- Удалить пустые строки с файла в Unix/Linux
- -=== СПОСОБ 1 — Использование утилиты SED ===-
- -=== СПОСОБ 2 — Использование perl ===-
- -=== СПОСОБ 3 — Использование утилиты AWK ===-
- -=== СПОСОБ 4 — Использование утилиты CAT ===-
- -=== СПОСОБ 4 — Использование утилиты TR ===-
- Удаление строк из файла с использованием sed
- Sed: удалить одну или несколько строк из файла
- Синтаксис
- Примеры Sed
- 😡 Как удалить строки, соответствующие определенному шаблону в файле, используя SED
- Удалить строки, соответствующие определенному шаблону в файле, используя SED
- linux-notes.org
- -=== СПОСОБ 1 — Использование утилиты SED ===-
- -=== СПОСОБ 2 — Использование perl ===-
- -=== СПОСОБ 3 — Использование утилиты AWK ===-
- -=== СПОСОБ 4 — Использование утилиты CAT ===-
- -=== СПОСОБ 5 — Использование утилиты TR ===-
- Добавить комментарий Отменить ответ
- Команда sed Linux
- Команда sed в Linux
- 1. Как работает sed
- 2. Адреса sed
- 3. Синтаксис регулярных выражений
- 4. Команды sed
- Примеры использования sed
- Выводы
Удалить пустые строки с файла в Unix/Linux

Удалить пустые строки с файла в Unix/Linux
Иногда, у нас имеются файлы и в них много пустых строк — это не очень удобно (по крайней мере для чтения). Файлы можно отредактировать вручную, если файл имеет несколько пустых строк, но если файл имеет тысячи пустых строк, это трудно сделать вручную. Используйте один из следующих методов для удаления пустых строк из файла.
-=== СПОСОБ 1 — Использование утилиты SED ===-
Sed потоковый редактор. С помощью этой утилиты, можно легко удалить все пустые строки. Используйте одну из следующих команд sed для удаления пустых строк из файла.
main.txt — Это исходный файл, из которого нужно удалить пустые строки.
output_file.txt — Будет служить файлом без пустых строк.
-=== СПОСОБ 2 — Использование perl ===-
И так, чтобы удалить пустые строки в файлу (у меня это main.txt), используйте:
-=== СПОСОБ 3 — Использование утилиты AWK ===-
Используйте команду awk для удаления пустых строк из файла.
main.txt — Это исходный файл, из которого нужно удалить пустые строки.
output_file.txt — Будет служить файлом без пустых строк.
И так, запускаем:
-=== СПОСОБ 4 — Использование утилиты CAT ===-
Используйте команду cat для удаления пустых строк из файла.
main.txt — Это исходный файл, из которого нужно удалить пустые строки.
output_file.txt — Будет служить файлом без пустых строк.
И так, запускаем:
-=== СПОСОБ 4 — Использование утилиты TR ===-
Используйте команду cat для удаления пустых строк из файла.
main.txt — Это исходный файл, из которого нужно удалить пустые строки.
output_file.txt — Будет служить файлом без пустых строк.
Если появятся еще идеи. Я дополню данную тему!
Вот и все, статья «Удалить пустые строки с файла в Unix/Linux» завершена.
Источник
Удаление строк из файла с использованием sed
В Unix команда SED удаляет одну или несколько строк из указанного файла по желанию пользователя. Эта утилита используется для работы с командной строкой Unix, для удаления из файла выражений, которые могут быть идентифицированы с помощью определяющего разделителя (например, запятая, табуляция или пробел), по номеру строки или путем поиска строки, выражения или адреса строки в синтаксисе sed.

Sed: удалить одну или несколько строк из файла
Вот как можно удалить одну или несколько строк из файла.
Синтаксис
n = номер строки
string = ряд символов, найденный в строке
regex = регулярное выражение, соответствующее искомому шаблону
addr = адрес строки (номер или шаблон)
d = удалить (delete)
Примеры Sed
Вот несколько примеров использования приведенного выше синтаксиса.
Используйте следующий код, чтобы удалить третью строку:
Удалите строку, содержащую ряд букв «awk», используя:
Вы можете удалить последнюю строку, введя:
Или удалить все пустые строки:
Удалить строку, соответствующую регулярным выражениям (путем исключения одного из них, содержащего цифровые символы, как минимум 1 цифру, расположенные в конце строки):
Удалить интервал между строками 7 и 9:
Та же операция, что и приведенная выше, но с заменой адреса параметрами:
Вышеприведенные примеры отображают изменения только при открытии файла (stdout1 = screen).
Для постоянных изменений в старых версиях (ниже 4) используйте временный файл для GNU sed с использованием команды -i [suffix]:
Источник
😡 Как удалить строки, соответствующие определенному шаблону в файле, используя SED

В этом руководстве мы узнаем, как удалять строки, соответствующие определенному шаблону в файле, используя SED.
SED – это потоковый редактор, который выполняет базовую фильтрацию текста и преобразования входного потока (файла или ввода из конвейера).
Удалить строки, соответствующие определенному шаблону в файле, используя SED
В нашем предыдущем руководстве мы рассмотрели, как удалять сктроки, соответствующие определенным шаблонам в VIM.
Вы можете проверить этот метод, перейдя по ссылке ниже;
Теперь давайте рассмотрим различные примеры удаления строк, соответствующих определенному шаблону, в файле с помощью SED.
Для демонстрации мы будем использовать семь цветов радуги в файле.
Как и в VIM, мы будем использовать команду d для удаления определенного пространства шаблонов с помощью SED.
Для начала, если вы хотите удалить строку, содержащую ключевое слово, вы должны запустить sed, как показано ниже.
Где опция -i указывает место в файл.
Если вам нужно выполнить пробный прогон (без фактического удаления строки с ключевым словом) и вывести результат в стандартный вывод, опустите опцию -i.
Например, удалите строку, содержащую ключевое слово green, которую вы запустите;
Точно так же вы можете запустить команду sed с опцией -n и командой p, (!p).
Удалить строки, содержащие несколько ключевых слов, например, удалить строки с ключевым словом green или строки с ключевым словом violet.
Если вам нужно удалить строки, но создать резервную копию исходного файла, используйте параметр -i в формате -i.bak.
Это создаст файл .bak оригинального имени файла.
Удалить все строки, кроме тех, которые содержат определенный шаблон или ключевое слово;
Чтобы удалить строки, начинающиеся с определенного символа или шаблона, например, строки комментариев, начинающиеся с # или строки, начинающиеся с ключевого слова amos.
Удалить строки, заканчивающиеся определенным шаблоном или символом, например, удалить строки, начинающиеся с символа o или ключевого слова amos;
Чтобы объединить вышеперечисленное, вы можете удалить строки, заканчивающиеся буквой o или ключевым словом amos;
Удалить пустые строки
Удалить пустые строки или строки, содержащие один или несколько пробелов;
Удалить пустые строки или строки, которые на одной или нескольких вкладках;
Что ж, это лишь малая часть того, что мы могли бы рассказать о том, как удалять строки, соответствующие определенному шаблону в файле, используя SED.
Не стесняйтесь добавлять больше примеров и предложений в комментариях ниже.
Источник
linux-notes.org

Иногда, у нас имеются файлы и в них много пустых строк — это не очень удобно (по крайней мере для чтения). Файлы можно отредактировать вручную, если файл имеет несколько пустых строк, но если файл имеет тысячи пустых строк, это трудно сделать вручную. Используйте один из следующих методов для удаления пустых строк из файла.
-=== СПОСОБ 1 — Использование утилиты SED ===-
Sed потоковый редактор. С помощью этой утилиты, можно легко удалить все пустые строки. Используйте одну из следующих команд sed для удаления пустых строк из файла.
- main.txt — Это исходный файл, из которого нужно удалить пустые строки.
- output_file.txt — Будет служить файлом без пустых строк.
-=== СПОСОБ 2 — Использование perl ===-
И так, чтобы удалить пустые строки в файлу (у меня это main.txt), используйте:
-=== СПОСОБ 3 — Использование утилиты AWK ===-
Используйте команду awk для удаления пустых строк из файла.
- main.txt — Это исходный файл, из которого нужно удалить пустые строки.
- output_file.txt — Будет служить файлом без пустых строк.
И так, запускаем:
-=== СПОСОБ 4 — Использование утилиты CAT ===-
Используйте команду cat для удаления пустых строк из файла.
- main.txt — Это исходный файл, из которого нужно удалить пустые строки.
- output_file.txt — Будет служить файлом без пустых строк.
И так, запускаем:
-=== СПОСОБ 5 — Использование утилиты TR ===-
Используйте команду cat для удаления пустых строк из файла.
- main.txt — Это исходный файл, из которого нужно удалить пустые строки.
- output_file.txt — Будет служить файлом без пустых строк.
Если появятся еще идеи. Я дополню данную тему!
Вот и все, статья «Удалить пустые строки с файла в Unix/Linux» завершена.
Добавить комментарий Отменить ответ
Этот сайт использует Akismet для борьбы со спамом. Узнайте, как обрабатываются ваши данные комментариев.
Источник
Команда sed Linux
Команда sed — это потоковый редактор текста, работающий по принципу замены. Его можно использовать для поиска, вставки, замены и удаления фрагментов в файле. С помощью этой утилиты вы можете редактировать файлы не открывая их. Будет намного быстрее если вы напишите что и на что надо заменить, чем вы будете открывать редактор vi, искать нужную строку и вручную всё заменять.
В этой статье мы рассмотрим основы использования команды sed linux, её синтаксис, а также синтаксис регулярных выражений, который используется непосредственно для поиска и замены в файлах.
Команда sed в Linux
Сначала рассмотрим синтаксис команды:
$ sed опции -e команды файл
А вот её основные опции:
- -n, —quiet — не выводить содержимое буфера шаблона в конце каждой итерации;
- -e — команды, которые надо выполнить для редактирования;
- -f — прочитать команды редактирования из файла;
- -i — сделать резервную копию файла перед редактированием;
- -l — указать свою длину строки;
- -r — включить поддержку расширенного синтаксиса регулярных выражений;
- -s — если передано несколько файлов, рассматривать их как отдельные потоки, а не как один длинный.
Я понимаю, что сейчас всё очень сложно, но к концу статьи всё прояснится.
1. Как работает sed
Теперь нужно понять как работает команда sed. У утилиты есть два буфера, это активный буфер шаблона и дополнительный буфер. Оба изначально пусты. Программа выполняет заданные условия для каждой строки в переданном ей файле.
sed читает одну строку, удаляет из неё все завершающие символы и символы новой строки и помещает её в буфер шаблона. Затем выполняются переданные в параметрах команды, с каждой командой может быть связан адрес, это своего рода условие и команда выполняется только если подходит условие.
Когда всё команды будут выполнены и не указана опция -n, содержимое буфера шаблона выводится в стандартный поток вывода перед этим добавляется обратно символ перевода строки. если он был удален. Затем запускается новая итерация цикла для следующей строки.
Если не используются специальные команды, например, D, то после завершения одной итерации цикла содержимое буфера шаблона удаляется. Однако содержимое предыдущей строки хранится в дополнительном буфере и его можно использовать.
2. Адреса sed
Каждой команде можно передать адрес, который будет указывать на строки, для которых она будет выполнена:
- номер — позволяет указать номер строки, в которой надо выполнять команду;
- первая
шаг — команда будет выполняется для указанной в первой части сроки, а затем для всех с указанным шагом;
число
— начиная от строки номер и до строки номер которой будет кратный числу.Если для команды не был задан адрес, то она будет выполнена для всех строк. Если передан один адрес, команда будет выполнена только для строки по этому адресу. Также можно передать диапазон адресов. Тогда адреса разделяются запятой и команда будет выполнена для всех адресов диапазона.
3. Синтаксис регулярных выражений
Вы можете использовать такие же регулярные выражения, как и для Bash и популярных языков программирования. Вот основные операторы, которые поддерживают регулярные выражения sed Linux:
- * — любой символ, любое количество;
- \+ — как звездочка, только один символ или больше;
- \? — нет или один символ;
- \ — любой символ в количестве i;
- \ — любой символ в количестве от i до j;
- \ — любой символ в количестве от i и больше.
4. Команды sed
Если вы хотите пользоваться sed, вам нужно знать команды редактирования. Рассмотрим самые часто применяемые из них:
- # — комментарий, не выполняется;
- q — завершает работу сценария;
- d — удаляет буфер шаблона и запускает следующую итерацию цикла;
- p — вывести содержимое буфера шаблона;
- n — вывести содержимое буфера шаблона и прочитать в него следующую строку;
- s/что_заменять/на_что_заменять/опции — замена символов, поддерживаются регулярные выражения;
- y/символы/символы — позволяет заменить символы из первой части на соответствующие символы из второй части;
- w — записать содержимое буфера шаблона в файл;
- N — добавить перевод строки к буферу шаблона;
- D — если буфер шаблона не содержит новую строку, удалить его содержимое и начать новую итерацию цикла, иначе удалить содержимое буфера до символа перевода строки и начать новую итерацию цикла с тем, что останется;
- g — заменить содержимое буфера шаблона, содержимым дополнительного буфера;
- G — добавить новую строку к содержимому буфера шаблона, затем добавить туда же содержимое дополнительного буфера.
Утилите можно передать несколько команд, для этого их надо разделить точкой с запятой или использовать две опции -e. Теперь вы знаете всё необходимое и можно переходить к примерам.
Примеры использования sed
Теперь рассмотрим примеры sed Linux, чтобы у вас сложилась целостная картина об этой утилите. Давайте сначала выведем из файла строки с пятой по десятую. Для этого воспользуемся командой -p. Мы используем опцию -n чтобы не выводить содержимое буфера шаблона на каждой итерации, а выводим только то, что нам надо. Если команда одна, то опцию -e можно опустить и писать без неё:
sed -n ‘5,10p’ /etc/group
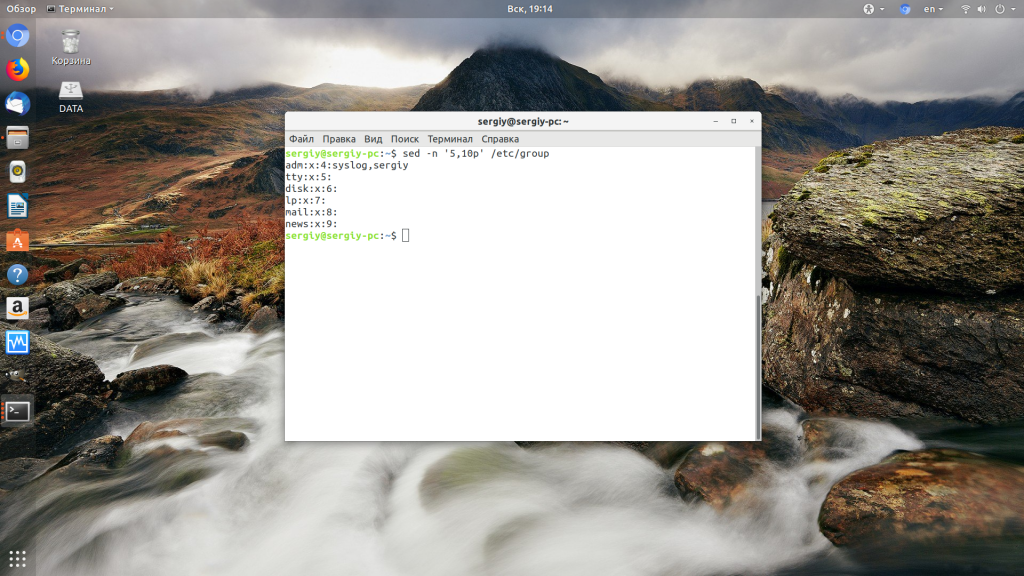
Или можно вывести весь файл, кроме строк с первой по двадцатую:
sed ‘1,20d’ /etc/group

Здесь наоборот, опцию -n не указываем, чтобы выводилось всё, а с помощью команды d очищаем ненужное. Дальше рассмотрим замену в sed. Это самая частая функция, которая применяется вместе с этой утилитой. Заменим вхождения слова root на losst в том же файле и выведем всё в стандартный вывод:
sed ‘s/root/losst/g’ /etc/group

Флаг g заменяет все вхождения, также можно использовать флаг i, чтобы сделать регулярное выражение sed не зависимым от регистра. Для команд можно задавать адреса. Например, давайте выполним замену 0 на 1000, но только в строках с первой по десятую:
sed ‘1,10 s/0/1000/g’ /etc/group

Переходим ещё ближе к регулярным выражениям, удалим все пустые строки или строки с комментариями из конфига Apache:
sed ‘/^#\|^$\| *#/d’ /etc/apache2/apache2.conf

Под это регулярное выражение (адрес) подпадают все строки, которые начинаются с #, пустые, или начинаются с пробела, а за ним идет решетка. Регулярные выражения можно использовать и при замене. Например, заменим все вхождения p в начале строки на losst_p:
sed ‘s/[$p*]/losst_p/g’ /etc/group

Если вам надо записать результат замены в обратно в файл можно использовать стандартный оператор перенаправления вывода > или утилиту tee. Например:
sed ‘/^#\|^$\| *#/d’ /etc/apache2/apache2.conf | sudo tee /etc/apache2/apache2.conf
Также можно использовать опцию -i, тогда утилита не будет выполнять изменения в переданном ей файле:
sudo sed -i ‘/^#\|^$\| *#/d’ /etc/apache2/apache2.conf

Если надо сохранить оригинальный файл, достаточно передать опции -i в параметре расширение для файла резервной копии.
Выводы
Из этой статьи вы узнали что представляет из себя команда sed Linux. Как видите, это очень гибкий инструмент, который позволяет делать с текстом очень многое. Он сложный в освоении, но с помощью него очень удобно решать многие задачи редактирования конфигурационных файлов или фильтрации вывода.
Источник



