- Фундаментальные основы Linux. Часть IV. Программные каналы и команды
- Глава 17. Фильтры
- Фильтр cat
- Фильтр tee
- Фильтр grep
- Фильтр cut
- Фильтр tr
- Фильтр wc
- Фильтр sort
- Фильтр uniq
- Фильтр comm
- Фильтр od
- Фильтр sed
- Примеры конвейеров
- Практическое задание: фильтры
- Корректная процедура выполнения практического задания: фильтры
- ИТ База знаний
- Полезно
- Навигация
- Серверные решения
- Телефония
- Корпоративные сети
- Руководство по команде grep в Linux
- Про Linux за 5 минут | Что это или как финский студент перевернул мир?
- Для чего мы пользуемся grep-ом?
- Поиск строк
- Поиск по нескольким параметрам
- Разница между grep, egrep fgrep, pgrep, zgrep
- Разница между find и grep
- Рекурсивный поиск
- Найти пробелы и табуляцию
- Использование регулярных выражений
- Pipe, Grep and Sort Command in Linux/Unix with Examples
- What is a Pipe in Linux?
- ‘pg’ and ‘more’ commands
- The ‘grep’ command
- The ‘sort’ command
- What is a Filter?
Фундаментальные основы Linux. Часть IV. Программные каналы и команды
Глава 17. Фильтры
Команды, которые были реализованы для использования совместно с программными каналами , называются фильтрами . Эти фильтры реализуются в виде простейших программ, которые крайне эффективно выполняют одну определенную задачу. Исходя из всего вышесказанного, они могут использоваться в качестве строительных блоков при создании сложных конструкций.
В данной главе представлена информация о наиболее часто используемых фильтрах . В результате комбинирования простых команд и фильтров с использованием программных каналов могут быть созданы элегантные решения.
Фильтр cat
Фильтр tee
Фильтр grep
Фильтр cut
Фильтр tr
Фильтр wc
Фильтр sort
Фильтр uniq
Фильтр comm
Фильтр od
Фильтр sed
Примеры конвейеров
Конвейер who | wc
Конвейер who | cut | sort
Конвейер grep | cut
Практическое задание: фильтры
1. Сохраните отсортированный список пользователей командной оболочки bash в файле bashusers.txt.
2. Сохраните отсортированный список пользователей, осуществивших вход в систему, в файле onlineusers.txt.
3. Создайте список всех имен файлов из директории /etc , в которых содержится строка conf .
4. Создайте список всех имен файлов из директории /etc , в которых содержится строка conf вне зависимости от регистра символов.
5. Рассмотрите вывод утилиты /sbin/ifconfg . Создайте команду, с помощью которой будут выводиться исключительно IP-адреса и маски подсетей.
6. Создайте команду, которая позволит удалить все не относящиеся к буквенным символы из потока данных.
7. Создайте команду, которая будет принимать файл и выводить каждое слово из него в отдельной строке.
8. Разработайте систему проверки орфографии с интерфейсом командной строки. (Словарь должен находиться в директории /usr/share/dict/ .)
Корректная процедура выполнения практического задания: фильтры
1. Сохраните отсортированный список пользователей командной оболочки bash в файле bashusers.txt.
2. Сохраните отсортированный список пользователей, осуществивших вход в систему, в файле onlineusers.txt.
3. Создайте список всех имен файлов из директории /etc , в которых содержится строка conf .
4. Создайте список всех имен файлов из директории /etc , в которых содержится строка conf вне зависимости от регистра символов.
5. Рассмотрите вывод утилиты /sbin/ifconfg . Создайте команду, с помощью которой будут выводиться исключительно IP-адреса и маски подсетей.
6. Создайте команду, которая позволит удалить все не относящиеся к буквенным символы из потока данных.
7. Создайте команду, которая будет принимать файл и выводить каждое слово из него в отдельной строке.
8. Разработайте систему проверки орфографии с интерфейсом командной строки. (Словарь должен находиться в директории /usr/share/dict/ .)
Также вы можете добавить решение из вопроса номер 6 для удаления не относящихся к буквенным символов и фильтр tr -s ‘ ‘ для удаления лишних символов пробелов.
Источник
ИТ База знаний
Курс по Asterisk
Полезно
— Узнать IP — адрес компьютера в интернете
— Онлайн генератор устойчивых паролей
— Онлайн калькулятор подсетей
— Калькулятор инсталляции IP — АТС Asterisk
— Руководство администратора FreePBX на русском языке
— Руководство администратора Cisco UCM/CME на русском языке
— Руководство администратора по Linux/Unix
Навигация
Серверные решения
Телефония
FreePBX и Asterisk
Настройка программных телефонов
Корпоративные сети
Протоколы и стандарты
Руководство по команде grep в Linux
Читать между строк
10 минут чтения
То, что система Linux предоставляет пользователю большое многообразие разного функционала уже не секрет. На одном из прошлых материалов мы рассмотрели, как и где можно использовать команду find. В этой же статье мы на примерах разберём команду grep, мощный инструмент системных администраторов.
Онлайн курс по Linux
Мы собрали концентрат самых востребованных знаний, которые позволят тебе начать карьеру администратора Linux, расширить текущие знания и сделать уверенный шаг к DevOps

Про Linux за 5 минут | Что это или как финский студент перевернул мир?

Для чего мы пользуемся grep-ом?
Grep это утилита командной строки Linux, который даёт пользователям возможность вести поиск строки. С его помощью можно даже искать конкретные слова в файле. Также можно передать вывод любой команды в grep, что сильно упрощает работу во время поиска и траблшутинга.
Возьмём команду ls. Сама по себе она выводит список всех файлов и папок.
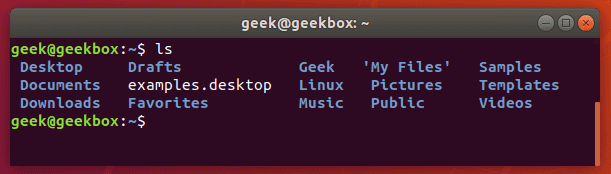
Но если нужно найти конкретную папку или один файл среди сотни других, то мы можем передать вывод команды ls в grep через вертикальную черту (|), а уже grep-у параметром передать нужное слово.
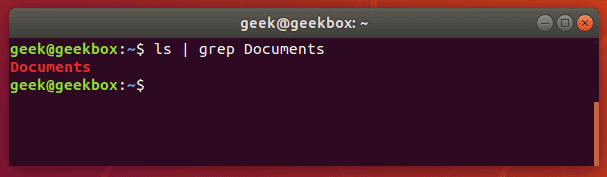
Если команда grep ничего не вернула, значит искомого файла/папки не существует в данной директории.
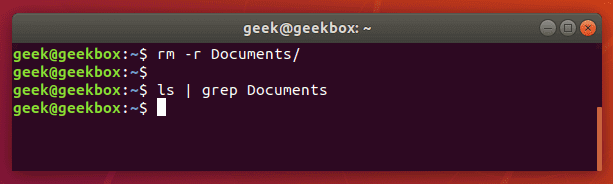
Поиск строк
Если же нужно найти не одно слово, а словосочетание или целое предложение, то параметр команды grep должно быть выделено кавычками. Grep поддерживает как одинарные, так и двойные кавычки.
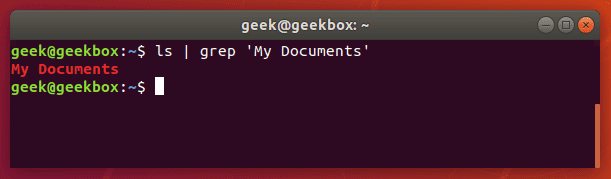
Несмотря на то, что команда grep чаще используется как своего рода фильтр для других команд, но её также можно использовать отдельно как на примере ниже.
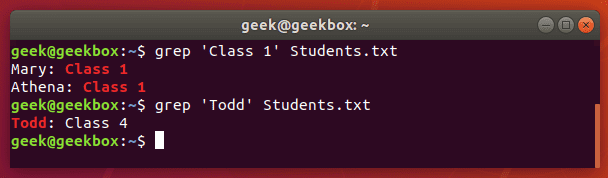
В этом примере мы вели поиск указанных в кавычках слов в файле Students.txt и команда grep успешно справилась со своей задачей.
Поиск по нескольким параметрам
Команде grep можно передавать не один параметр, а несколько. Для этого перед каждым аргументом пишется ключ e. Эту команду система понимает, как «или-или» и выводит все вхождения указанных слов. Заметьте, что кавычками выделена только строка, которая содержит пробел.

Разница между grep, egrep fgrep, pgrep, zgrep
Исторически разные версии Linux-а включали разновидности команды grep. Хотя в современных версия систем базовая команда grep поддерживает все возможности, которыми обладают egrep fgrep, pgrep, zgrep, но все же их тоже стоит рассмотреть.
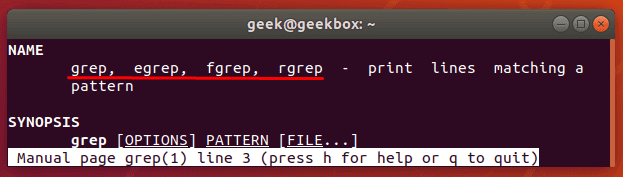
Как видно из вывода man grep (мануал по команде grep), все эти версии всего лишь разные названия основной команды. Например, egrep это тоже самое, что и grep E (помните, командная строка Linux регистрозависимая и команды grep e и grep E интерпретируются по разному). Этой команде в качестве шаблона передается расширенное регулярное выражение. Существует очень много разных ситуаций, где можно воспользоваться этой командой. Например, две команды ниже эквивалентны и выводят все строки, в которых есть две подряд идущих буквы «p».
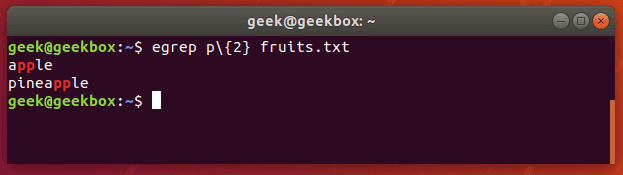
Fgrep это команда grep F, которая обрабатывает переданный шаблон как список фиксированных данных строкового типа. Эта команда полезна, когда в шаблоне используются зарезервированные для регулярных выражений символы, которые при обычно grep пришлось бы экранировать.
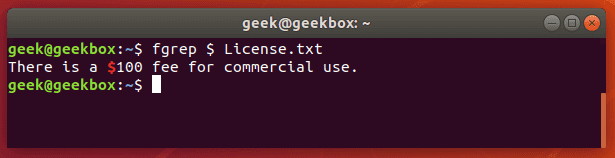
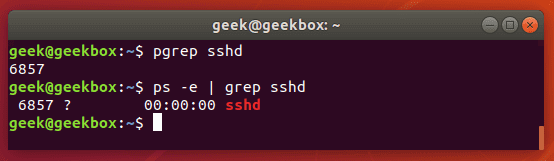
Команда pgrep используется для поиска конкретного процесса, запущенного в системе и возвращает идентификатор указанного процесса (PID). Команда ниже выводит PID процесса sshd. Почти такого же результата можно достичь если запустить команду ps e | grep sshd.
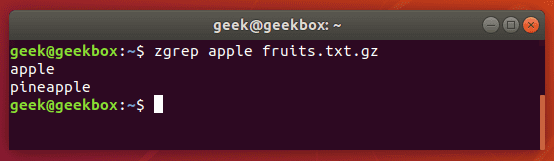
Команда zgrep используется для поиска указанного шаблона в заархивированных файлах, что очень удобно так как не приходится сначала разархивировать файл, а потом уже вести поиск.
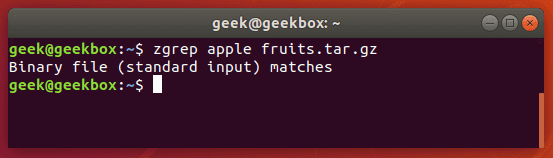
Zgrep также работает с tar архивами, но ограничивается лишь выводом информации о том, нашла ли она соответствие или нет. Это замечание мы сделали потому, что чаще всего gzip-ом архивируются tar файлы.
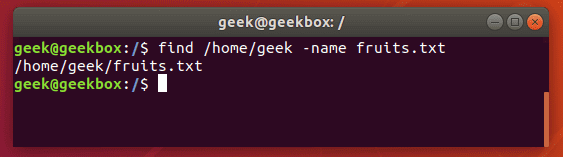
Разница между find и grep
Те, кто только начинает пользоваться командной строкой Linux должны понимать, что find и grep это две разные команды, которые имеют совсем разные функции, даже если оба используются для «поиска» чего-либо.
При поиске файлов grep-ом удобно пользоваться для фильтрации вывода команды find, как и было показано в начале материала. Но если нужно найти какой-то файл в системе по его названию или части названия (при этом используется маска *), то лучше всего обратиться к find. Она выведёт точно расположение искомого файла.
Рекурсивный поиск
Чтобы вести поиск по указанному шаблону среди всех файлов во всех папках и подпапках, команду grep нужно запустить с ключом r. Команда выведет все файлы, где найдено совпадение с указанным шаблоном, а также путь к ним. По умолчанию поиск ведется по текущей директории и поддиректориях.

Найти пробелы и табуляцию
Как и было отмечено ранее, если в шаблоне поиска содержится пробел, то мы должны выделять строку кавычками. Это мы можем использовать для поиска пробелов и знаков табуляции в файле. О том как вставить табуляцию чуть позже.

Есть несколько путей вставки табуляции, но некоторые дистрибутивы могут не поддерживать их. Как известно, в командной строке Linux клавиша TAB сама по себе дополняет введённую команду. Но если комбинировать клавиши ctrl+v, а затем нажать TAB, то система воспримет это как знак табуляции. $ grep » » sample.txt
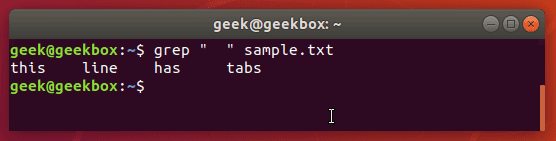
Эта фишка очень помогает при поиске среди конфигурационных файлов системы, так как значения от параметров отделяются табуляцией.
Использование регулярных выражений
Регулярные выражения сильно расширяют возможности команды grep, что позволяет нам вести более гибкий поиск. Далее мы рассмотрим несколько вариантов использования регулярных выражений.
[квадратные скобки] они используются чтобы проверить на соответствие одному из указанных символов.
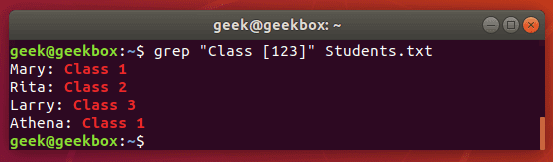
[-] знак дефиса означает диапазон значений. Это могут быть как буквы, так и цифры.
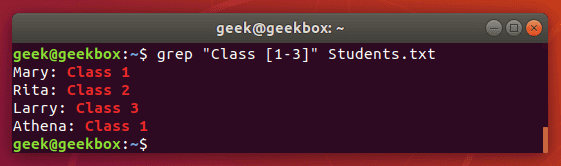
Вторая команда вывела то же, что и первая, но здесь мы обошлись знаком диапазона.
^ каретка используется для поиска строк, которые начинаются с указанного шаблона. Команда ниже выведет все строки, которые начинаются с буквы «А».
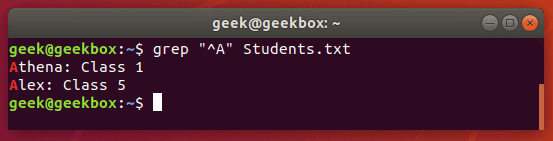
[^] но между квадратными скобками смысл каретки меняется. Здесь он исключает из поиска следующие за ней символы или диапазон символов.
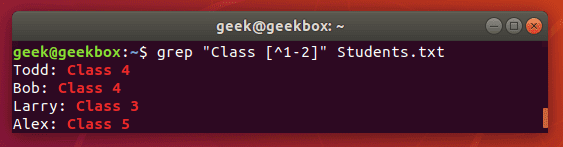
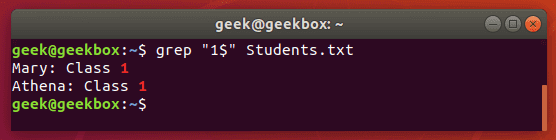
$ знак доллара означает конец строки. Команда выведет только те строки, в конце которых встречает указанный шаблон.
.точка обозначает один любой символ. Чтобы указать несколько любых символов, можно написать символ точку нужное количество раз.
Источник
Pipe, Grep and Sort Command in Linux/Unix with Examples
Updated October 7, 2021
In this tutorial, we will learn-
What is a Pipe in Linux?
The Pipe is a command in Linux that lets you use two or more commands such that output of one command serves as input to the next. In short, the output of each process directly as input to the next one like a pipeline. The symbol ‘|’ denotes a pipe.
Pipes help you mash-up two or more commands at the same time and run them consecutively. You can use powerful commands which can perform complex tasks in a jiffy.
Let us understand this with an example.
When you use ‘cat’ command to view a file which spans multiple pages, the prompt quickly jumps to the last page of the file, and you do not see the content in the middle.
To avoid this, you can pipe the output of the ‘cat’ command to ‘less’ which will show you only one scroll length of content at a time.
An illustration would make it clear.

Click here if the video is not accessible
‘pg’ and ‘more’ commands
Instead of ‘less’, you can also use.
And, you can view the file in digestible bits and scroll down by simply hitting the enter key.

The ‘grep’ command
Suppose you want to search a particular information the postal code from a text file.
You may manually skim the content yourself to trace the information. A better option is to use the grep command. It will scan the document for the desired information and present the result in a format you want.
Syntax:
Let’s see it in action –

Here, grep command has searched the file ‘sample’, for the string ‘Apple’ and ‘Eat’.
Following options can be used with this command.
| Option | Function |
|---|---|
| -v | Shows all the lines that do not match the searched string |
| -c | Displays only the count of matching lines |
| -n | Shows the matching line and its number |
| -i | Match both (upper and lower) case |
| -l | Shows just the name of the file with the string |
Let us try the first option ‘-i’ on the same file use above –
Using the ‘i’ option grep has filtered the string ‘a’ (case-insensitive) from the all the lines.

The ‘sort’ command
This command helps in sorting out the contents of a file alphabetically.
The syntax for this command is:
Consider the contents of a file.

Using the sort command

There are extensions to this command as well, and they are listed below.
| Option | Function |
|---|---|
| -r | Reverses sorting |
| -n | Sorts numerically |
| -f | Case insensitive sorting |
The example below shows reverse sorting of the contents in file ‘abc’.
.png)
What is a Filter?
Linux has a lot of filter commands like awk, grep, sed, spell, and wc. A filter takes input from one command, does some processing, and gives output.
When you pipe two commands, the “filtered ” output of the first command is given to the next.
.png)
Let’s understand this with the help of an example.
We have the following file ‘sample’

We want to highlight only the lines that do not contain the character ‘a’, but the result should be in reverse order.
For this, the following syntax can be used.
Источник



