- S.M.A.R.T.
- Contents
- Smartmontools
- smartctl
- Run a test
- View test results
- Generate table with attributes of all disks
- smartd
- daemon management
- Define the devices to monitor
- Notifying potential problems
- Power management
- Schedule self-tests
- Alert on temperature changes
- Complete smartd.conf example
- Console applications
- Узнаём данные S.M.A.R.T. в Linux. Контроль состояния HDD или SSD
- Мониторинг и проверка состояния SSD в Linux
- Что такое S.M.A.R.T.?
- Что не относится к S.M.A.R.T.?
- Использование smartctl для мониторинга состояния вашего SSD в Linux
- Понимание выходных данных команд smartctl
- Проверьте свой SSD в Linux с помощью smartctl
S.M.A.R.T.
S.M.A.R.T. (Self-Monitoring, Analysis, and Reporting Technology) is a supplementary component built into many modern storage devices through which devices monitor, store, and analyze the health of their operation. Statistics are collected (temperature, number of reallocated sectors, seek errors. ) which software can use to measure the health of a device, predict possible device failure, and provide notifications on unsafe values.
Contents
Smartmontools
The smartmontools package contains two utility programs for analyzing and monitoring storage devices: smartctl and smartd . Install the smartmontools package to use these tools.
SMART support must be available and enabled on each storage device to effectively use these tools. You can use #smartctl to check for and enable SMART support. That done, you can manually #Run a test and #View test results, or you can use #smartd to automatically run tests and email notifications.
smartctl
smartctl is a command-line tool that «controls the Self-Monitoring, Analysis and Reporting Technology (SMART) system built into most ATA/SATA and SCSI/SAS hard drives and solid-state drives.»
The -i / —info option prints a variety of information about a device, including whether SMART is available and enabled:
If SMART is available but not enabled, you can enable it:
You may need to specify a device type. For example, specifying —device=ata tells smartctl that the device type is ATA, and this prevents smartctl from issuing SCSI commands to that device.
Run a test
There are three types of self-tests that a device can execute (all are safe to user data):
- Short: runs tests that have a high probability of detecting device problems,
- Extended or Long: the test is the same as the short check but with no time limit and with complete disk surface examination,
- Conveyance: identifies if damage incurred during transportation of the device.
The -c / —capabilities flag prints which tests a device supports and the approximate execution time of each test. For example:
Use -t / —test= flag to run a test:
View test results
You can view a device’s overall health with the -H flag. «If the device reports failing health status, this means either that the device has already failed, or that it is predicting its own failure within the next 24 hours. If this happens […] get your data off the disk and to someplace safe as soon as you can.»
You can also view a list of recent test results and detailed information about a device:
Generate table with attributes of all disks
![]() This article or section needs language, wiki syntax or style improvements. See Help:Style for reference.
This article or section needs language, wiki syntax or style improvements. See Help:Style for reference.![]()
smartd
The smartd daemon monitors SMART statuses and emits notifications when something goes wrong. It can be managed with systemd and configured using the /etc/smartd.conf configuration file. The configuration file syntax is esoteric, and this wiki page provides only a quick reference. For more complete information, read the examples and comments within the configuration file, or read smartd.conf(5) .
daemon management
To start the daemon, check its status, make it auto-start on system boot and read recent log file entries, simply start/enable the smartd.service systemd unit.
smartd respects all the usual systemctl and journalctl commands.
Define the devices to monitor
To monitor for all possible SMART errors on all disks, the following setting must be added in the configuration file.
Note this is the default smartd configuration and the -a parameter, which is the default parameter, may be omitted.
To monitor for all possible SMART errors on /dev/sda and /dev/sdb , and ignore all other devices:
To monitor for all possible SMART errors on externally connected disks (USB-backup disks spring to mind) it is prudent to tell smartd the UUID of the device since the /dev/sdX of the drive might change during a reboot.
First, you will have to get the UUID of the disk to monitor: ls -lah /dev/disk/by-uuid/ now look for the disk you want to Monitor
I know that my USB disk attached to /dev/sde during boot. Now to tell smartd to monitor that disk simply use the /dev/disk/by-uuid/ path.
Note that you may additionally need -d removable for smartd to work.
Now your USB disk will be monitored even if the /dev/sdX path changes during reboot.
Notifying potential problems
To have an email sent when a failure or new error occurs, use the -m option:
To be able to send the email externally (i.e. not to the root mail account) a MTA (Mail Transport Agent) or a MUA (Mail User Agent) will need to be installed and configured. Common MUAs are msmtp and Postfix, but perhaps the easiest dma will suffice. Common MTAs are sendmail and Postfix. It is enough to simply configure S-nail if you do not want anything else, but you will need to follow these instructions.
The -M test option causes a test email to be sent each time the smartd daemon starts:
Emails can take quite a while to be delivered. To make sure you are warned immediately if your hard drive fails, you may also define a script to be executed in addition to the email sending:
To send an email and a system notification, put something like this into /usr/local/bin/smartdnotify :
If you are running a desktop environment, you might also prefer having a popup to appear on your desktop. In this case, you can use this script (replace X_user and X_userid with the user and userid running X respectively) :
This requires libnotify and a compatible desktop environment. See Desktop notifications for more details.
You can also put your custom scripts into /usr/share/smartmontools/smartd_warning.d/ :
This scripts notifies every logged in users on the system via libnotify.
This script requires libnotify and procps-ng and a compatible desktop environment.
You can execute your custom scripts with
Power management
If you use a computer under control of power management, you should instruct smartd how to handle disks in low power mode. Usually, in response to SMART commands issued by smartd, the disk platters are spun up. So if this option is not used, then a disk which is in a low-power mode may be spun up and put into a higher-power mode when it is periodically polled by smartd.
On some devices the -n does not work. You get the following error message in syslog:
As an alternative, you can use the -i option of smartd. It controls how often smartd spins the disks up to check their status. Default is 30 minutes. To change it create and edit /etc/default/smartmontools .
For more info see smartd(8) .
Schedule self-tests
smartd can tell disks to perform self-tests on a schedule. The following /etc/smartd.conf configuration will start a short self-test every day between 2-3am, and an extended self test weekly on Saturdays between 3-4am:
Alert on temperature changes
smartd can track disk temperatures and alert if they rise too quickly or hit a high limit. The following will log changes of 4 degrees or more, log when temp reaches 35 degrees, and log/email a warning when temp reaches 40:
Complete smartd.conf example
Putting together all of the above gives the following example configuration:
- DEVICESCAN smartd scans for disks and monitors all it finds
- -a monitor all attributes
- -o on enable automatic offline data collection
- -S on enable automatic attribute autosave
- -n standby,q do not check if disk is in standby, and suppress log message to that effect so as not to cause a write to disk
- -s . schedule short and long self-tests
- -W . monitor temperature
- -m . mail alerts
Console applications
- skdump — utility to monitor and manage SMART devices to monitor and report hard disk drive health.
http://0pointer.de/blog/projects/being-smart.html || libatasmart
iostat -x (from sysstat ) also provides some disk health metrics: in particular, high values in the f_await column mean that the disk does not respond quickly to requests, and might be failing.
Источник
Узнаём данные S.M.A.R.T. в Linux. Контроль состояния HDD или SSD
Дата добавления: 07 июля 2012

S.M.A.R.T. (Self-Monitoring, Analisys and Reporting Technology) — это технология, предоставляющая пользователю различные данные о текущем состоянии жесткого диска или твердотельного накопителя. Анализируя данные S.M.A.R.T., пользователь может оценить состояние своих накопителей и решить, требуют ли они замены или ещё смогут работать долго и без сбоев.
Консольный способ: smartmontools
Узнать данные S.M.A.R.T. в чистом виде нам поможет утилита под названием smartmontools .
Приведем пример установки для дистрибутивов на основе Debian:
Количество атрибутов может отличаться в зависимости от модели диска.
В этой таблице нам нужно смотреть на значение поля RAW_VALUE для нужного атрибута. Именно оно показывает текущее значение атрибута.
Наиболее важные показатели:
Raw_Read_Error_Rate — количество ошибок чтения. Ненулевое значение должно сильно насторожить, а большие значение и вовсе говорят о скором выходе диска из строя. Известно, что на дисках Seagate, Samsung (семейства F1 и более новые) и Fujitsu 2,5? большое значение в этом поле является нормальным. Для остальных же дисков в идеале значение должно быть равно нулю;
Spin_Up_Time — время раскрутки диска. Измеряется в миллисекундах т.е. в моём случае это 1.3 секунды. Чем меньше — тем лучше. Большие значения говорят о низкой отзывчивости;
Start_Stop_Count — количество циклом запуска/остановки шпинделя;
Reallocated_Sector_Ct — количество перераспределённых секторов. Большое значение говорит о большом количестве ошибок диска;
Seek_Error_Rate — количество ошибок позиционирования. Большое значение говорит о плохом состоянии диска;
Power_On_Hours — количество наработанных часов во включённом состоянии. По нему можно узнать сколько проработал диск во включённом состоянии. Довольно полезно, например, если покупать ноутбук с витрины и хочется узнать долго ли он там стоял;
Power_Cycle_Count — количество включений/выключений диска;
Spin_Retry_Count — количество попыток повторной раскрутки. Большое значение говорит о плохом состоянии диска;
Temperature_Celsius — температура диска в градусах Цельсия. При слишком высокой температуре диски могут быстрее выйти из строя;
Reallocated_Event_Count — количество операций перераспределения секторов;
Offline_Uncorrectable — количество неисправных секторов. Большое значение говорит о повреждённой поверхности.
Более наглядный графический способ: gnome-disk-utility
В графическом варианте и с описанием атрибутов, данные SMART представляет программа gnome-disk-utility . В русской локализации в меню она называется как «дисковая утилита». В английской локализации известна как «Disks».
Пример установки для дистрибутивов на основе Debian:
Запускаем программу. 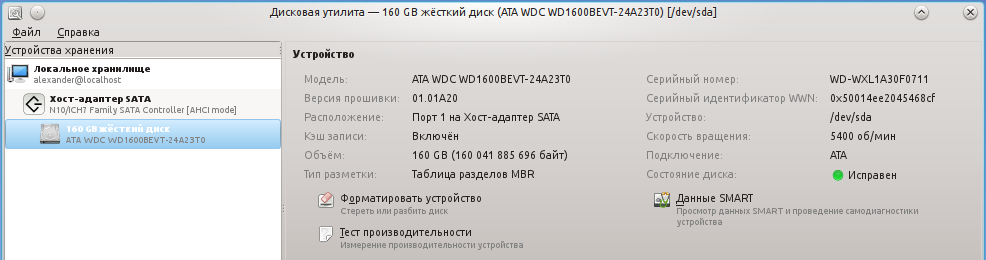
В поле «состояние диска» уже можно увидеть оценку состояния диска на основе данных S.M.A.R.T. Чтобы увидеть значение конкретных атрибутов нажимаем на кнопку «Данные SMART»: 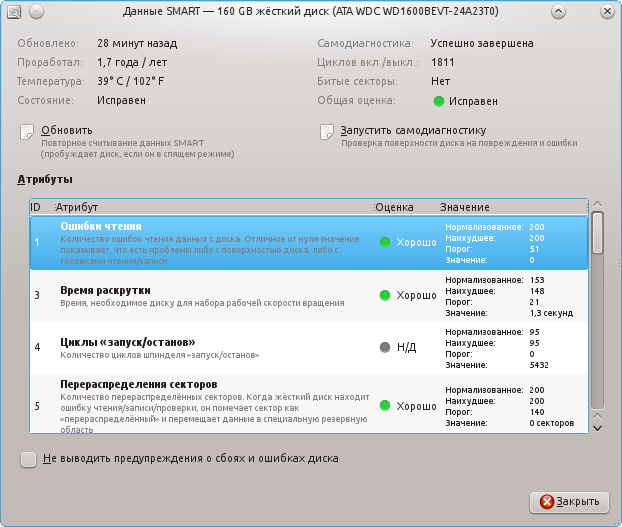
Пример данных о SSD (Твёрдотельном накопителе): 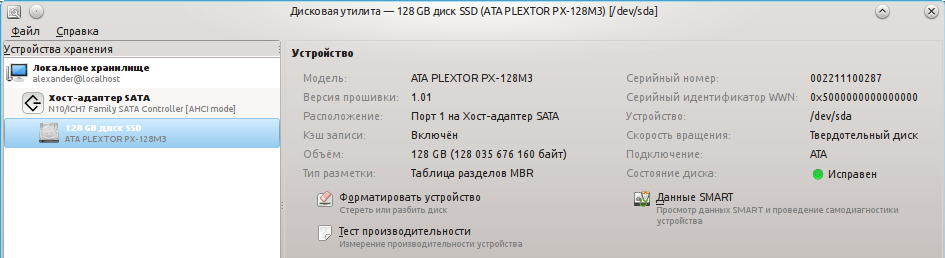
S.M.A.R.T.: 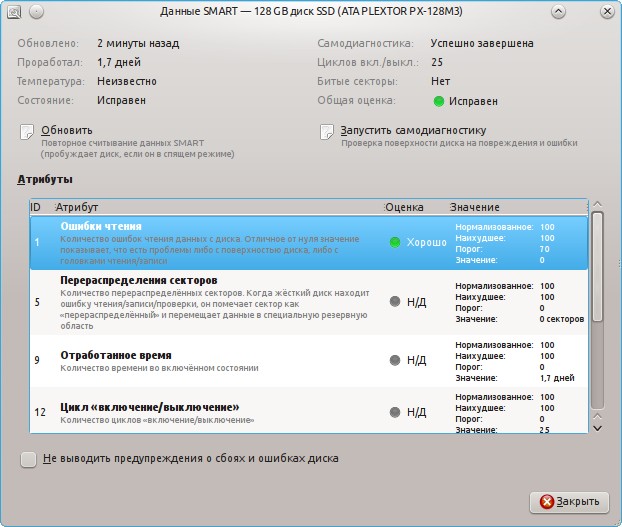
Здесь всё понятно и наглядно. Также присутствует описание атрибутов и оценка их показаний. Проблемные значения будут выделены красным цветом.
Источник
Мониторинг и проверка состояния SSD в Linux
И снова здравствуйте. Перевод следующей статьи подготовлен специально для студентов курса «Администратор Linux». Поехали!

Что такое S.M.A.R.T.?
S.M.A.R.T. (расшифровывается как Self-Monitoring, Analysis, and Reporting Technology) – это технология, вшитая в накопители, такие как жесткие диски или SSD. Ее основная задача – это мониторинг состояния.
На деле, S.M.A.R.T. контролирует несколько параметров во время обычной работы с диском. Он мониторит такие параметры как количество ошибок чтения, время запуска диска и даже состояние окружающей среды. Помимо этого, S.M.A.R.T. также может проводить тесты с использованием накопителя.
В идеале, S.M.A.R.T. позволит прогнозировать предсказуемые отказы, такие как отказы, вызванные механическим износом или ухудшением состояния поверхности диска, а также непредсказуемые отказы, вызванные каким-либо неожиданным дефектом. Поскольку обычно диски не выходят из строя внезапно, S.M.A.R.T. помогает операционной системе или системному администратору идентифицировать те диски, которые скоро выйдут из строя, чтобы их можно было заменить и избежать потери данных.
Что не относится к S.M.A.R.T.?
Все это, конечно, круто. Однако S.M.A.R.T. – это не хрустальный шар. Он не может спрогнозировать отказ со стопроцентной вероятностью и не может гарантировать, что накопитель не выйдет из строя без предупреждения. В лучшем случае S.M.A.R.T. стоит использовать для оценки вероятности поломки.
Учитывая статистический характер прогнозирования отказов, технология S.M.A.R.T. особенно интересует компании, использующие большое количество устройств для хранения данных. Чтобы выяснить, насколько точно S.M.A.R.T. может прогнозировать отказы и сообщать о необходимости замены дисков в центрах обработки данных или серверных мейнфреймах, даже проводились специальные исследования.
В 2016 году Microsoft и университет штата Пенсильвания провели исследование, связанное с SSD.
Согласно этому исследованию, некоторые атрибуты S.M.A.R.T. считаются хорошими индикаторами неизбежности отказа. В особенности в статье упоминаются:
Счетчик переназначенных (Realloc) секторов:
Несмотря на то, что основополагающие технологии радикально отличаются, этот показатель остается востребованным как в мире SSD, так и в мире жестких дисков. Стоит отметить, что из-за особенностей алгоритмов балансировки износа, используемых в SSD, когда несколько секторов выходят из строя, то с большой вероятностью можно предположить, что скоро выйдут из строя еще больше.
Ошибки в цикле Program/Erase (P/E):
Это признак проблем с основным оборудованием флеш-памяти, связанных с тем, что диск не может удалить данные из блока или сохранить их там. Дело в том, что процесс производства несовершенен, поэтому появление таких ошибок вполне можно ожидать. Однако флеш-память имеет ограниченное число циклов записи/удаления. По этой причине внезапное увеличение числа событий может сигнализировать о том, что диск достигает своего предела, и вполне ожидаемо, что другие ячейки памяти также начнут выходить из строя.
CRC и неисправимые ошибки («Data Error ”):
События такого типа могут быть вызваны ошибками хранения, либо проблемами с внутренним каналом связи накопителя. Этот индикатор учитывает как исправленные ошибки (без проблем сообщенные хост-системе), так и неисправленные ошибки (из-за которых происходит блокировка диска, сообщившего хост-системе о невозможности чтения). Другими словами, исправляемые ошибки невидимы для операционной системы, тем не менее они влияют на производительность накопителя, увеличивая вероятность переназначения сектора.
SATA downshift count:
Из-за временных помех, проблем с каналом связи между накопителем и хостом или из-за внутренних проблем с накопителем, интерфейс SATA может переключиться на более низкую скорость передачи сигналов. Снижение скорости соединения ниже номинального уровня оказывает очевидное влияние на производительность диска. Таким образом, этот показатель является наиболее значимым, в особенности, когда он коррелирует с наличием одного или нескольких предыдущих показателей.
Согласно исследованию, 62% вышедших из строя SSD показали наличие как минимум одного из вышеприведенных симптомов. С другой стороны можно сказать, что 38% изученных накопителей сломались без индикации этих симптомов. В исследованиях не упоминалось, были ли какие-то еще сообщения об отказах от S. M. A. R. T. по другим «симптомам». По этой причине нельзя напрямую сопоставить эти значения с отказом без предупреждения в 36% случаев из статьи от Google.
В исследовании Microsoft и университета штата Пенсильвания не раскрывались модели исследуемых дисков, однако, по словам авторов, большинство дисков поступают от одного и того же поставщика в течение уже нескольких поколений.
В ходе исследования также были отмечены значительные различия в надёжности между различными моделями. Например, «худшая» изученная модель показывает двадцатипроцентную частоту отказов через 9 месяцев после первой ошибки переназначения и до 36-ти процентов отказов в течение 9 месяцев после первого появления ошибок данных. «Худшей» моделью было названо более старое поколение дисков, рассматриваемых в статье.
С другой стороны, с теми же симптомами, что приведены выше, накопители нового поколения отказали в 3% и 20% в соответствии с теми же ошибками. Трудно сказать, можно ли объяснить эти цифры улучшением конструкции накопителя и производственного процесса, или здесь роль играет эффект устаревания накопителя.
Самое интересное, что упоминается в статье (я уже писал об этом ранее), так это то, что увеличение количества зарегистрированных ошибок может случить тревожным индикатором:
«Существует большая вероятность появления симптомов, предшествующих отказу SSD, которые активно себя проявляют и быстро прогрессируют, сильно сокращая время жизни накопителя до нескольких месяцев.»
Другими словами, одна случайная ошибка, о которой сообщил S.M.A.R.T., определенно не должна рассматриваться как сигнал о неизбежном отказе. Однако, когда исправный SSD начинает сообщать о все большем количестве ошибок, следует ждать краткосрочного или среднесрочного сбоя.
Но как узнать, в каком состоянии сейчас ваш SSD? Для удовлетворения своего любопытства, либо из желания начать внимательно следить за своими накопителями, вы можете использовать инструмент мониторинга smartctl .
Использование smartctl для мониторинга состояния вашего SSD в Linux
Чтобы следить за S.M.A.R.T статусом вашего диска, я предлагаю использовать инструмент smartctl , который является частью пакета smartmontool (по крайней мере на Debian/Ubuntu).
smartctl – это инструмент командной строки, но это особенно помогает в случаях, когда вам нужно автоматизировать сбор данных, например, с ваших серверов.
Первый шаг в использовании smartctl – это проверка того, есть ли на вашем диске S.M.A.R.T. и поддерживается ли он инструментом:
Как видите, мой внутренний жесткий диск ноутбука действительно поддерживает S.M.A.R.T. и он включен. Итак, как теперь получить S.M.A.R.T статус? Есть ли какие-то зафиксированные ошибки?
Выдача отчета «о всей S.M.A.R.T. информации о диске» — это опция -a :
Понимание выходных данных команд smartctl
На выходе получается много информации, которую не всегда легко понять. Наиболее интересной, вероятно, является та часть, которая помечена как “Vendor Specific SMART Attributes with Thresholds”. Она сообщает различные статистические данные, собранные S.M.A.R.T. устройством, и позволяет сравнить эти значения (текущие или худшие за все время) с некоторым порогом, определенным поставщиком.
Например, вот мои отчеты о переназначенных секторах на диске:
Вы можете заметить атрибут «Pre-fail». Он означает, что значение является аномальным. Таким образом, если значение превышает пороговое, велика вероятность сбоя. Другая категория »Old_age» используется для атрибутов, отвечающих значениям «нормального износа».
Последнее поле (здесь со значением «3») соответствует исходному значению атрибута, которое сообщает диск. Обычно это число имеет физическое значение. Здесь это фактическое количество переназначенных секторов. Для других атрибутов это может быть температура в градусах Цельсия, время в часах или минутах или количество раз, когда для диска было выполнено определенное условие.
В дополнение к исходному значению, диск с поддержкой S.M.A.R.T. должен сообщать «нормализованные значения» (значения полей, самые худшие и пороговые). Эти значения нормируются в диапазоне 1-254 (0-255 для пороговых значений). Прошивка диска выполняет эту нормализацию с помощью некоторого внутреннего алгоритма. Кроме того, разные производители могут нормализовать один и тот же атрибут по-разному. Большинство значений представлены в процентах, причем чем выше, тем лучше, но так бывает не всегда. Когда параметр ниже или равен пороговому значению, указанному производителем, диск считается неисправным в терминах этого атрибута. Помня о всех указаниях из первой части статьи, когда атрибут, показывающий ранее значение “pre-fail” все-таки дал сбой, наиболее вероятно, что скоро диск выйдет из строя.
В качестве второго примера возьмем “seek error rate”:
На самом деле (и это основная проблема отчетности S.M.A.R.T.), точное значение полей каждого атрибута понимает только поставщик. В моем случае Seagate использует логарифмическую шкалу для нормализации значения. Таким образом, «71» означает примерно одну ошибку на 10 миллионов запросов (10 в степени 7,1). Забавно, что самым худшим показателем за все время была одна ошибка на 1 миллион запросов (10 в 6-й степени).
Если я правильно понимаю, то это значит, что головки моего диска сейчас расположены точнее, чем раньше. Я не следил за этим диском внимательно, поэтому анализирую полученные данные весьма субъективно. Возможно накопитель просто надо было немного «обкатать» с тех пор как он был введен в эксплуатацию? Или может быть это следствие механического износа деталей и, следовательно, теперь имеет место меньшая сила трения? В любом случае, какова бы ни была причина, это значение является скорее показателем производительности, чем ранним предупреждением об ошибке. Так что меня оно не сильно беспокоит.
Помимо вышеприведенного и трех крайне подозрительных ошибок, записанных около шести месяцев назад, этот диск находится в удивительно хорошем состоянии (по данным S.M.A.R.T.) для стокового диска ноутбука, проработавшего более 1100 дней (26423 часа).
Из любопытства я провел этот же тест на гораздо более новом ноутбуке, оснащенном SSD:
Первое, что бросается в глаза, так это то, что несмотря на наличие S.M.A.R.T., устройства нет в базе данных smartctl . Но это не помешает инструменту собирать данные с SSD, однако он не сможет сообщить точные значения различных атрибутов, специфичных для поставщика:
Выше вы видите выходные данные абсолютно нового SSD. Данные понятны даже в случае отсутствия нормализации или метаинформации для данных конкретного поставщика, как в моем случае с “Unknown_SSD_Attribute.” Я могу только надеяться, что в последующих версиях smartctl в базе данных появятся данные об этой модели диска, и я смогу лучше определять потенциальные проблемы.
Проверьте свой SSD в Linux с помощью smartctl
До сих пор мы рассматривали данные, собранные во время нормальной работы накопителя. Однако протокол S.M.A.R.T. также поддерживает несколько команд для автономного тестирования для запуска диагностики по требованию.
Автономное тестирование может проводиться во время обычных операций с диском, если не было указано иное. Поскольку тест и запросы ввода-вывода хоста будут конкурировать, производительность диска упадет на время теста. Спецификация S.M.A.R.T. определяет несколько видов автономного тестирования:
Короткое автономное тестирование ( -t short )
Такой тест проверит электрическую и механическую, производительность, а также производительность чтения диска. Короткое автономное тестирование обычно занимает всего несколько минут (обычно от 2 до 10).
Расширенное автономное тестирование ( -t long )
Этот тест занимает почти в два раза больше времени. Как правило, это просто более детальная версия короткого автономного тестирования. Кроме того, этот тест будет сканировать всю поверхность диска на наличие ошибок данных без ограничения по времени. Продолжительность теста будет пропорциональна размеру диска.
Транспортировочное автономное тестирование ( -t conveyance )
Этот тестовый набор предложен в качестве сравнительно быстрого способа проверки на возможные повреждения, возникшие во время транспортировки устройства.
Вот примеры, взятые с тех же дисков, что были выше. Я предлагаю вам угадать, где какой:
Сейчас производится проверка. Давайте дождемся завершения, чтобы посмотреть результат:
Проведем тот же тест на другом диске:
И еще раз, отправим в сон на две минуты и посмотрим результат:
Интересно, что в этом случае мы видим, что производители диска и компьютера, похоже, уже тестировали диск (на времени жизни в 0 часов и 12 часов). Я сам определенно был гораздо менее озабочен состоянием диска, чем они. Итак, поскольку я уже показал быстрые тесты, то и расширенный тоже запущу, чтобы посмотреть как это происходит.
Судя по всему на этот раз ждать придется гораздо дольше, чем при проведении короткого теста. Так что давайте посмотрим:
В последнем тесте обратите внимание на различие в результатах, полученных с помощью короткого и расширенного теста, даже если они были выполнены один за другим. Ну, возможно, этот диск не в таком уж и хорошем состоянии! Отмечу, что тест остановился после первой ошибки чтения. Поэтому, если вы хотите получить исчерпывающую информацию обо всех ошибках чтения, вам придется продолжать тест после каждой ошибки. Я призываю вас взглянуть на одну очень хорошо написанную страницу руководства smartctl(8) для получения дополнительной информации о параметрах -t select , N-max и -t select , чтобы уметь делать так:
Источник



