- Конвертирование файлов в кодировку UTF-8 в Linux
- Конвертирование файлов из UTF-8 в ASCII
- Конвертирование нескольких файлов в кодировку UTF-8
- How to Convert Files to UTF-8 Encoding in Linux
- Convert Files from UTF-8 to ASCII Encoding
- Convert Multiple Files to UTF-8 Encoding
- If You Appreciate What We Do Here On TecMint, You Should Consider:
- How to Determine and Change File Character Encoding of Text Files in Linux Systems
- Part 1: Detect a File’s Encoding using file Linux command
- Part 2: Change a File’s Encoding using iconv Linux command
- Как я боролся с кодировками в консоли
Конвертирование файлов в кодировку UTF-8 в Linux
Оригинал: How to Convert Files to UTF-8 Encoding in Linux
Автор: Aaron Kili
Дата публикации: 2 ноября 2016 года
Перевод: А. Кривошей
Дата перевода: ноябрь 2017 г.
В этом руководстве мы рассмотрим кодировки символов и разберем несколько примеров преобразования файлов из одной кодировки в другую с помощью утилиты командной строки. Затем мы покажем, как преобразовать файлы в Linux из любой кодировки (charset) в UTF-8.
Как вы, наверное, уже знаете, компьютер не понимает и не хранит информацию в виде букв, цифр или чего-либо еще. Он работает только с битами. Бит имеет только два возможных значения — 0 или 1, true или false, да или нет. Все остальное кодируется последовательностями битов.
Простыми словами, кодировка символов — это способ кодировки различных символов определенными последовательностями нулей и единиц. Когда мы вводим текст и сохраняем его в файл, слова и предложения, которые мы набираем, состоят из разных символов, а символы преобразуются в биты с помощью кодировки.
Существуют различные схемы кодирования, такие как ASCII, ANSI, Unicode и другие. Ниже приведен пример кодировки ASCII.
В Linux для преобразования текста из одной кодировки в другую используется утилита командной строки iconv.
Вы можете проверить кодировку файла с помощью команды file, используя флаг -i или -mime, который печатает строку типа mime, как в приведенных ниже примерах:

Синтаксис команды iconv следующий:
Где -f или —from-code задает входную кодировку, а -t или —to-encoding задает конечную кодировку.
Для того, чтобы вывести список всех доступных опций, введите:
Конвертирование файлов из UTF-8 в ASCII
Далее мы научимся конвертировать текст из одной кодировки в другую. Приведенная ниже команда преобразует текст из ISO-8859-1 в кодировку UTF-8.
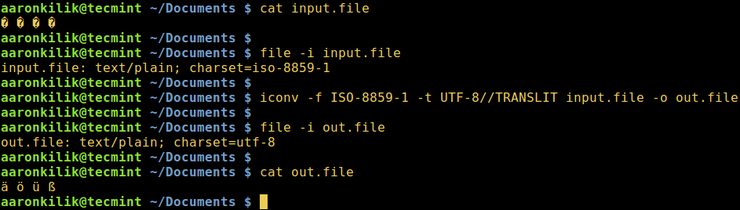
Рассмотрим файл input.file, который содержит следующие символы:
(Прим: вы увидите эти символы на снимке ниже)
Начнем с проверки кодировки файла, затем просмотрим его содержимое. Мы можем преобразовать все символы в кодировку ASCII.
После запуска команды iconv мы затем проверяем содержимое выходного файла и новую кодировку, как показано ниже.
Примечание. Если в команду добавлена строка //IGNORE, то символы, которые не могут быть преобразованы, и ошибка выводятся после преобразования.
Далее, если добавлена строка //TRANSLIT, как в приведенном выше примере (ASCII//TRANSLIT), преобразуемые символы при необходимости и по возможности транслитерируются. Это означает, что если символ не может быть представлен в целевой кодировке, его можно аппроксимировать одним или несколькими похожими символами.
Далее, любой символ, который не может быть транслитерирован и которого нет в целевой кодировке, заменяется в выводе вопросительным знаком (?).
Конвертирование нескольких файлов в кодировку UTF-8
Возвращаясь к основной теме нашей статьи, мы можем написать небольшой скрипт для преобразования нескольких или всех файлов в каталоге в кодировку UTF-8, под названием encoding.sh:
Сохраните этот файл и сделайте скрипт исполняемым. Запускайте его из той директории, где расположены ваши файлы.
Важное замечание. Вы также можете также использовать этот скрипт для преобразования нескольких файлов из одной заданной кодировки в другую (любую), просто меняйте со значения переменных FROM_ENCODING и TO_ENCODING, не забывая об имени выходного файла «$
Для получения дополнительной информации почитайте руководство iconv:
Подводя итог этой статье, необходимо отметить, что понимание способов преобразования текста из одной кодировки в другую — это знания, необходимые каждому пользователю компьютера, а тем более программистам, когда дело касается работы с текстами.
Если вы хотите лучше понять проблему кодировок символов, прочитайте следующие статьи:
Источник
How to Convert Files to UTF-8 Encoding in Linux
In this guide, we will describe what character encoding and cover a few examples of converting files from one character encoding to another using a command line tool. Then finally, we will look at how to convert several files from any character set (charset) to UTF-8 encoding in Linux.
As you may probably have in mind already, a computer does not understand or store letters, numbers or anything else that we as humans can perceive except bits. A bit has only two possible values, that is either a 0 or 1 , true or false , yes or no . Every other thing such as letters, numbers, images must be represented in bits for a computer to process.
In simple terms, character encoding is a way of informing a computer how to interpret raw zeroes and ones into actual characters, where a character is represented by set of numbers. When we type text in a file, the words and sentences we form are cooked-up from different characters, and characters are organized into a charset.
There are various encoding schemes out there such as ASCII, ANSI, Unicode among others. Below is an example of ASCII encoding.
In Linux, the iconv command line tool is used to convert text from one form of encoding to another.
You can check the encoding of a file using the file command, by using the -i or —mime flag which enables printing of mime type string as in the examples below:
![]() Check File Encoding in Linux
Check File Encoding in Linux
The syntax for using iconv is as follows:
Where -f or —from-code means input encoding and -t or —to-encoding specifies output encoding.
To list all known coded character sets, run the command below:
![]() List Coded Charsets in Linux
List Coded Charsets in Linux
Convert Files from UTF-8 to ASCII Encoding
Next, we will learn how to convert from one encoding scheme to another. The command below converts from ISO-8859-1 to UTF-8 encoding.
Consider a file named input.file which contains the characters:
Let us start by checking the encoding of the characters in the file and then view the file contents. Closely, we can convert all the characters to ASCII encoding.
After running the iconv command, we then check the contents of the output file and the new encoding of the characters as below.
![]() Convert UTF-8 to ASCII in Linux
Convert UTF-8 to ASCII in Linux
Note: In case the string //IGNORE is added to to-encoding, characters that can’t be converted and an error is displayed after conversion.
Again, supposing the string //TRANSLIT is added to to-encoding as in the example above (ASCII//TRANSLIT), characters being converted are transliterated as needed and if possible. Which implies in the event that a character can’t be represented in the target character set, it can be approximated through one or more similar looking characters.
Consequently, any character that can’t be transliterated and is not in target character set is replaced with a question mark (?) in the output.
Convert Multiple Files to UTF-8 Encoding
Coming back to our main topic, to convert multiple or all files in a directory to UTF-8 encoding, you can write a small shell script called encoding.sh as follows:
Save the file, then make the script executable. Run it from the directory where your files ( *.txt ) are located.
Important: You can as well use this script for general conversion of multiple files from one given encoding to another, simply play around with the values of the FROM_ENCODING and TO_ENCODING variable, not forgetting the output file name «$
For more information, look through the iconv man page.
To sum up this guide, understanding encoding and how to convert from one character encoding scheme to another is necessary knowledge for every computer user more so for programmers when it comes to dealing with text.
Lastly, you can get in touch with us by using the comment section below for any questions or feedback.
If You Appreciate What We Do Here On TecMint, You Should Consider:
TecMint is the fastest growing and most trusted community site for any kind of Linux Articles, Guides and Books on the web. Millions of people visit TecMint! to search or browse the thousands of published articles available FREELY to all.
If you like what you are reading, please consider buying us a coffee ( or 2 ) as a token of appreciation.

We are thankful for your never ending support.
Источник
How to Determine and Change File Character Encoding of Text Files in Linux Systems
Posted by: Mohammed Semari | Published: January 17, 2017| Updated: February 26, 2017

How many times did you want to find and detect the encoding of a text files in Linux systems? or How many times did you try to watch a movie and it’s subtitles .srt showed in unreadable shapes “characters” ?
Sure many times you tried/needed to know/change the encoding of text files in Linux systems.
All this because you are using a wrong encoding format for your text files. The solution for this is very simple Just knowing the text files encoding will end your problems. You can either “for example” set your media player to use the correct encoding for your subtitles OR YOU CAN CHANGE THE ENCODING OF YOUR TEXT FILES TO A GLOBAL ACCEPTED ENCODING “UTF-8 FOR EXAMPLE”
This post is divided into two parts. In part 1: I’ll show you how to find and detect the text files encoding in Linux systems using Linux file command available by default in all Linux distributions. In part 2: I’ll show you how to change the encoding of the text files using iconv Linux command between CP1256 (Windows-1256, Cyrillic), UTF-8, ISO-8859-1 and ASCII character sets.
Part 1: Detect a File’s Encoding using file Linux command
The file command makes “best-guesses” about the encoding. Use the following command to determine what character encoding is used by a file :
| Option | Description |
|---|---|
| -b, —brief | Don’t print filename (brief mode) |
| -i, —mime | Print filetype and encoding |
Example 1 : Detect the encoding of the file “storks.srt”
As you see, “storks.srt” file is encoded with iso-8859-1
Example 2 : Detect the encoding of the file “The.Girl.on.the.Train.2016.1080p.WEB-DL.DD5.1.H264-FGT.srt”
Here’s the “The.Girl.on.the.Train.2016.1080p.WEB-DL.DD5.1.H264-FGT.srt” file is utf-8 encoded.
Finally, file command is perfect for telling you what exactly the encoding of a text file. You can use it to detect if your text file is encoded with UTF-8, WINDOWS-1256, ISO-8859-6, GEORGIAN-ACADEMY, etc…
Part 2: Change a File’s Encoding using iconv Linux command
To use iconv Linux command you need to know the encoding of the text file you need to change it. Use the following syntax to convert the encoding of a file :
| Option | Description |
|---|---|
| -f, —from-code | Convert characters from encoding |
| -t, —to-code | Convert characters to encoding |
Example 1: Convert a file’s encoding from iso-8859-1 to UTF-8 and save it to New_storks.srt
Here’s the New_storks.srt is UTF-8 encoded.
Example 2: Convert a file’s encoding from cp1256 to UTF-8 and save it to output.txt
Here’s the output.txt is UTF-8 encoded.
Example 3: Convert a file’s encoding from ASCII to UTF-8 and save it to output.txt
Here’s the output.txt is UTF-8 encoded.
Example 4: Convert a file’s encoding from UTF-8 to ASCII
| Option | Description |
|---|---|
| -c | Omit invalid characters from output |
Finally, to list all the coded character sets known run -l option with iconv as follow:
| Option | Description |
|---|---|
| -l, —list | List known coded character sets |
Here’s the output of the above command:
Finally, I hope this article is useful for you.
Источник
Как я боролся с кодировками в консоли
В очередной раз запустив в Windows свой скрипт-информер для СамИздат-а и увидев в консоли «загадочные символы» я сказал себе: «Да уже сделай, наконец, себе нормальный кросс-платформенный логгинг!»
Об этом, и о том, как раскрасить вывод лога наподобие Django-вского в Win32 я попробую рассказать под хабра-катом (Всё ниженаписанное применимо к Python 2.x ветке)
Задача первая. Корректный вывод текста в консоль
Симптомы
До тех пор, пока мы не вносим каких-либо «поправок» в проинициализировавшуюся систему ввода-вывода и используем только оператор print с unicode строками, всё идёт более-менее нормально вне зависимости от ОС.
«Чудеса» начинаются дальше — если мы поменяли какие-либо кодировки (см. чуть дальше) или воспользовались модулем logging для вывода на экран. Вроде бы настроив ожидаемое поведение в Linux, в Windows получаешь «мусор» в utf-8. Начинаешь править под Win — вылезает 1251 в консоли…
Теоретический экскурс
Ищем решение
Очевидно, чтобы избавиться от всех этих проблем, надо как-то привести их к единообразию.
И вот тут начинается самое интересное:
Ага! Оказывается «система» у нас живёт вообще в ASCII. Как следствие — попытка по-простому работать с вводом/выводом заканчивается «любимым» исключением UnicodeEncodeError/UnicodeDecodeError .
Кроме того, как замечательно видно из примера, если в linux у нас везде utf-8, то в Windows — две разных кодировки — так называемая ANSI, она же cp1251, используемая для графической части и OEM, она же cp866, для вывода текста в консоли. OEM кодировка пришла к нам со времён DOS-а и, теоретически, может быть также перенастроена специальными командами, но на практике никто этого давно не делает.
До недавнего времени я пользовался распространённым способом исправить эту неприятность:
И это, в общем-то, работало. Работало до тех пор, пока пользовался print -ом. При переходе к выводу на экран через logging всё сломалось.
Угу, подумал я, раз «оно» использует кодировку по-умолчанию, — выставлю-ка я ту же кодировку, что в консоли:
Уже чуть лучше, но:
- В Win32 текст печатается кракозябрами, явно напоминающими cp1251
- При запуске с перенаправленным выводом опять получаем не то, что ожидалось
- Периодически, при попытке напечатать текст, где есть преобразованный в unicode символ типа ① ( ① ), «любезно» добавленный автором в какой-нибудь заголовок, снова получаем UnicodeEncodeError !
Присмотревшись к первому примеру, нетрудно заметить, что так желаемую кодировку «cp866» можно получить только проверив атрибут соответствующего потока. А он далеко не всегда оказывается доступен.
Вторая часть задачи — оставить системную кодировку в utf-8, но корректно настроить вывод в консоль.
Для индивидуальной настройки вывода надо переопределить обработку выходных потоков примерно так:
Этот код позволяет убить двух зайцев — выставить нужную кодировку и защититься от исключений при печати всяких умляутов и прочей типографики, отсутствующей в 255 символах cp866.
Осталось сделать этот код универсальным — откуда мне знать OEM кодировку на произвольном сферическом компе? Гугление на предмет готовой поддержки ANSI/OEM кодировок в python ничего разумного не дало, посему пришлось немного вспомнить WinAPI
… и собрать всё вместе:
Задача вторая. Раскрашиваем вывод
Насмотревшись на отладочный вывод Джанги в связке с werkzeug, захотелось чего-то подобного для себя. Гугление выдаёт несколько проектов разной степени проработки и удобности — от простейшего наследника logging.StreamHandler , до некоего набора, при импорте автоматически подменяющего стандартный StreamHandler.
Попробовав несколько из них, я, в итоге, воспользовался простейшим наследником StreamHandler, приведённом в одном из комментов на Stack Overflow и пока вполне доволен:
Однако, в Windows всё это работать, разумеется, отказалось. И если раньше можно было «включить» поддержку ansi-кодов в консоли добавлением «магического» ansi.dll из проекта symfony куда-то в недра системных папок винды, то, начиная (кажется) с Windows 7 данная возможность окончательно «выпилена» из системы. Да и заставлять юзера копировать какую-то dll в системную папку тоже как-то «не кошерно».
Снова обращаемся к гуглу и, снова, получаем несколько вариантов решения. Все варианты так или иначе сводятся к подмене вывода ANSI escape-последовательностей вызовом WinAPI для управления атрибутами консоли.
Побродив некоторое время по ссылкам, набрёл на проект colorama. Он как-то понравился мне больше остального. К плюсам именно этого проекта ст́оит отнести, что подменяется весь консольный вывод — можно выводить раскрашенный текст простым print u»\x1b[31;40mЧто-то красное на чёрном\x1b[0m» если вдруг захочется поизвращаться.
Сразу замечу, что текущая версия 0.1.18 содержит досадный баг, ломающий вывод unicode строк. Но простейшее решение я привёл там же при создании issue.
Собственно осталось объединить оба пожелания и начать пользоваться вместо традиционных «костылей»:
Дальше в своём проекте, в запускаемом файле пользуемся:
На этом всё. Из потенциальных доработок осталось проверить работоспособность под win64 python и, возможно, добаботать ColoredHandler чтобы проверял себя на isatty, как в более сложных примерах на том же StackOverflow.
Источник



