- Изменение скрипта мониторинга лога
- Скрипт мониторинга лога и проверка события по времени
- Мониторинг лог файла, и выполненине команды при наступлении события.
- bash + logger варанты применения
- Средства мониторинга Linux системы (часть 1?)
- Log-файлы (журналы)
- Правки в файлах
- Какова загрузка системы?(LoadAverage)
- Что происходит в системе (процессы)
- ps — process status
- В заключение…
Изменение скрипта мониторинга лога
Добрый день. Я начинающий пользователь Linux. Уровень знаний на уровне (знаю основные команды и не боюсь работать в терминале). Сейчас приступил к изучению Bash и чеееерт! Это очень сложно и непонятно. От слова совсем, но я не унываю. В общем соори за столь длинное введение. В чем суть? Есть задача:
«Изменить скрипт мониторинга лога, чтобы он выводил сообщения при попытке неудачной аутентификации пользователя /var/log/auth.log, отслеживая сообщения примерно такого вида…..»
Я не могу понять где находится сам скрипт, который формирует «auth.log».
Гуглил, ответа не нашел пока. Очень много информации про Syslog — ковырял, но не то.

Я не могу понять где находится сам скрипт, который формирует «auth.log».
тебе это и не нужно. ты будешь работать не с источником данных ( syslog ), а с потребителем ( скрипт мониторинга )
Очень много информации про Syslog
файл создаёт именно сервер syslog. Точнее, одна из реализаций. Скорее всего rsyslog, но также могут быть syslog-ng, syslogd и другие
но ещё раз, это тебе не нужно
Не понял. Что мне нужно поменять чтоб изменить вывод сообщения в лог: К примеру на такое?
May 16 19:45:52 vlamp login[102782]: FAILED LOGIN (1) on ‘/dev/tty3’ FOR ‘user’, Authentication failure
Где именно находится скрипт мониторинга?

Что мне нужно поменять чтоб изменить вывод сообщения в лог: К примеру на такое?
Ничего. У тебя же в задании «Изменить скрипт мониторинга лога». Есть лог — это /var/log/auth.log, и есть некий скрипт, который должен отслеживать этот лог на предмет определенных сообщений. Вот этот скрипт тебе и нужно либо написать, либо изменить.
Добрый человек! Спасибо, большое судя по всему я неправильно понял задание.
Источник
Скрипт мониторинга лога и проверка события по времени
Всем доброго времени суток.
Есть лог fetchmail, если fetchmail не смог подключиться к серверу и забрать почту в течении 10 секунд, то валится ошибка. Хочу проверить, смогу ли зацепиться к серверу telnet в этот момент. Понимаю, что тест не идеальный.
Накатал такую штуку. Подскажите, насколько это правильно, а то иногда он не правильно срабатывает. Сверяюсь с логом самого fetchmail.
Прогони по shellcheck и удивись
Он посоветовал мне операцию суммирования заменить на другую. Заменил, картина та же.
Да и, мой вопрос связан не только со скриптом. Как нужно в принципе подходить к тестированию подобного рода вещей? Потому что факт того, что попытка соединения к одному почтовому ящику была неудачной не означает, что если я попробую подключиться к серверу в этот момент он тоже меня пошлет.
Это разовое тестирование. А вот «почему не», это я не сообразил да. Подскажите, подобного рода тестирование в принципе имеет какой-то профит? Интересно просто мнение.
tail -f -n 1 /var/log/fetchmail.log > /tmp/fetch_check &
Не лучше ли проверять exit code fetchmail’а?
Так он не завершается. Он просто сообщает в лог, что таймаут на соединение с таким-то ящиком и идет дальше. Или, я не правильно вас понял?
Мда, я затупил и не догадался что он демоном работает.
Тогда у меня нет идей, особенно с учетом того как вы правильно выше заметили о том что нет гарантии воспроизведения этой ошибке при обращении к серверу телнетом.
А скрипт в терминале выполняется или как демон? Консоль у него есть? Если нет, то что делать бедному телнету? Алсо у nc есть режим проверки возможности подключения, мне кажется ты хотел использовать именно его.
Скрипт проверки в терминале отрабатывает. По сути, мне бы просто сам факт соединения и всё. Но, я смотрю на свой скрипт и понимаю, что он делает фигню. Поэтому, сначала надо додумать. Про netcat почитаю, спасибо.
Не так уж и фигню. Просто уж возврата telnet/netcat надо проверять и сохранять. Так ты будешь знать, что сбои связаны не с фетчмейлом, а с пропавшим интернетом (или яндекс закрылся, что по нынешним временам не так уж невероятно).
Подскажите, подобного рода тестирование в принципе имеет какой-то профит? Интересно просто мнение.
Обычно начинают с просмотров логов (того же fetchmail в данном случае), при необходимости повышают уровень логирования, то есть делают логи более детальными. Плюс смотрят другие логи, например, системные; ну, и систему мониторинга, если Enterprise. Как правило этого достаточно. То, что ты приводишь — потенциально может быть, если логов не хватает, проблема плавающая, краткосрочная и проявляется нечасто. Но это бывает очень редко. На моей памяти (over 10 лет) такое было один раз, при том на домашнем компьютере, притом причиной оказался битый SATA кабель, из-за чего глючил жесткий диск.
Меня смущала логика изначального скрипта. Переписал так, что изначально счетчик на ноль и предыдущая строка пустая. Затем мы сравниваем текущую строку и предыдущую и если они совпадают на протяжении 9 секунд, то на последней проверяем соединение. А если текущая строка и прошла отличаются, то сбрасываем счетчик. Изначально, было по моему не верно.
Для начала перепиши это с г-баша на уместный язык (пистон, пирл). Потом будет разбираться с тем, что напишешь.
Штука в том, что в лог fetchmail пишет банальные:
Такое бывало раньше, помогало сообщить в яндекс. В этот раз они предложили протестировать. Изучаю механизмы. А то начальство грешит, что яндекс ай-яй-яй и делает это специально. 🙂
А зачем проверять строки на совпадение, если можно просто грепать на предмет «timeout after 10 seconds waiting for server imap.yandex.ru»?
К следующему юзеру в списке fetchmail коннектится уже нормально. Т.е. нет такого, что он прошел подряд 10 человек и всем 10 выдал таймаут. Поэтому, пытаюсь попасть в окно когда fetchmail стучится до яндекса.

запустить tcpdump/tshark и посмотреть сессию и причину отваливания?
После каждого ротирования логов эта конструкция будет переставать работать.
Источник
Мониторинг лог файла, и выполненине команды при наступлении события.
Задача, мониторить файл:
На предмет появления строки-шаблона:
При появлении такой строки, надо выдернуть: vasya и 192.168.1.43, после чего запустить сценарий:
Вроде задача не сложная. Но. Как бы красивее? Видел утилиту monit. — Она мне пойдёт? Или что-то попроще есть? Может fail2ban.

logstash бы посоветовал. но слишком жирный комбайн.
tailf +grep + xargs -l1 script.sh
в script.sh парсишь переменную «$@» своими методами.
check_log из нагиоса
Мне не надобен мониторинг, мне надобно обновлять ddns records при наступлении события.
Или ты имеешь ввиду, что я могу поставить nagius агента, без самого сервера, и выдернуть эту штуковину оттуда?
Спасибо! Выглядит годно!
да, это независимый бинарник
тут можно нарваться на буферизацию вывода в пайп
Да, тут я уже вижу нюансы. С tailf.
а какая задержка допустима? секунда, минута, час.
Спасибо тебе ОГРОМНЕЙШЕЕ! Сейчас погляжу как оно. 🙂
тогда поправка: system(«/usr/bin/action.sh $1 $2») вместо qx(. ). Интерполяция и всё такое.
ну и unbuffer не забудь, если у тебя expect, или stdbuf в другом случае.
СПАСИБО тебе огромное, всё работает! Не очень понял, в чём разница между system и qx? В двух словах если не трудно. 🙂 Я ведь в продакшен кину и в скрипте укажу твой ник, чтобы увековечиь! 😀

Такс, я далёк от программирования, у меня в сценарии примерно такое:
Какие буфера, мне следует учесть?
Объясню зачем мне это нужно: у меня есть ЗООПАРК, из linux/windows (Home/pro) машинок, часть в домене, часть вне его. Нужно всё это барахло админить по VNC, вопрос в том, по какому имени dns подключаться? — Именовать компьютеры как фамилии сотрудников — не гуд + бывают ноутбуки залётные и т.п. — А вот сейчас собираюсь менять jabber сервер, и в логах увидел нужные строчки, а с тем учётом, что jabber есть у всех, в т.ч. у VPNнщиков, то. Кажется проблема, которая мучила меня, и не только меня — РЕШЕНА! Теперь в jabber, в pidgin можно будет заглянуть и найти почту, плюс понять как оказать помощь человеку по vnc.
OpenSource во все поля 🙂
tailf и tail -f — одно и тоже. 🙂
не совсем. У меня в слаке /bin/tail входит в минимальную систему, а /usr/bin/tailf это опционально, и в принципе может и не быть. Как в других дистрах я не помню.
а нет более стандартного и менее велосипедного решения?
Пока не удалось найти ничего более удобного. Реально искал. В итоге запилили ddns+samba4+ldap+kerberos+squid+openvpn+ejabberd+freeradius (для wifi). Клиентам поставили vnc, linux загнал в домен, PRO винды — загнал в домен, всем остальным поставил MIT Kerberos + keytab сгенерил ну или ручками вбивают пассворд для билетов.
тогда не трожь 😀
Окей! 🙂 Но буду иметь ввиду если чего. Я пока не клал в фон ещё сиё дело. 🙂 Спасибо ещё раз!
Источник
bash + logger варанты применения
Повседневные задачи администрирования Linux требуют автоматизации. Как правило, автоматизация сводится к написанию bash скриптов и их «ротации по крону», либо выполнении вручную, в зависимости от задачи. В этой заметке собраны часто встречающиеся практики логирования bash скриптов. Целевая аудитория — системные администраторы linux.
Самый простой и очевидный способ сохранить вывод скрипта это просто перенаправить его в файл.
На самом деле, нужно добавить к выводу STDERR, потому, как сообщения об ошибках пишутся именно в него:
Это считается нормальной практикой и обычно удовлетворяет большую часть системных администраторов. Но если серверов несколько(десятков, сотен), и логирование централизованно, удобнее использовать logger. Напомню, что logger это утилита, которая отправляет сообщения в syslog.
Плюсы такого подхода в том, что можно перенаправлять вывод не только bash скриптов.
Минусы — невозможно отделить сообщения об ошибках от других информационных сообщений, так как в этом примере вывод слеплен в один поток и все это попадает в syslog с приоритетом user.notice(приоритет по умолчанию).
Для некоторых задач допустимо применение следующего варианта:
В этом варианте логируется только STDERR (STDOUT перенаправляется в /dev/null) с приоритетом error. Также сообщения помечаются тегом с названием скрипта. Все это может упростить поиск и устранения неисправностей в работе скриптов.
Минусом этого подхода является то, что мы теряем STDOUT. Чтобы решить эту проблему можно использовать перенаправление потоков вывода непосредственно внутри скрипта.
Этот пример иллюстрирует как можно перенаправить STDOUT и STDERR независимо друг от друга. К сожалению, этот способ порождает неожиданную проблему: сообщения из разных потоков могут попадать в syslog не в том порядке, в котором были отправлены. Такое поведение связано с тем, что потоки обрабатываются как два независимых друг от друга процесса. Не смотря на это, способ часто применяется для логирования скриптов, запускаемых cron.
Но иногда требуется запускать скрипт вручную, и в этом случае не всегда удобно следить за его работой в syslog.
В этом примере tee копирует «входящий» поток в logger и обратно — в STDOUT(поведение по умолчанию), а во втором случае в STDERR. Таким образом мы получаем логирование в syslog + вывод на консоль во время выполнения, что бывает полезно для скриптов, запускаемых вручную.
Логи в syslog — это просто.
Логи в syslog — это полезно, особенно если логирование централизованно. При параллельном перенаправленнии потоков вывода — следует помнить о возможном нарушении порядка следования сообщений.
Источник
Средства мониторинга Linux системы (часть 1?)
Короче, продолжаем. Теперь я для вас подготовил некую уже не маленькую статью, на тему мониторинга Linux систем. В некотором роде эта статья мне будет служить в качестве мини-справочника по необходимым командам, для того, чтобы можно было понимать, все ли нормально с системой. Поговорим об основных командах типа top/htop/uptime/ps, о том где какие логи лежат и что они означают и так далее. Короче, начнем..
Log-файлы (журналы)
Все логи по умолчанию хоронятся в директории /var/log/ (ну так принято по стандарту иерархии файловой системы) и эти файлы — сведения о происходящих процессах в системе. Кстати, если вы поддерживайте систему, которая может быть интересна взломщикам, то настоятельно рекомендуется обзавестись системой дублирования логов, например, на туже почту. Взломщик будет думать, что все «зачистил» за собой, но доказательства его пребывания в системе останутся. Но речь не об этом..
Рассмотрим пример стандартных файлов в директории /var/log/, на примере ОС Debian Linux 7:
- /var/log/syslog — syslog является основным системным журналом и в нем сохраняются сообщения демонов и других программ, работающих в системе, например, dhclient, cron, init, xscreensaver, а также некоторые сообщения ядра. Этот журнал — первое место, откуда надо начинать просмотр при попытке отследить типичные системные ошибки
- /var/log/auth.log — содержит информацию системы авторизации, в том числе логины и механизм проверки подлинности, которые были использованы
- /var/log/daemon.log — содержит информацию о различных демонах/сервисах запущенных в системе. С помощью него можно находить проблемы во время падения системы
- /var/log/dmesg — в файле содержаться все сообщения ядра, начиная с этапа загрузки системы, а просмотреть содержимое этого файла можно используя команду dmesg
- /var/log/kern.log — файл журнала ядра, предоставляет подробный лог сообщений от ядра Linux, которые могут быть полезны при анализе и устранении неисправностей
- /var/log/messages — файл содержит глобальные настройки, в том числе сообщения, которые регистрируются при запуске системы
- /var/log/debug — журнал отладки, предоставляющий подробную отладочную информацию системы и приложений, которые используют syslogd для отладки
- /var/log/user.log — содержит информацию о всех журналах на уровне пользователя
- /var/log/btmp — файл содержит записи обо всех неудавшихся попытках регистрации пользователей в системе. Посмотреть неудачные попытки входа в систему можно с помощью команды lastb
- /var/log/faillog — в этом файле хранится число неудачных попыток входа в систему и их предельное число для каждой учётной записи. А если в консоли ввести команду faillog, то можно увидеть содержимое этого файла
- /var/log/mail.log, /var/log/mail.err, /var/log/mail.info, /var/log/mail.warn — файлы журналирующие почтовые события
- /var/log/lastlog — файл содержащий записи о предыдущих входах в систему
- var/log/apt — директория содержит информацию, которая пишется при установки/удалении пакета с помощью программы apt
- /var/log/alternatives.log — файл программы update-alternatives, которая является механизмом выбора предпочтительного ПО среди нескольких вариантов в таких дистрибутивах Linux, как Debian и Ubuntu
- /var/log/aptitude — файл программы aptitude содержащий информацию об установке/удалении пакетов
- /var/log/dbconfig-common — в случае использования утилиты dbconfig все действия будут журналироваться в файлах, в этой лиректории
- /var/log/dpkg.log — файл содержит информацию, которая пишется при установки/удалении пакета с помощью программы dpkg
- /var/log/fsck — если в вашей системе запускалась проверка файловой системы то она будет журналироваться в файлы находящиеся в этой директории
- /var/log/wtmp — файл содержит двоичные данные о времени регистрации и продолжительность работы всех пользователей системы. Он пользуется командой last для вывода списка регистрировавшихся пользователей
- /var/log/apache2 — если в вашей системе установлен apache, то в данной директории будут находиться журналы access_log и error_log
- /var/log/mysql.err и /var/log/mail.info — если у вас установлена СУБД MySQL, то в этих файлах будут журналироваться сведения о работе и об ошибках СУБД
Теперь приведем пример, что когда нам понадобится..
- Если у нас не запускается какая то служба, то имеет смысл посмотреть файл /var/log/syslog, хотя скажу сразу, туда логируется почти все, даже bind9, если таковой стоит, поэтому лучше смотреть этот файл при помощи «tail -f»:
- Если есть какие-то проблемы с системой, то можно воспользоваться такими командами, как dmesg, messages, debug
- Все что касается почтовой службы, мы можем просматривать в файлах var/log/mail.log, /var/log/mail.err, /var/log/mail.info, /var/log/mail.warn, но если у вас установлен exim или postfix, то у них уже будут свои log-файлы в своих директориях
- Чтобы понять, кто и когда заходил в систему, можно ввести команду last, все неудачные попытки входа в систему можно увидеть при помощи команды lastb
- Если мы хотим проверить, нормально ли установилось то или иное приложение, то стоит заглянуть в файлы dpkg.log, apt или aptitude (ну все зависит от того, как вы ставили то или иное приложение)
На этом про логи, я думаю, достаточно..
Правки в файлах
Иногда бывает полезно выявлять факты изменения файлов в такой директории, как /etc, особенно, если администрированием сервера занимайтесь не только вы. Сделать это все можно при помощи команды find с параметром -mtime. Например, следующая команда покажет файлы, которые были изменение в течении последних двух суток:
Более подробно поиск по различным временам описан тут.
Какова загрузка системы?(LoadAverage)
Вы наверное часто обращали внимание на такую строчку, как LoadAverage, которая показывает числа. Собственно эти числа отображают число блокирующих процессов на исполнение в определенный интервал времени, а именно 1 минута, 5 минут и 15 минут. Под блокирующим процессом подразумевается процесс, который ждет ресурсы для того, чтобы продолжить свою работу, а под ресурсами подразумевается ЦП, дисковая подсистема ввода вывода и сетевая подсистема ввода/вывода.
Не обязательно быть специалистом, чтобы понимать, что высокие показатели LA говорят о том, что система не справляется, например эти цифры могут говорить об аппаратных проблемах.
Чтобы посмотреть эти показания, достаточно воспользоваться командой top или uptime (о top мы поговорим несколько позднее)
Большинство (как и я ) будут думать, что чем меньше эти числа, тем лучше, но нужно понимать, когда бить тревогу, если значения этих цифр начнет расти.
Отличная аналогия «на машинках» о том, что эти цифры обозначают приведена в статье на хабре, поэтому приведу краткую выдержку от туда: представим, что одноядерный процессор это однополосный мост, а мы управляем движением на этом мосту. Если мост перегружен, то машины ждут (ну или стоят в пробке). Собственно количество машин в очереди это и есть то число, которое вы видите. Пример можно увидеть на этих картинках из этой прекрасной статьи:
 load average = 0.50
load average = 0.50  load average = 1.00
load average = 1.00  load average = 1.70
load average = 1.70
Исходя из того, что мы видим, можно понять, что Load Average равный 1,00 — идеальное значение, но это не так. Идеальным значением для меня можно считать 0,50 ну или на худой конец 0,70, так как должен сохраняться какой-то запас на случай внезапной нагрузки или нештатного поведения той или иной программы.
И имейте в виду, пример выше это пример для одноядерного процессора. Если у вас четырехядерный процессор или два двухядерных процессора, то идеальным LA для вас будет 2,00 или 2,80.
Теперь подытожим эту тему,
- Какое значение лучше смотреть? За минуту, 5 минут или 15 минут?
Если на одноядерном процессоре LA за 5 или 15 минут, то следует на это обратить внимание - Как понять сколько процессоров в системе?
ну тут все просто, нужно отфильтровать grep-ом вывод cpuinfo:
Что происходит в системе (процессы)
Собственно. чтобы увидеть эти показатели, понять, где у нас есть проблемы, и вообще получить информацию о процессах воспользуемся утилитой top:
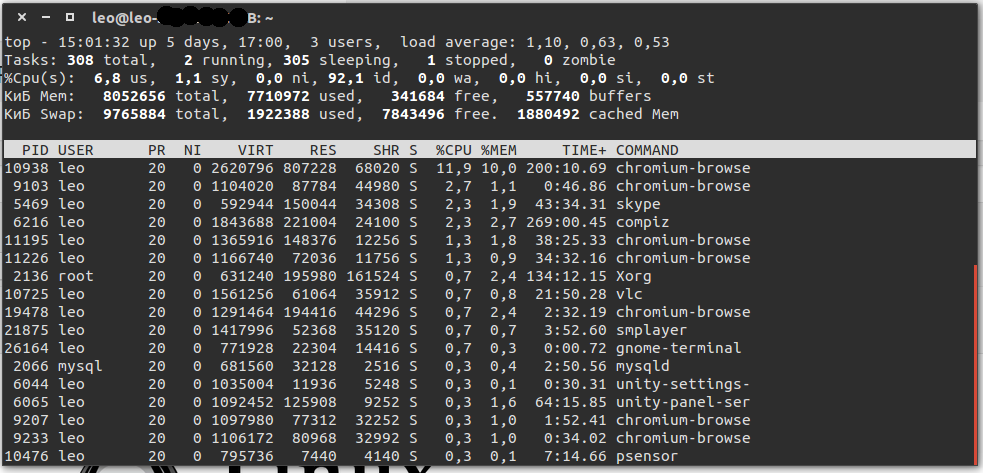
Рассмотрим по порядку, что есть что:
- Общая информация:
- текущем времени
- uptime времени (сколько система работает)
- количество пользовательских сессий (3 users)
- LoadAverage (ну о нем написан целый раздел)
- Статистика процессов:
- общее количество процессов в системе
- количество работающих в данный момент процессов
- количество спящих процессов (они работающие, просто «ждут» события)
- количество остановленных событий (я их останавливаю с помощью команды ctrl+z)
- количество процессов, ожидающих родительский процесс для передачи статуса завершения (0 zombie)
- Статистика использования CPU:
- 6,8 us — процент использования центрального процессора пользовательскими процессам
- 1.1 sy — процент использования центрального процессора системными процессами
- 0.0 ni — процент использования центрального процессора процессами с приоритетом, повышенным при помощи вызова nice
- 92.1 id (id это idle cpu time, т.е. время простоя CPU) — процент простоя процессора
- 0.0 wa — процент использования центрального процессора процессами, ожидающими завершения операций ввода-вывода (например чтение/запись на диск)
- 0.0 hi (hi это Hardware IRQ, т.е. аппаратные прерывания) — процент использования центрального процессора обработчиками аппаратных прерываний
- 0.0 si (si это Software Interrupts, т.е. программные прерывания) — процент использования центрального процессора обработчиками программных прерываний
- 0.0 st (st это Steal Time , т.е. заимствованное время) — количество ресурсов центрального процессора «заимствованных» у виртуальной машины гипервизором для других задач (таких, как запуск другой виртуальной машины); это значение будет равно нулю на не использующих виртуальные машины
- Статистика использования физической и swap памяти:
- общее количество памяти (total)
- количество используемой памяти (used)
- количество свободной памяти (free)
- количество памяти в кэше буферов (buffers)
- Список процессов, отсортированный по степени использования центрального процессора (по умолчанию), опишем столбцы:
- PID — идентификатор процесса
- USER — имя пользователя, который является владельцем процесса
- PR — приоритет процесса
- NI — значение «NICE», влияющие на приоритет процесса
- VIRT — объем виртуальной памяти, используемый процессом
- RES — объем физической памяти, используемый процессом
- SHR — объем разделяемой памяти процесса
- S — указывает на статус процесса: S=sleep (ожидает событий) R=running (работает) Z=zombie (ожидает родительский процесс)
- %CPU — процент использования центрального процессора данным процессом (0.3)
- %MEM — процент использования оперативной памяти данным процессом (0.7)
- TIME+ — общее время активности процесса (0:17.75)
- COMMAND — имя процесса (bb_monitor.pl)
Что нам тут интересно? Да интересно почти все :). Например, статистика CPU: высокие значения (более 80%) параметра wa говорят о простое из-за ввода вывода, что может говорить о проблемах с HDD. Кстати, если сложить все эти значения, то у вас получится 100%.
Что мы там можем делать в утилите top?
- Нажав на клавишу k мы можем убить процесс, достаточно будет ввести его PID
- нажав на клавишу u и введя имя пользователя мы можем увидеть все процессы определенного пользователя
- нажав на клавишу b или z и работающие процессы будут выделены цветом
Более подробнее о ключах top можно почитать в страницах man. Кстати, есть еще и отличный аналог утилиты top — htop:
ps — process status
Существует еще генератор снимков процессов ps. Подробнее о нем можно почитать его man, а ниже я приведу примеры использования этой команды:
- при помощи следующей команды мы можем выяснить, выполняется ли в данный момент программа apache:
- набрав в терминале следующую команду мы можем получить всю информацию о всех процессах всех пользователей в системе:
Этого я думаю достаточно. Есть еще масса интересных примеров на просторах интернета, например тут.
В заключение…
начиная писать эту статью, я не думал что все получится на столько громоздко, поэтому еще будет как минимум вторая или третья часть средств мониторинга linux систем.
Источник



