- How to Count lines in a file in UNIX/Linux
- Using “wc -l”
- Using awk
- Using sed
- Using grep
- Some more commands
- How to count lines of code including sub-directories [duplicate]
- 11 Answers 11
- How to count lines in a document?
- 27 Answers 27
- wc -l does not count lines.
- POSIX-compliant solution
- Linux wc Command Word and Line Count Tutorial With Examples
- Syntax
- Count All Bytes, Words and Lines
- Count Chars
- Count Words
- Count Lines
- Redirect To wc File
- Redirect To wc Multiple Files
- Count Files And Directories
- Usage With Grep
- Usage With Find
- Grep Count Lines If a String / Word Matches on Linux or Unix System
- Grep Count Lines If a String / Word Matches
- Summing up
How to Count lines in a file in UNIX/Linux
Question: I have a file on my Linux system having a lot of lines. How do I count the total number of lines in the file?
Using “wc -l”
There are several ways to count lines in a file. But one of the easiest and widely used way is to use “wc -l”. The wc utility displays the number of lines, words, and bytes contained in each input file, or standard input (if no file is specified) to the standard output.
So consider the file shown below:
1. The “wc -l” command when run on this file, outputs the line count along with the filename.
2. To omit the filename from the result, use:
3. You can always provide the command output to the wc command using pipe. For example:
You can have any command here instead of cat. Output from any command can be piped to wc command to count the lines in the output.
Using awk
If you must want to use awk to find the line count, use the below awk command:
Using sed
Use the below sed command syntax to find line count using GNU sed:
Using grep
Our good old friend «grep» can also be used to count the number of lines in a file. These examples are just to let you know that there are multiple ways to count the lines without using «wc -l». But if asked I will always use «wc -l» instead of these options as it is way too easy to remember.
With GNU grep, you can use the below grep syntax:
Here is another version of grep command to find line count.
Some more commands
Along with the above commands, its good to know some rarely used commands to find the line count in a file.
1. Use the nl command (line numbering filter) to get each line numbered. The syntax for the command is:
Not so direct way to get line count. But you can use awk or sed to get the count from last line. For example:
2. You can also use vi and vim with the command «:set number» to set the number on each line as shown below. If the file is very big, you can use «Shift+G» to go to the last line and get the line count.
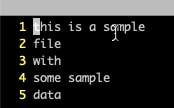
3. Use the cat command with -n switch to get each line numbered. Again, here you can get the line count from the last line.
4. You can also use perl one lines to find line count:
Источник
How to count lines of code including sub-directories [duplicate]
Suppose I want to count the lines of code in a project. If all of the files are in the same directory I can execute:
However, if there are sub-directories, this doesn’t work. For this to work cat would have to have a recursive mode. I suspect this might be a job for xargs, but I wonder if there is a more elegant solution?
11 Answers 11
First you do not need to use cat to count lines. This is an antipattern called Useless Use of Cat (UUoC). To count lines in files in the current directory, use wc :
Then the find command recurses the sub-directories:
. is the name of the top directory to start searching from
-name «*.c» is the pattern of the file you’re interested in
-exec gives a command to be executed
<> is the result of the find command to be passed to the command (here wc-l )
\; indicates the end of the command
This command produces a list of all files found with their line count, if you want to have the sum for all the files found, you can use find to list the files (with the -print option) and than use xargs to pass this list as argument to wc-l.
EDIT to address Robert Gamble comment (thanks): if you have spaces or newlines (!) in file names, then you have to use -print0 option instead of -print and xargs -null so that the list of file names are exchanged with null-terminated strings.
The Unix philosophy is to have tools that do one thing only, and do it well.

If you want a code-golfing answer:
The problem with just using wc -l on its own is it cant descend well, and the oneliners using
Won’t give you a total line count because it runs wc once for every file, ( loL! ) and
Will get confused as soon as find hits the
200k 1 , 2 character argument limit for parameters and instead calls wc multiple times, each time only giving you a partial summary.
Additionally, the above grep trick will not add more than 1 line to the output when it encounters a binary file, which could be circumstantially beneficial.
For the cost of 1 extra command character, you can ignore binary files completely:
If you want to run line counts on binary files too
Footnote on limits:
The docs are a bit vague as to whether its a string size limit or a number of tokens limit.
This implies its going to chunk very very easily.
Источник
How to count lines in a document?
I have lines like these, and I want to know how many lines I actually have.
Is there a way to count them all using linux commands?

27 Answers 27
This will output the number of lines in :
Or, to omit the from the result use wc -l :
You can also pipe data to wc as well:
To count all lines use:
To filter and count only lines with pattern use:
Or use -v to invert match:
See the grep man page to take a look at the -e,-i and -x args.

there are many ways. using wc is one.
sed -n ‘$=’ file (GNU sed)
The tool wc is the «word counter» in UNIX and UNIX-like operating systems, but you can also use it to count lines in a file by adding the -l option.
wc -l foo will count the number of lines in foo . You can also pipe output from a program like this: ls -l | wc -l , which will tell you how many files are in the current directory (plus one).
If you want to check the total line of all the files in a directory ,you can use find and wc:


wc -l does not count lines.
Yes, this answer may be a bit late to the party, but I haven’t found anyone document a more robust solution in the answers yet.
Contrary to popular belief, POSIX does not require files to end with a newline character at all. Yes, the definition of a POSIX 3.206 Line is as follows:
A sequence of zero or more non- characters plus a terminating character.
However, what many people are not aware of is that POSIX also defines POSIX 3.195 Incomplete Line as:
A sequence of one or more non- characters at the end of the file.
Hence, files without a trailing LF are perfectly POSIX-compliant.
If you choose not to support both EOF types, your program is not POSIX-compliant.
As an example, let’s have look at the following file.
No matter the EOF, I’m sure you would agree that there are two lines. You figured that out by looking at how many lines have been started, not by looking at how many lines have been terminated. In other words, as per POSIX, these two files both have the same amount of lines:
The man page is relatively clear about wc counting newlines, with a newline just being a 0x0a character:
Hence, wc doesn’t even attempt to count what you might call a «line». Using wc to count lines can very well lead to miscounts, depending on the EOF of your input file.
POSIX-compliant solution
You can use grep to count lines just as in the example above. This solution is both more robust and precise, and it supports all the different flavors of what a line in your file could be:
Источник
Linux wc Command Word and Line Count Tutorial With Examples
Linux provides a lot of tools for text-related operations. wc is one of them. This tool is a little tool less than 10 options. In this tutorial, we will look at how to count bytes? How to count words? How to count Lines? and How to use wc with other Linux commands like find and grep?
Syntax
Syntax of wc is like below.
Fast help about the wc can get with the following command.
 Help
Help
Count All Bytes, Words and Lines
As we stated before wc is a little tool. If we want to get all results wc can provide we should use it without any option like below. In the example, we provide a file named case_sensitive.c which seems to be a C source file and get the number of lines which is 9, number of words which is 11 and number of bytes or chars which is 78
 Count All Bytes, Words and Lines
Count All Bytes, Words and Lines
Count Chars
If we only want to get the number of chars we can use m options like below.
 Count Chars
Count Chars
Count Words
If we only want to count words the -w option can be used.
 Count Words
Count Words
Count Lines
If we only want to count lines -l option can be used.
 Count Lines
Count Lines
Redirect To wc File
wc is generally used with other tools or external input. External input is a very useful feature of the wc. By using bash capabilities external text can be redirected to the wc as input like below. In this example we simply print file case_sensitive.c to the standard output and this standard output is redirected with pipe operator to the wc as standard input which is processes like a file by wc.
Redirect To wc Multiple Files
Redirect is a simple mechanism. Redirecting multiple files is the same as a single file we just print files according to their names or extensions. In the example, we will redirect all files with .c extension to the wc command.
 Redirect To wc Multiple Files
Redirect To wc Multiple Files
Count Files And Directories
wc can be used to count files and directories by using ls command output. In the example, we use ls command to list all files and directories line by line and redirect to the wc.
 Count Files And Directories
Count Files And Directories
Usage With Grep
Another useful usage wc is using it with grep. By using grep the content of the resource files is filtered and then counted with wc. In this example, we want to count the lines where those provide int string. We use a regular expression to filter. We only provide .c extension files.
 Usage With Grep
Usage With Grep
Usage With Find
Another useful usage is using with find command. find search according to specified parameters. wc can be used on the search results to count lines or others. In the example, we will search for files with .c extension and run wc command against them to find their line counts one by one.
 Usage With Find
Usage With Find
Источник
Grep Count Lines If a String / Word Matches on Linux or Unix System
Grep Count Lines If a String / Word Matches
The syntax is as follows on Linux or Unix-like systems:
grep -c ‘word-to-search’ fileNameHere
For example, search a word named ‘vivek’ in /etc/passwd and count line if a word matches:
$ grep -c vivek /etc/passwd
OR
$ grep -w -c vivek /etc/passwd
Sample outputs indicating that word ‘vivek’ found one times:
However, with the -v or —invert-match option it will count non-matching lines, enter:
$ grep -v -c vivek /etc/passwd
Sample outputs:
- No ads and tracking
- In-depth guides for developers and sysadmins at Opensourceflare✨
- Join my Patreon to support independent content creators and start reading latest guides:
- How to set up Redis sentinel cluster on Ubuntu or Debian Linux
- How To Set Up SSH Keys With YubiKey as two-factor authentication (U2F/FIDO2)
- How to set up Mariadb Galera cluster on Ubuntu or Debian Linux
- A podman tutorial for beginners – part I (run Linux containers without Docker and in daemonless mode)
- How to protect Linux against rogue USB devices using USBGuard
Join Patreon ➔
- -c : Display only a count of selected lines per FILE
- -v : Select non-matching lines
- —invert-match : Same as above.
Using grep command to count how many times the word ‘vivek’ and ‘root’ found in /etc/passwd file on Linux or Unix.
Summing up
We can easily suppress normal grep or egrep command output bypassing the -c option. Instead, it will print a count of matching lines for each input file. I would urge you to read the grep command man page to get additional information by typing the following man command:
man grep
man egrep
grep —help
egrep —help
🐧 Get the latest tutorials on Linux, Open Source & DevOps via
Источник



