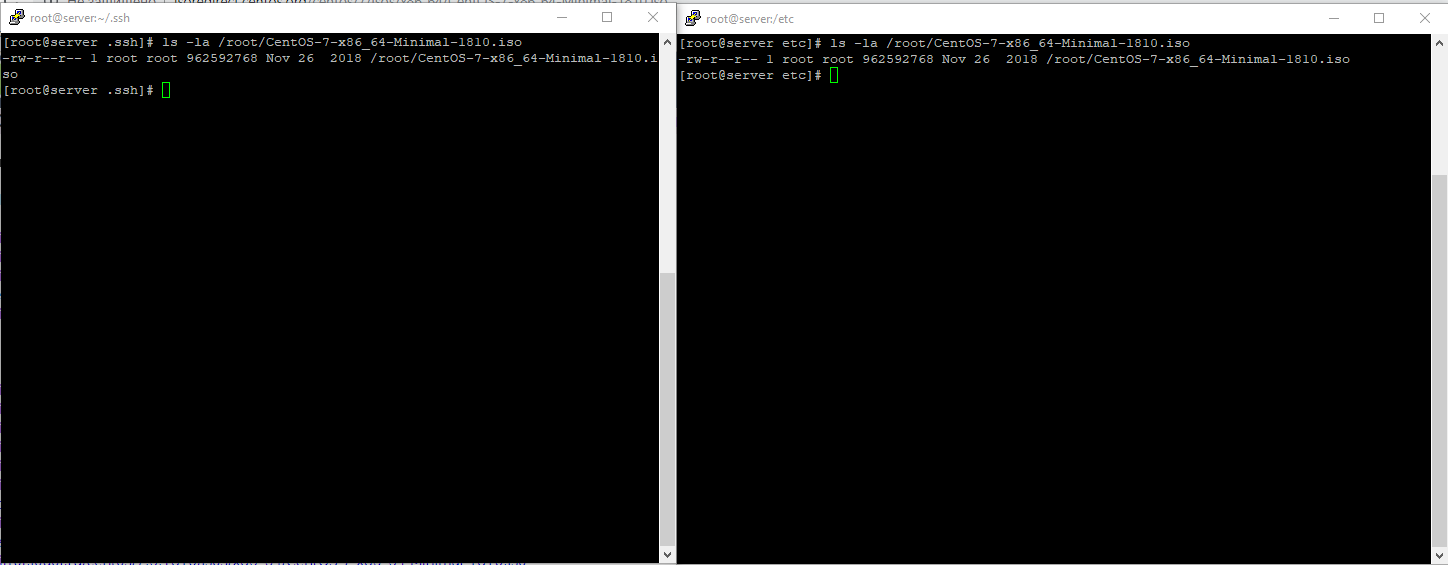
Следующая команда на всех указанных серверха выполнит переход в указанноу нам директорию и скачает в нее iso-образ Centos 7:
pdsh -w server[1,2] ‘cd /root && wget _http://mirror.yandex.ru/centos/7.7.1908/isos/x86_64/CentOS-7-x86_64-Minimal-1908.iso’
Хотите быстро проверить какие репозитории установлены на управляемых серверах?
pdsh -w server[1,2] ‘yum repolist’
pdsh -w server[1,2] ‘yum install httpd -y’ – установка apache на оба сервера
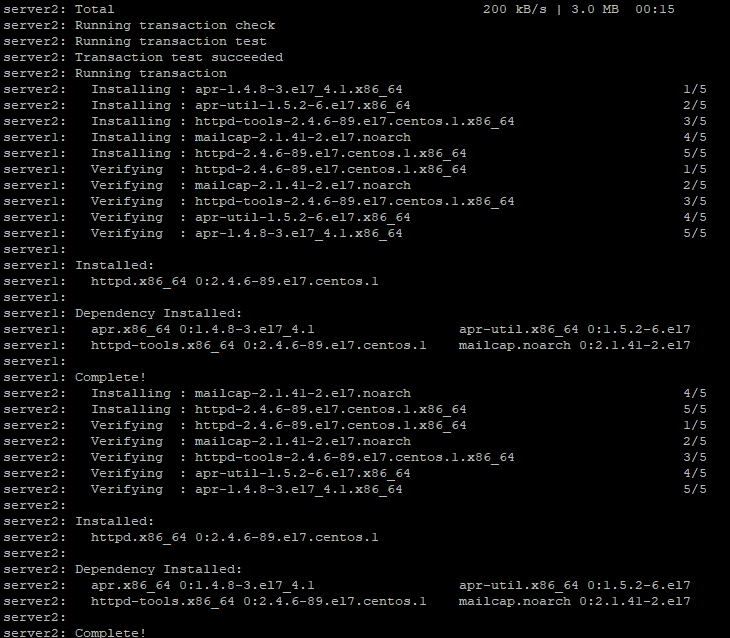
И проверим установилось ли действительно:
То есть, можно выполнить какую угодно команду сразу на нескольких удаленных серверах. Если вы хотите запустить какой-то скрипт bash, я бы советовал добавить его в какой-то файл и скопировать на нужные сервера, после чего произвести его запуск.
На этом, пожалуй, все, надеюсь информация будет для вас полезной и облегчит рутинные задачи управления множеством серверов Linux.
Источник
Многозадачность в shell-скриптах
Иногда, при написании скрипта на shell хочется выполнять какие-то действия в несколько потоков. Подходящими ситуациями могут быть, например, сжатие большохо количества больших файлов на многопроцессорном хосте и передача файлов по широкому каналу, на котором ограничена скорость индивидуального соединения.
Все примеры написаны на bash, но (с минимальными изменениями) будут работать в ksh. В csh тоже есть средстава управления фоновыми процессами, поэтому подобных подход тоже может быть использован.
JOB CONTROL
Так называется секция в man bash где описаны подробности, на случай если вы любите читать man. Мы используем следующие простые возможности:
command & — запускает команду в фоне
jobs — печатает список фоновых команд
Простой пример, не выполняющий никаких полезных действий. Из файла test.txt читаются числа, и параллельно запускается 3 процесса, которые спят соответствующее количество секунд. Каждые три секунды проверяется число запущенных процессов, и если их меньше трех, запускается новый. Запуск фонового процесса вынесен в отдельную функцию mytask, но можно запускть его непосредственно в цикле.
Обратите внимание на wait после цикла, команда ждет завершения исполняющихся в фоне процессов. Без нее скрипт будет завершен сразу после завершения цикла и все фоновые процессы будут прерваны. Возможно именно этот wait упоминается в известном меме «oh, wait. ».
Завершение фоновых процессов
Если прервать скрипт по Ctrl-C, он будет убит со всеми фоновыми процессами, т.к. все процессы работающие в терминале получают сигналы от клавиатуры (например, SIGINT). Если же скрипт убить из другого терминала командой kill, то фоновые процессы останутся работать до завершения и об этом нужно помнить.
/tmp2 $ ps -ef | grep -E «test|sleep»
user 1363 775 0 12:31 pts/5 00:00:00 ./test.sh
user 1368 1363 0 12:31 pts/5 00:00:00 ./test.sh
user 1370 1368 0 12:31 pts/5 00:00:00 /usr/bin/coreutils —coreutils-prog-shebang=sleep /usr/bin/sleep 60
user 1373 1363 0 12:31 pts/5 00:00:00 ./test.sh
user 1375 1373 0 12:31 pts/5 00:00:00 /usr/bin/coreutils —coreutils-prog-shebang=sleep /usr/bin/sleep 50
user 1378 1363 0 12:31 pts/5 00:00:00 ./test.sh
user 1382 1378 0 12:31 pts/5 00:00:00 /usr/bin/coreutils —coreutils-prog-shebang=sleep /usr/bin/sleep 30
user 1387 1363 0 12:31 pts/5 00:00:00 /usr/bin/coreutils —coreutils-prog-shebang=sleep /usr/bin/sleep 3
user 1389 556 0 12:31 pts/2 00:00:00 grep —colour=auto -E test|sleep
user@somehost
/tmp2 $ kill 1363
user@somehost
/tmp2 $ ps -ef | grep -E «test|sleep»
user 1368 1 0 12:31 pts/5 00:00:00 ./test.sh
user 1370 1368 0 12:31 pts/5 00:00:00 /usr/bin/coreutils —coreutils-prog-shebang=sleep /usr/bin/sleep 60
user 1373 1 0 12:31 pts/5 00:00:00 ./test.sh
user 1375 1373 0 12:31 pts/5 00:00:00 /usr/bin/coreutils —coreutils-prog-shebang=sleep /usr/bin/sleep 50
user 1378 1 0 12:31 pts/5 00:00:00 ./test.sh
user 1382 1378 0 12:31 pts/5 00:00:00 /usr/bin/coreutils —coreutils-prog-shebang=sleep /usr/bin/sleep 30
user 1399 556 0 12:32 pts/2 00:00:00 grep —colour=auto -E test|sleep
Эту ситуацию можно обработать, перехватывая нужные сигналы, для чего в начале скрипта добавим обработчик:
Источник
Процессы
Как уже упоминалось в лекции Сеанс работы в Linux, загрузка Linux завершается тем, что на всех виртуальных консолях (на самом деле — на всех терминалах системы), предназначенных для работы пользователей, запускается программа getty . Программа выводит приглашение и ожидает активности пользователя, который может захотеть работать именно на этом терминале. Введённое входное имя getty передаёт программе login , которая вводит пароль и определяет, разрешено ли работать в системе с этим входным именем и этим паролем. Если login приходит к выводу, что работать можно, он запускает стартовый командный интерпретатор, посредством которого пользователь и командует системой.
Выполняющаяся программа называется в Linux процессом. Все процессы система регистрирует в таблице процессов, присваивая каждому уникальный номер — идентификатор процесса (process identificator, PID). Манипулируя процессами, система имеет дело именно с их идентификаторами, другого способа отличить один процесс от другого, по большому счёту, нет. Для просмотра своих процессов можно воспользоваться утилитой ps («process status»):
[methody@localhost methody]$ ps -f
UID PID PPID C STIME TTY TIME CMD
methody 3590 1850 0 13:58 tty3 00:00:00 -bash
methody 3624 3590 0 14:01 tty3 00:00:00 ps -f
Пример 1. Просмотр таблицы собственных процессов
Здесь Мефодий вызвал ps с ключом « -f » («full»), чтобы добыть побольше информации. Представлены оба принадлежащих ему процесса: стартовый командный интерпретатор, bash , и выполняющийся ps . Оба процесса запущены с терминала tty3 (третьей системной консоли), и имеют идентификаторы 3590 и 3624 соответственно. В поле PPID («parent process identificator») указан идентификатор родительского процесса, т. е. процесса, породившего данный. Для ps это — bash , а для bash , очевидно, login , так как именно он запускает стартовый shell. В выдаче не оказалось строки для этого login , равно как и для большинства других процессов системы, так как они не принадлежат пользователю methody .
процесс Выполняющаяся программа в Linux. Каждый процесс имеет уникальный идентификатор процесса, PID. Процессы получают доступ к ресурсам системы (опреативной памяти, файлам, внешним устройствам и т. п.) и могут изменять их содержимое. Доступ регулируется с помощью идентификатора пользователя и идентификатора группы, которые система присваивает каждому процессу.
Запуск дочерних процессов
Запуск одного процесса вместо другого устроен в Linux с помощью системного вызова exec() . Старый процесс из памяти удаляется навсегда, вместо него загружается новый, при этом настройка окружения не меняется, даже PID остаётся прежним. Вернуться к выполнению старого процесса невозможно, разве что запустить его по новой с помощью того же exec() (от «execute» — «исполнить»). Кстати, имя файла (программы), из которого запускается процесс, и собственное имя процесса (в таблице процессов) могут и не совпадать. Собственное имя процесса — это такой же параметр командной строки, как и те, что передаются ему пользователем: для exec() требуется и путь к файлу, и полная командная строка, нулевой (стартовый) элемент которой — как раз название команды
Нулевой параметр — argv[0] в терминах языка Си и $0 в терминах shell
Вот откуда « — » в начале имени стартового командного интерпретатора ( -bash ): его «подсунула» программа login , чтобы была возможность отличать его от других запущенных тем же пользователем оболочек.
Для работы командного интерпретатора недостаточно одного exec() . В самом деле, shell не просто запускает утилиту, а дожидается её завершения, обрабатывает результаты её работы и продолжает диалог с пользователем. Для этого в Linux служит системный вызов fork() («вилка, развилка»), применение которого приводит к возникновению ещё одного, дочернего, процесса — точной копии породившего его родительского. Дочерний процесс ничем не отличается от родительского: имеет такое же окружение, те же стандартный ввод и стандартный вывод, одинаковое содержимое памяти и продолжает работу с той же самой точки (возврат из fork() ). Отличия два: во-первых, эти процессы имеют разные PID, под которыми они зарегистрированы в таблице процессов, а во-вторых, различается возвращаемое значение fork() : родительский процесс получает в качестве результата fork() идентификатор процесса-потомка, а процесс-потомок получает « 0 ».
Дальнейшие действия shell при запуске какой-либо программы очевидны. Shell-потомок немедленно вызывает эту программу с помощью exec() , а shell-родитель дожидается завершения работы процесса-потомка (PID которого ему известен) с помощью ещё одного системного вызова, wait() . Дождавшись и проанализировав результат команды, shell продолжает работу.
[methody@localhost methody]$ cat > loop
while true; do true; done
^D
[methody@localhost methody]$ sh loop
^C
[methody@localhost methody]$
Пример 2. Создание бесконечно выполняющегося сценария
По совету Гуревича Мефодий создал сценарий для sh (или bash , на таком уровне их команды совпадают), который ничего не делает. Точнее было бы сказать, что этот сценарий делает ничего, бесконечно повторяя в цикле команду, вся работа которой состоит в том, что она завершается без ошибок (в лекции Работа с текстовыми данными будет сказано о том, что « >файл » в командной строке просто перенаправляет стандартный вывод команды в файл ). Запустив этот сценарий с помощью команды вида sh имя_сценария , Мефодий ничего не увидел, но услышал, как загудел вентилятор охлаждения центрального процессора: машина трудилась! Управляющий символ « ^C », как обычно, привёл к завершению активного процесса, и командный интерпретатор продолжил работу.
Если бы в описанной выше ситуации родительский процесс не ждал, пока дочерний завершится, а сразу продолжал работать, получилось бы, что оба процесса выполняются «параллельно»: пока запущенный процесс что-то делает, пользователь продолжает командовать оболочкой. Для того, чтобы запустить процесс параллельно, в shell достаточно добавить « & » в конец командной строки:
[methody@localhost methody]$ sh loop&
[1] 3634
[methody@localhost methody]$ ps -f
UID PID PPID C STIME TTY TIME CMD
methody 3590 1850 0 13:58 tty3 00:00:00 -bash
methody 3634 3590 99 14:03 tty3 00:00:02 sh loop
methody 3635 3590 0 14:03 tty3 00:00:00 ps -f
Пример 3. Запуск фонового процесса
В результате стартовый командный интерпретатор (PID 3590 ) оказался отцом сразу двух процессов: sh , выполняющего сценарий loop и ps .
Процесс, запускаемый параллельно, называется фоновым (background). Фоновые процессы не имеют возможности вводить данные с того же терминала, что и породивший их shell (только из файла), зато выводить на это терминал могут (правда, когда на одном и том же терминале вперемежку появляются сообщения от нескольких фоновых процессов, начинается сущая неразбериха). При каждом терминале в каждый момент времени может быть не больше одного активного (foreground) процесса, которому разрешено с этого терминала вводить. На время, пока команда (например, cat ) работает в активном режиме, породивший её командный интерпретатор «уходит в фон», и там, в фоне, выполняет свой wait() .
активный процесс Процесс, имеющий возможность вводить данные с терминала. В каждый момент у каждого терминала может быть не более одного активного процесса. фоновый процесс Процесс, не имеющий возможность вводить данные с терминала. Пользователь может запустить любое, не превосходящее заранее заданного в системе, число фоновых процессов.
Стоит заметить, что параллельность работы процессов в Linux — дискретная. Здесь и сейчас выполняться может столько процессов, сколько центральных процессоров есть в компьютере (например, один). Дав этому одному процессу немного поработать, система запоминает всё, что тому для работы необходимо, приостанавливает его, и запускает следующий процесс, потом следующий и так далее. Возникает очередь процессов, ожидающих выполнения. Только что поработавший процесс помещается в конец этой очереди, а следующий выбирается из её начала. Когда очередь вновь доходит до того, первого процесса, система вспоминает необходимые для его выполнения данные (они называются контекстом процесса), и он продолжает работать, как ни в чём не бывало. Такая схема разделения времени между процессами носит названия псевдопараллелизма.
В выдаче ps , которую получил Мефодий, можно заметить, что PID стартовой оболочки равен 3590 , а PID запущенных из-под него команд (одной фоновой и одной активной) — 3634 и 3635 . Это значит, что за время, прошедшее с момента входа Мефодия в систему до момента запуска sh loop& , в системе было запущено ещё 3634-3590=44 процесса. Что ж, в Linux могут одновременно работать несколько пользователей, да и самой системе иногда приходит в голову запустить какую-нибудь утилиту (например, выполняя действия по расписанию). А вот sh и ps получили соседние PID, значит, пока Мефодий нажимал Enter и набирал ps -f , никаких других процессов не запускалось.
В действительности далеко не всем процессам, зарегистрированным в системе, на самом деле необходимо давать поработать наравне с другими. Большинству процессов работать прямо сейчас не нужно: они ожидают какого-нибудь события, которое им нужно обработать. Чаще всего процессы ждут завершения операции ввода-вывода. Чтобы посмотреть, как потребляются ресурсы системы, можно использовать утилиту top . Но сначала Мефодий решил запустить ещё один бесконечный сценарий: ему было интересно, как два процесса конкурируют за ресурсы между собой:
[methody@localhost methody]$ bash loop&
[2] 3639
[methody@localhost methody]$ top
14:06:50 up 3:41, 5 users, load average: 1,31, 0,76, 0,42
4 processes: 1 sleeping, 3 running, 0 zombie, 0 stopped
CPU states: 99,4% user, 0,5% system, 0,0% nice, 0,0% iowait, 0,0% idle
Mem: 514604k av, 310620k used, 203984k free, 0k shrd, 47996k buff
117560k active, 148388k inactive
Swap: 1048280k av, 0k used, 1048280k free 184340k cached
PID USER PRI NI SIZE RSS SHARE STAT %CPU %MEM TIME COMMAND
3639 methody 20 0 1260 1260 1044 R 50,3 0,2 0:12 bash
3634 methody 18 0 980 980 844 R 49,1 0,1 3:06 sh
3641 methody 9 0 1060 1060 872 R 0,1 0,2 0:00 top
3590 methody 9 0 1652 1652 1264 S 0,0 0,3 0:00 bash
Пример 4. Разделение времени между процессами
Оказалось, что дерутся даже не два процесса, а три: sh (первый из запущенных интерпретаторов loop ), bash (второй) и сам top . Правда, по сведениям из поля %CPU , львиную долю процессорного времени отобрали sh и bash (они без устали вычисляют!), а top довольствуется десятой долей процента (а то и меньшей: ошибки округления). Стартовый bash вообще не хочет работать, он спит (значение « S », Sleep, поля STAT , status): ждёт завершения активного процесса, top .
Увидев такое разнообразие информации, Мефодий кинулся читать руководство по top, однако скоро понял, что без знания архитектуры Linux большая её часть не имеет смысла. Впрочем, некоторая часть всё же понятна: объём оперативной памяти (всей, используемой и свободной), время работы машины, объём памяти, занимаемой процессами и т. п.
Последний процесс, запущенный из оболочки в фоне, можно из этой оболочки сделать активным при помощи команды fg («foreground» — «передний план»).
[methody@localhost methody]$ fg
bash loop
^C
Пример 5. Перевод фонового процесса в активное состояние с помощью команды fg (foreground)
Услужливый bash даже написал командную строку, какой был запущен этот процесс: « bash loop ». Мефодий решил «убить» его с помощью управляющего символа « ^C ». Теперь последним запущенным в фоне процессом стал sh , выполняющий сценарий loop .
Сигналы
Чтобы завершить работу фонового процесса с помощью « ^C », Мефодию пришлось сначала сделать его активным. Это не всегда возможно, и не всегда удобно. На самом деле, « ^C » — это не волшебная кнопка-убийца, а предварительно установленный символ (с ascii-кодом 3), при получении которого с терминала Linux передаст активному процессу сигнал 2 (по имени INT , от «interrupt» — «прервать»).
Сигнал — это способность процессов обмениваться стандартными короткими сообщениями непосредственно с помощью системы. Сообщение-сигнал не содержит никакой информации, кроме номера сигнала (для удобства вместо номера можно использовать предопределённое системой имя). Для того, чтобы передать сигнал, процессу достаточно задействовать системный вызов kill() , а для того, чтобы принять сигнал, не нужно ничего. Если процессу нужно как-то по-особенному реагировать на сигнал, он может зарегистрировать обработчик, а если обработчика нет, за него отреагирует система. Как правило, это приводит к немедленному завершению процесса, получившего сигнал. Обработчик сигнала запускается асинхронно, немедленно после получения сигнала, что бы процесс в это время ни делал.
сигнал Короткое сообщение, посылаемое системой или процессом другому процессу. Обрабатывается асинхронно специальной подпрограммой-обработчиком. Если процесс не обрабатывает сигнал самостоятельно, это делает система.
Два сигнала — 9 ( KILL ) и 19 ( STOP ) — всегда обрабатывает система. Первый из них нужен для того, чтобы убить процесс наверняка (отсюда и название). Сигнал STOP приостанавливает процесс: в таком состоянии процесс не удаляется из таблицы процессов, но и не выполняется до тех пор, пока не получит сигнал 18 ( CONT ) — после чего продолжит работу. В Linux сигнал STOP можно передать активному процессу с помощью управляющего символа « ^Z »:
[methody@localhost methody]$ sh loop
^Z
[1]+ Stopped sh loop
[methody@localhost methody]$ bg
[1]+ sh loop &
[methody@localhost methody]$ fg
sh loop
^C
[methody@localhost methody]$
Пример 6. Перевод процесса в фон с помощью « ^Z » и bg
Мефодий сначала запустил вечный цикл в качестве активного процесса, затем передал ему сигнал STOP с помощью « ^Z », после чего дал команду bg (back ground), запускающую в фоне последний остановленный процесс. Затем он снова перевёл этот процесс в активный режим, и, наконец, убил его.
Передавать сигналы из командной строки можно любым процессам с помощью команды kill -сигнал PID или просто kill PID , которая передаёт сигнал 15 ( TERM ).
[methody@localhost methody]$ sh
sh-2.05b$ sh loop & bash loop &
[1] 3652
[2] 3653
sh-2.05b$ ps -fH
UID PID PPID C STIME TTY TIME CMD
methody 3590 1850 0 13:58 tty3 00:00:00 -bash
methody 3634 3590 87 14:03 tty3 00:14:18 sh loop
methody 3651 3590 0 14:19 tty3 00:00:00 sh
methody 3652 3651 34 14:19 tty3 00:00:01 sh loop
methody 3653 3651 35 14:19 tty3 00:00:01 bash loop
methody 3654 3651 0 14:19 tty3 00:00:00 ps -fH
Пример 7. Запуск множества фоновых процессов
Мефодий решил поназапускать процессов, а потом выборочно поубивать их. Для этого он, вдобавок к уже висящему в фоне sh loop , запустил в качестве активного процесса новый командный интерпретатор, sh (при этом изменилась приглашение командной строки). Из этого sh он запустил в фоне ещё один sh loop и новый bash loop . Сделал он это одной командной строкой (при этом команды разделяются символом « & », т. е. «И»; выходит так, что запускается и та, и другая команда). В ps он использовал новый ключ — « -H » («Hierarchy», «иерархия»), который добавляет в выдачу ps отступы, показывающие отношения «родитель–потомок» между процессами.
sh-2.05b$ kill 3634
[1]+ Terminated sh loop
sh-2.05b$ ps -fH
UID PID PPID C STIME TTY TIME CMD
methody 3590 1850 0 13:58 tty3 00:00:00 -bash
methody 3651 3590 0 14:19 tty3 00:00:00 sh
methody 3652 3651 34 14:19 tty3 00:01:10 sh loop
methody 3653 3651 34 14:19 tty3 00:01:10 bash loop
methody 3658 3651 0 14:23 tty3 00:00:00 ps -fH
Пример 8. Принудительное завершение процесса с помощью kill
Мефодий принялся убивать! Для начала он остановил работу давно запущенного sh , выполнявшего сценарий с вечным циклом (PID 3634 ). Как видно из предыдущего примера, этот процесс за 16 минут работы системы съел не менее 14 минут процессорного времени, и конечно, ничего полезного не сделал. Сигнал о том, что процесс-потомок умер, дошёл до обработчика в стартовом bash (PID 3590 , и на терминал вывелось сообщение « [1]+ Terminated sh loop », после чего стартовый bash продолжил ждать завершения активного процесса — sh (PID 3651 ).
sh-2.05b$ exit
[methody@localhost methody]$ ps -fH
UID PID PPID C STIME TTY TIME CMD
methody 3590 1850 0 15:17 tty3 00:00:00 -bash
methody 3663 3590 0 15:23 tty3 00:00:00 ps -fH
methody 3652 1 42 15:22 tty3 00:00:38 bash loop
methody 3653 1 42 15:22 tty3 00:00:40 sh loop
[methody@localhost methody]$ kill -HUP 3652 3653
[methody@localhost methody]$ ps
PID TTY TIME CMD
3590 tty3 00:00:00 bash
3664 tty3 00:00:00 ps
Пример 9. Завершение процесса естественным путём с помощью сигнала «Hang Up»
Ждать ему оставалось недолго. Этот sh завершился естественным путём, от команды exit , оставив после себя двух детей-сирот (PID 3652 и 3653 ), которые тотчас же усыновил «отец всех процессов» — init (PID 1 ). Когда кровожадный Мефодий расправился и с ними — с помощью сигнала 1 ( HUP , то есть «Hang UP», «повесить») — некому было даже сообщить об их кончине (если бы процесс-радитель был жив, на связанный с ним терминал вывелось бы что-нибудь вроде « [1]+ Hangup sh loop »).
Имя этого сигнала происходит не от казни через повешение, а от повешенной телефонной трубки.
Источник



