- Как определить кодировку файла или строки. Как конвертировать файлы в кодировку UTF-8 в Linux
- Программы для определения кодировки в Linux
- Команда file -i показывает неверную кодировку
- Программа enca для определения кодировки файла
- Как определить кодировку строки
- Изменение кодировки в Linux
- Использование команды iconv
- Конвертирование файлов из windows-1251 в UTF-8 кодировку
- Изменение кодировки программой enca
- Конвертация строки в правильную кодировку
- Кодировка в Gedit
- Содержание
- Описание проблемы
- Настройка Gedit на автоопределение кодировки
- Смена кодировки открытого файла
- Локализация Ubuntu Server 18.04 LTS
- Текущие настройки языка
- Список доступных локалей
- Добавить новую локаль
- Подробная информация о локалях
- Локаль по-умолчанию
- Быстрая локализация
- Удалить лишние локали
- Переводы для системных программ
- Локализация для текущей сессии
- Файлы конфигурации шрифта и клавиатуры
- Настройка шрифта и клавиатуры
- HowTo: Check and Change File Encoding In Linux
- Check a File’s Encoding
- Change a File’s Encoding
- List All Charsets
- 8 Replies to “HowTo: Check and Change File Encoding In Linux”
Как определить кодировку файла или строки. Как конвертировать файлы в кодировку UTF-8 в Linux
В этой инструкции мы опишем что такое кодировка символов и рассмотрим несколько примеров конвертации файлов из одной кодировки в другую с использованием инструмента командной строки. Наконец, мы узнаем, как на Linux конвертировать несколько файлов из одного набора символов (charset) в UTF-8 кодировку.
Возможно, вы уже в курсе, что компьютер не понимает и не сохраняет буквы, числа или что-то ещё чем обычно оперируют люди. Компьютер работает с битами. Бит имеет только два возможных значения: 0 или 1, «истина» или «ложь», «да» или «нет». Все другие вещи, вроде букв, цифр, изображений должны быть представлены в битах, чтобы компьютер мог их обрабатывать.
Говоря простыми словами, кодировка символов – это способ информирования компьютера о том, как интерпретировать исходные нули и единицы в реальные символы, где символ представлен набором чисел. Когда мы печатаем текст в файле, слова и предложения, которые мы формируем, готовятся из разных символов, а символы упорядочиваются в кодировку.
Имеются различные схемы кодирования, среди них такие как ASCII, ANSI, Unicode. Ниже пример ASCII кодировки.
Программы для определения кодировки в Linux
Команда file -i показывает неверную кодировку
Чтобы узнать кодировку файла используется команда file с флагами -i или —mime, которые включают вывод строки с типом MIME. Пример:

Команда file показывает кодировки, но для одного из моих файлов она неверна. Рассмотрим ещё одну альтернативу.
Программа enca для определения кодировки файла
Утилита enca определяет кодировку текстовых файлов и, если нужно, конвертирует их.
Установим программу enca:
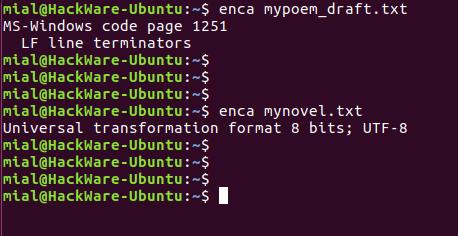
В этот раз для обоих файлов кодировка определена верно.
Запуск команды без опции выводит что-то вроде:
Это удобно для чтения людьми. Для использования вывода программы в скриптах есть опция -e, она выводит только универсальное имя, используемое в enca:
Если вам нужно имя, которое используется для названия кодировок в iconv, то для этого воспользуйтесь опцией -i:
Для вывода предпочитаемого MIME имени кодировки используется опция -m:
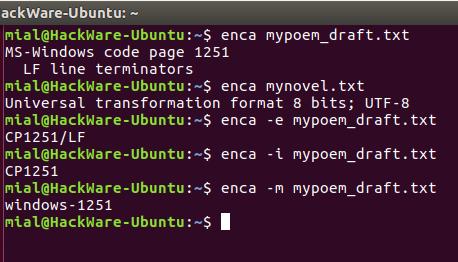
Для правильного определения кодировки программе enca нужно знать язык файла. Она получает эти данные от локали. Получается, если локаль вашей системы отличается от языка документа, то программа не сможет определить кодировку.
Язык документа можно явно указать опцией -L:
Чтобы узнать список доступных языков наберите:
Как определить кодировку строки
Для определения, в какой кодировке строка, используйте одну из следующих конструкций:
Вместо СТРОКА_ДЛЯ_ПРОВЕРКИ впишите строку, для которой нужно узнать кодировку. Если у вас строка не на русском языке, то откорректируйте значение опции -L.
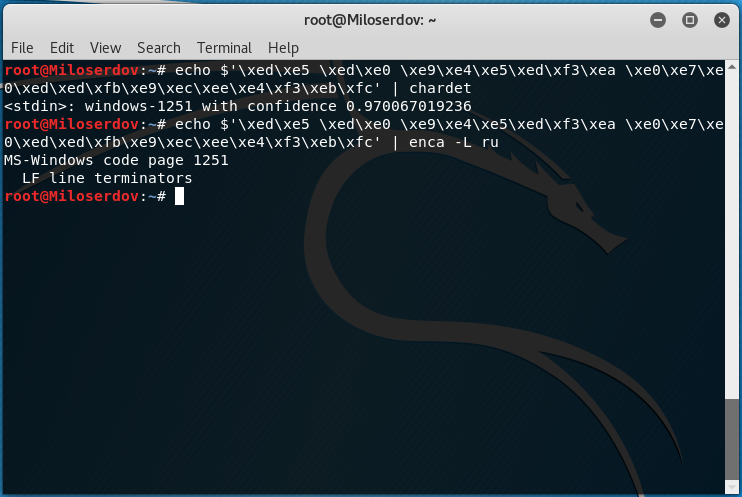
Если возникло сообщение об ошибке:
то попробуйте установить chardet из стандартных репозиториев.
Если chardet не найдена в репозиториях, то поищите программу uchardet, затем установите и используйте её.
Изменение кодировки в Linux
Использование команды iconv
В Linux для конвертации текста из одной кодировки в другую используется команда iconv.
Синтаксис использования iconv имеет следующий вид:
Где -f или —from-code означает кодировку исходного файла -t или —to-encoding указывают кодировку нового файла. Флаг -o является необязательным, если его нет, то содержимое документа в новой кодировке будет показано в стандартном выводе.
Чтобы вывести список всех кодировок, запустите команду:

Конвертирование файлов из windows-1251 в UTF-8 кодировку
Далее мы научимся, как конвертировать файлы из одной схемы кодирования (кодировки) в другую. В качестве примера наша команда будет конвертировать из windows-1251 (которая также называется CP1251) в UTF-8 кодировку.
Допустим, у нас есть файл mypoem_draft.txt его содержимое выводится как
Мы начнём с проверки кодировки символов в файле, просмотрим содержимое файла, выполним конвертирование и просмотрим содержимое файла ещё раз.
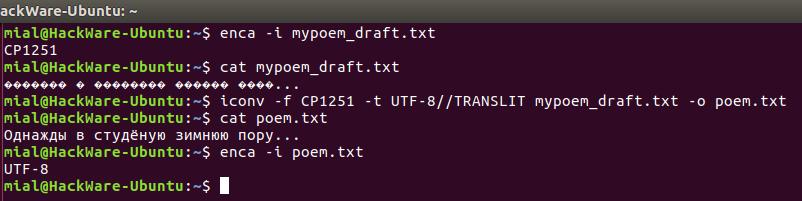
Примечание: если к кодировке, в который мы конвертируем файл добавить строку //IGNORE, то символы, которые невозможно конвертировать, будут отбрасываться и после конвертации показана ошибка.
Если к конечной кодировке добавляется строка //TRANSLIT, конвертируемые символы при необходимости и возможности будут транслитерированы. Это означает, когда символ не может быть представлен в целевом наборе символов, он может быть заменён одним или несколькими выглядящими похоже символами. Символы, которые вне целевого набора символов и не могут быть транслитерированы, в выводе заменяются знаком вопроса (?).
Изменение кодировки программой enca
Программа enca не только умеет определять кодировку, но и может конвертировать текстовые файлы в другую кодировку. Особенностью программы является то, что она не создаёт новый файл, а изменяет кодировку в исходном. Желаемую кодировку нужно указать после ключа -x:
Конвертация строки в правильную кодировку
Команда iconv может конвертировать строки в нужную кодировку. Для этого строка передаётся по стандартному вводу. Достаточно использовать только опцию -f для указания кодировки, в которую должна быть преобразована строка. Т.е. используется команда следующего вида:

Также для изменения кодировки применяются программы:
- piconv
- recode
- enconv (другое название enca)
Источник
Кодировка в Gedit
Содержание
Описание проблемы
Ubuntu по умолчанию использует кодировку текстовых файлов UTF-8, однако некоторые операционные системы используют другие кодировки (например, русская версия Microsoft Windows использует CP-1251). Из-за разницы в кодировках могут возникнуть проблемы при открытии текстовых файлов в редакторе Gedit — они будут нечитаемыми. Данная статья предлагает несколько простых способов решения этой проблемы.
Настройка Gedit на автоопределение кодировки
Gedit может автоматически определить нужную кодировку. Для этого его нужно немного настроить.
Есть 3 варианта:
Вариант 1.
Запускаем dconf-editor и переходим в
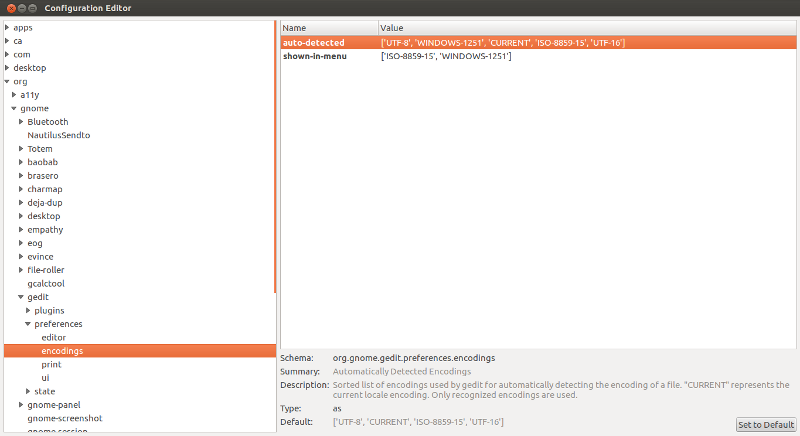
Редактируем ключ auto_detected 3) , вписывая нужную нам кодировку
Вариант 2.
Выполните в терминале команду:
Откроется Редактор Конфигурации GNOME. В нем откройте для редактирования ключ auto_detected 4) . 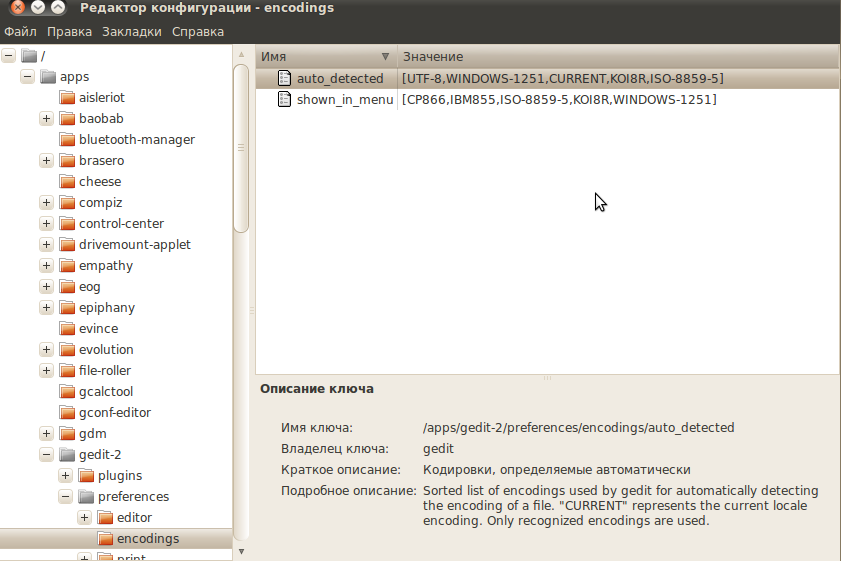 В появившемся окне редактирования переместите нужную вам кодировку вверх, так, чтобы она находилась сразу после UTF-8. Нажмите OK и закройте редактор.
В появившемся окне редактирования переместите нужную вам кодировку вверх, так, чтобы она находилась сразу после UTF-8. Нажмите OK и закройте редактор. 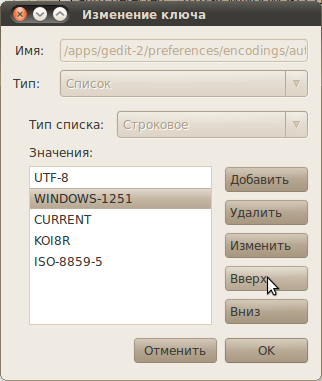
Вариант 3. Выполните в терминале команду:
Для Ubuntu 16.04:
Для Ubuntu Mate 16.04:
Данный способ является самым быстрым.
Теперь, если вы откроете файл с кодировкой WINDOWS-1251 — он будет правильно отображаться в Gedit.
Смена кодировки открытого файла
С помощью системы плагинов можно добавить возможность выбора кодировки уже открытого файла.
/.local/share/gedit/plugins (если такой папки нет, то её нужно создать)
После этого в главном меню Файл появляется пункт «Encoding», который позволяет менять кодировку в уже открытом документе.
Источник
Локализация Ubuntu Server 18.04 LTS
Локаль (locale или локализация) в Linux определяет, какой язык и какой набор символов (кодировку), пользователь видит в терминале. Посмотрим, как проверить текущие настройки языка и кодировки, как получить список всех доступных локалей, как сменить язык и кодировку для текущей сессии или установить их постоянно.
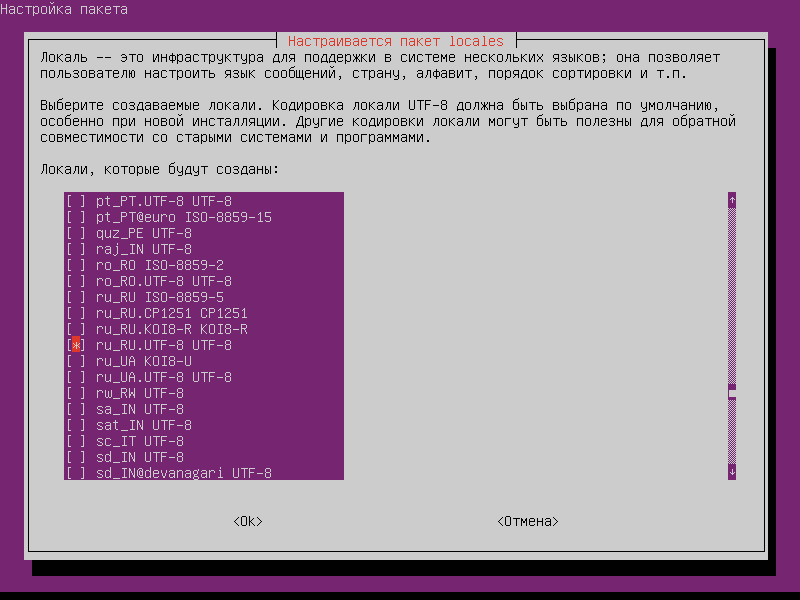
Для тех, кому лень читать всю статью до конца — чаще всего для локализации консоли достаточно повторно сконфигурировать пакет locales :
Сначала будут созданы нужные локали (их выбрать на первом экране), потом установлена локаль по умолчанию (ее выбрать на втором экране).
Текущие настройки языка
Посмотрим информацию о текущем языковом окружении:
Список доступных локалей
Теперь посмотрим список всех установленных языков и кодировок:
Есть только системная локаль C.UTF-8 , которая присутствует всегда. А нам надо добавить еще две локали — en_US.UTF-8 и ru_RU.UTF-8 .
Добавить новую локаль
Смотрим список всех поддерживаемых (доступных для установки) локалей:
Устанавливаем нужные локали — en_US.UTF-8 и ru_RU.UTF-8 :
Второй способ установить локали — расскомментровать нужные строки в файле /etc/locale.gen
И просто выполнить команду locale-gen без указания локалей:
Подробная информация о локалях
Более подробную информацию об установленных в системе локалях можно посмотреть так:
Часть локалей размещена в архиве /usr/lib/locale/locale-archive , а часть — в директориях внутри /usr/lib/locale/ .
Локаль по-умолчанию
Хорошо, нужные локали у нас теперь есть, осталось только задать локаль по умолчанию:
Эта команда запишет в файл /etc/default/locale строку:
После этого надо будет перезайти в систему. И проверяем информацию о языковом окружении:
Теперь все правильно, так что запишем эту информацию в файл /etc/default/locale :
Быстрая локализация
До сих пор мы все делали ручками, но если лень — можно просто повторно сконфигурировать пакет locales . Сначала будут созданы нужные локали (их нужно выбрать на первом экране), потом установлена локаль по умолчанию (ее нужно выбрать на втором экране).
Удалить лишние локали
После установки (генерации) локали, она помещается в архив /usr/lib/locale/locale-archive . Файл архива — это файл, отображаемый в память, который содержит все локали системы; он используется всеми локализованными программами. Посмотреть список локалей в архиве можно с помощью команды:
Удалить заданную локаль из файла архива:
Обратите внимание на название локали — ru_UA.utf8 , а не ru_UA.UTF-8 . Если неправильно указать локаль — она не будет удалена из архива:
В случае, если утилита locale-gen была вызвана с опцией —no-archive , надо удалить соответствующую директорию в /usr/lib/locale :
Переводы для системных программ
Локализация для основных системных программ, чтобы получать сообщения на русском языке:
Локализация для текущей сессии
Достаточно временно установить переменную окружения LANG в текущей сессии терминала:
Или даже так — передать переменную LANG конкретной программе:
Файлы конфигурации шрифта и клавиатуры
Настройки можно найти в файлах конфигурации /etc/default/console-setup и /etc/default/keyboard :
Это системные настройки, пользователь может создать свои в файлах
Настройка шрифта и клавиатуры
Чтобы сформировать файлы конфигурации /etc/default/console-setup и /etc/default/keyboard можно использовать команды:

После того, как файлы конфигурации будут сформированы, нужно выполнить команду setupcon без аргументов или перезагрузить систему.
Источник
HowTo: Check and Change File Encoding In Linux
The Linux administrators that work with web hosting know how is it important to keep correct character encoding of the html documents.
From the following article you’ll learn how to check a file’s encoding from the command-line in Linux.
You will also find the best solution to convert text files between different charsets.
I’ll also show the most common examples of how to convert a file’s encoding between CP1251 (Windows-1251, Cyrillic), UTF-8 , ISO-8859-1 and ASCII charsets.
Cool Tip: Want see your native language in the Linux terminal? Simply change locale! Read more →
Check a File’s Encoding
Use the following command to check what encoding is used in a file:
| Option | Description |
|---|---|
| -b , —brief | Don’t print filename (brief mode) |
| -i , —mime | Print filetype and encoding |
Check the encoding of the file in.txt :
Change a File’s Encoding
Use the following command to change the encoding of a file:
| Option | Description |
|---|---|
| -f , —from-code | Convert a file’s encoding from charset |
| -t , —to-code | Convert a file’s encoding to charset |
| -o , —output | Specify output file (instead of stdout) |
Change a file’s encoding from CP1251 (Windows-1251, Cyrillic) charset to UTF-8 :
Change a file’s encoding from ISO-8859-1 charset to and save it to out.txt :
Change a file’s encoding from ASCII to UTF-8 :
Change a file’s encoding from UTF-8 charset to ASCII :
Illegal input sequence at position: As UTF-8 can contain characters that can’t be encoded with ASCII, the iconv will generate the error message “illegal input sequence at position” unless you tell it to strip all non-ASCII characters using the -c option.
| Option | Description |
|---|---|
| -c | Omit invalid characters from the output |
You can lose characters: Note that if you use the iconv with the -c option, nonconvertible characters will be lost.
This concerns in particular Windows machines with Cyrillic.
You have copied some file from Windows to Linux, but when you open it in Linux, you see “Êàêèå-òî êðàêîçÿáðû” – WTF!?
Don’t panic – such strings can be easily converted from CP1251 (Windows-1251, Cyrillic) charset to UTF-8 with:
List All Charsets
List all the known charsets in your Linux system:
| Option | Description |
|---|---|
| -l , —list | List known charsets |
8 Replies to “HowTo: Check and Change File Encoding In Linux”
Thank you very much. Your reciept helped a lot!
I am running Linux Mint 18.1 with Cinnamon 3.2. I had some Czech characters in file names (e.g: Pešek.m4a). The š appeared as a ? and the filename included a warning about invalid encoding. I used convmv to convert the filenames (from iso-8859-1) to utf-8, but the š now appears as a different character (a square with 009A in it. I tried the file command you recommended, and got the answer that the charset was binary. How do I solve this? I would like to have the filenames include the correct utf-8 characters.
Thanks for your help–
Вообще-то есть 2 утилиты для определения кодировки. Первая этo file. Она хорошо определяет тип файла и юникодовские кодировки… А вот с ASCII кодировками глючит. Например все они выдаются как буд-то они iso-8859-1. Но это не так. Тут надо воспользоваться другой утилитой enca. Она в отличие от file очень хорошо работает с ASCII кодировками. Я не знаю такой утилиты, чтобы она одновременно хорошо работала и с ASCII и с юникодом… Но можно совместить их, написав свою. Это да. Кстати еnca может и перекодировать. Но я вам этого не советую. Потому что лучше всего это iconv. Он отлично работает со всеми типами кодировок и даже намного больше, с различными вариациями, включая BCD кодировки типа EBCDIC(это кодировки 70-80 годов, ещё до ДОСа…) Хотя тех систем давно нет, а файлов полно… Я не знаю ничего лучше для перекодировки чем iconv. Я думаю всё таки что file не определяет ASCII кодировки потому что не зарегистрированы соответствующие mime-types для этих кодировок… Это плохо. Потому что лучшие кодировки это ASCII.
Для этого есть много причин. И я не знаю ни одной разумной почему надо пользоваться юникодовскими кроме фразы “США так решило…” И навязывают всем их, особенно эту utf-8. Это худшее для кодирования текста что когда либо было! А главная причина чтобы не пользоваться utf-8, а пользоваться ASCII это то, что пользоваться чем-то иным никогда не имеет смысла. Даже в вебе. Хотите значки? Используйте символьные шрифты, их полно. Не вижу проблем… Почему я должен делать для корейцев, арабов или китайцев? Не хочу. Мне всегда хватало русского, в крайнем случае английского. Зачем мне ихние поганые языки и кодировки? Теперь про ASCII. KOI8-R это вычурная кодировка. Там русские буквы идут не по порядку. Нормальных только 2: это CP1251 и DOS866. В зависимости от того для чего. Если для графики, то безусловно CP1251. А если для полноценной псевдографики, то лучше DOS866 не придумали. Они не идеальны, но почти… Плохость utf-8 для русских текстов ещё и в том, что там каждая буква занимает 2 байта. Там ещё такая фишка как во всех юникодах это indian… Это то, в каком порядке идут байты, вначале младший а потом старший(как в памяти по адресам, или буквы в словах при написании) или наоборот, как разряды в числе, вначале старшие а потом младшие. А если символ 3-х, 4-х и боле байтов(до 16-ти в utf-8) то там кол-во заморочек растёт в геометрической прогрессии! Он ещё и тормозит, ибо каждый раз надо вычислять длину символа по довольно сложному алгоритму! А ведь нам ничего этого не надо! Причём заметьте, ихние англицкие буквы идут по порядку, ничего не пропущено и все помещаются в 1-м байте… Т.е. это искусственно придуманые штуки не для избранных америкосов. Их это вообще не волнует. Они разом обошли все проблемы записав свой алфавит в начало таблицы! Но кто им дал такое право? А все остальные загнали куда подальше… Особенно китайцев! Но если использовать CP1251, то она работает очень быстро, без тормозов и заморочек! Так же как и английские буквы…
а вот дальше бардак. Правда сейчас нам приходится пользоваться этим utf-8, Нет систем в которых бы системная кодировка была бы ASCII. Уже перестали делать. И все файлы системные именно в uft-8. А если ты хочешь ASCII, то тебе придётся всё время перекодировать. Раньше так не надо было делать. Надеюсь наши всё же сделают свою систему без ихних штатовких костылей…
Уважаемый Анатолий, огромнейшее Вам спасибо за упоминание enca. очень помогла она мне сегодня. Хотя пост Ваш рассистский и странный, но, видимо, сильно наболело.
Источник



