- Кодировка windows 1251 это ansi или oem
- Кодировки: полезная информация и краткая ретроспектива
- Старый DOS
- Зачем нужны разные кодировки OEM и ANSI, все эти 866 и 1251
- Зачем нужны разные кодировки OEM и ANSI, все эти 866 и 1251
- Re: Зачем нужны разные кодировки OEM и ANSI, все эти 866 и 1251
- Re: Зачем нужны разные кодировки OEM и ANSI, все эти 866 и 1251
- Re: Зачем нужны разные кодировки OEM и ANSI, все эти 866 и 1251
- Re: Зачем нужны разные кодировки OEM и ANSI, все эти 866 и 1251
- 866 в WinME
- Re: Зачем нужны разные кодировки OEM и ANSI, все эти 866 и 1251
- WinME — Ї и ї
- Re: Зачем нужны разные кодировки OEM и ANSI, все эти 866 и 1251
- Re: Зачем нужны разные кодировки OEM и ANSI, все эти 866 и 1251
- Re: Зачем нужны разные кодировки OEM и ANSI, все эти 866 и 1251
- Re: Зачем нужны разные кодировки OEM и ANSI, все эти 866 и 1251
- Re: Зачем нужны разные кодировки OEM и ANSI, все эти 866 и 1251
- Re: Зачем нужны разные кодировки OEM и ANSI, все эти 866 и 1251
- Re: Зачем нужны разные кодировки OEM и ANSI, все эти 866 и 1251
Кодировка windows 1251 это ansi или oem
Reg.ru: домены и хостинг
Крупнейший регистратор и хостинг-провайдер в России.
Более 2 миллионов доменных имен на обслуживании.
Продвижение, почта для домена, решения для бизнеса.
Более 700 тыс. клиентов по всему миру уже сделали свой выбор.
Бесплатный Курс «Практика HTML5 и CSS3»
Освойте бесплатно пошаговый видеокурс
по основам адаптивной верстки
на HTML5 и CSS3 с полного нуля.
Фреймворк Bootstrap: быстрая адаптивная вёрстка
Пошаговый видеокурс по основам адаптивной верстки в фреймворке Bootstrap.
Научитесь верстать просто, быстро и качественно, используя мощный и практичный инструмент.
Верстайте на заказ и получайте деньги.
Что нужно знать для создания PHP-сайтов?
Ответ здесь. Только самое важное и полезное для начинающего веб-разработчика.
Узнайте, как создавать качественные сайты на PHP всего за 2 часа и 27 минут!
Создайте свой сайт за 3 часа и 30 минут.
После просмотра данного видеокурса у Вас на компьютере будет готовый к использованию сайт, который Вы сделали сами.
Вам останется лишь наполнить его нужной информацией и изменить дизайн (по желанию).
Изучите основы HTML и CSS менее чем за 4 часа.
После просмотра данного видеокурса Вы перестанете с ужасом смотреть на HTML-код и будете понимать, как он работает.
Вы сможете создать свои первые HTML-страницы и придать им нужный вид с помощью CSS.
Бесплатный курс «Сайт на WordPress»
Хотите освоить CMS WordPress?
Получите уроки по дизайну и верстке сайта на WordPress.
Научитесь работать с темами и нарезать макет.
Бесплатный видеокурс по рисованию дизайна сайта, его верстке и установке на CMS WordPress!
Хотите изучить JavaScript, но не знаете, как подступиться?
После прохождения видеокурса Вы освоите базовые моменты работы с JavaScript.
Развеются мифы о сложности работы с этим языком, и Вы будете готовы изучать JavaScript на более серьезном уровне.
*Наведите курсор мыши для приостановки прокрутки.
Кодировки: полезная информация и краткая ретроспектива
Данную статью я решил написать как небольшой обзор, касающийся вопроса кодировок.
Мы разберемся, что такое вообще кодировка и немного коснемся истории того, как они появились в принципе.
Мы поговорим о некоторых их особенностях а также рассмотрим моменты, позволяющие нам работать с кодировками более осознанно и избегать появления на сайте так называемых кракозябров, т.е. нечитаемых символов.
Что такое кодировка?
Упрощенно говоря, кодировка — это таблица сопоставлений символов, которые мы можем видеть на экране, определенным числовым кодам.
Т.е. каждый символ, который мы вводим с клавиатуры, либо видим на экране монитора, закодирован определенной последовательностью битов (нулей и единиц). 8 бит, как вы, наверное, знаете, равны 1 байту информации, но об этом чуть позже.
Внешний вид самих символов определяется файлами шрифтов, которые установлены на вашем компьютере. Поэтому процесс вывода на экран текста можно описать как постоянное сопоставление последовательностей нулей и единиц каким-то конкретным символам, входящим в состав шрифта.
Прародителем всех современных кодировок можно считать ASCII.

Эта аббревиатура расшифровывается как American Standard Code for Information Interchange (американская стандартная кодировочная таблица для печатных символов и некоторых специальных кодов).
Это однобайтовая кодировка, в которую изначально заложено всего 128 символов: буквы латинского алфавита, арабские цифры и т.д.
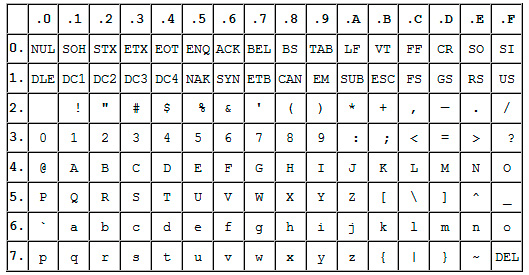
Позже она была расширена (изначально она не использовала все 8 бит), поэтому появилась возможность использовать уже не 128, а 256 (2 в 8 степени) различных символов, которые можно закодировать в одном байте информации.
Такое усовершенствование позволило добавлять в ASCII символы национальных языков, помимо уже существующей латиницы.
Вариантов расширенной кодировки ASCII существует очень много по причине того, что языков в мире тоже немало. Думаю, что многие из вас слышали о такой кодировке, как KOI8-R — это тоже расширенная кодировка ASCII, предназначенная для работы с символами русского языка.
Следующим шагом в развитии кодировок можно считать появление так называемых ANSI-кодировок.
По сути это были те же расширенные версии ASCII, однако из них были удалены различные псевдографические элементы и добавлены символы типографики, для которых ранее не хватало «свободных мест».
Примером такой ANSI-кодировки является всем известная Windows-1251. Помимо типографических символов, в эту кодировку также были включены буквы алфавитов языков, близких к русскому (украинский, белорусский, сербский, македонский и болгарский).
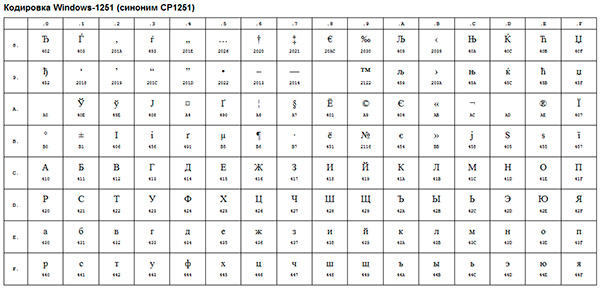
ANSI-кодировка — это собирательное название. В действительности, реальная кодировка при использовании ANSI будет определяться тем, что указано в реестре вашей операционной системы Windows. В случае с русским языком это будет Windows-1251, однако, для других языков это будет другая разновидность ANSI.
Как вы понимаете, куча кодировок и отсутствие единого стандарта до добра не довели, что и стало причиной частых встреч с так называемыми кракозябрами — нечитаемым бессмысленным набором символов.
Причина их появления проста — это попытка отобразить символы, закодированные с помощью одной кодировочной таблицы, используя другую кодировочную таблицу.
В контексте веб-разработки, мы можем столкнуться с кракозябрами, когда, к примеру, русский текст по ошибке сохраняется не в той кодировке, которая используется на сервере.
Разумеется, это не единственный случай, когда мы можем получить нечитаемый текст — вариантов тут масса, особенно, если учесть, что есть еще база данных, в которой информация также хранится в определенной кодировке, есть сопоставление соединения с базой данных и т.д.

Возникновение всех этих проблем послужило стимулом для создания чего-то нового. Это должна была быть кодировка, которая могла бы кодировать любой язык в мире (ведь с помощью однобайтовых кодировок при всем желании нельзя описать все символы, скажем, китайского языка, где их явно больше, чем 256), любые дополнительные спецсимволы и типографику.
Одним словом, нужно было создать универсальную кодировку, которая решила бы проблему кракозябров раз и навсегда.
Юникод — универсальная кодировка текста (UTF-32, UTF-16 и UTF-8)
Сам стандарт был предложен в 1991 году некоммерческой организацией «Консорциум Юникода» (Unicode Consortium, Unicode Inc.), и первым результатом его работы стало создание кодировки UTF-32.
Кстати, сама аббревиатура UTF расшифровывается как Unicode Transformation Format (Формат Преобразования Юникод).
В этой кодировке для кодирования одного символа предполагалось использовать аж 32 бита, т.е. 4 байта информации. Если сравнивать это число с однобайтовыми кодировками, то мы придем к простому выводу: для кодирования 1 символа в этой универсальной кодировке нужно в 4 раза больше битов, что «утяжеляет» файл в 4 раза.
Очевидно также, что количество символов, которое потенциально могло быть описано с помощью данной кодировки, превышает все разумные пределы и технически ограничено числом, равным 2 в 32 степени. Понятно, что это был явный перебор и расточительство с точки зрения веса файлов, поэтому данная кодировка не получила распространения.
На смену ей пришла новая разработка — UTF-16.
Как очевидно из названия, в этой кодировке один символ кодируют уже не 32 бита, а только 16 (т.е. 2 байта). Очевидно, это делает любой символ вдвое «легче», чем в UTF-32, однако и вдвое «тяжелее» любого символа, закодированного с помощью однобайтовой кодировки.
Количество символов, доступное для кодирования в UTF-16 равно, как минимум, 2 в 16 степени, т.е. 65536 символов. Вроде бы все неплохо, к тому же окончательная величина кодового пространства в UTF-16 была расширена до более, чем 1 миллиона символов.
Однако и данная кодировка до конца не удовлетворяла потребности разработчиков. Скажем, если вы пишете, используя исключительно латинские символы, то после перехода с расширенной версии кодировки ASCII к UTF-16 вес каждого файла увеличивался вдвое.
В результате, была предпринята еще одна попытка создания чего-то универсального, и этим чем-то стала всем нам известная кодировка UTF-8.
UTF-8 — это многобайтовая кодировка с переменной длинной символа. Глядя на название, можно по аналогии с UTF-32 и UTF-16 подумать, что здесь для кодирования одного символа используется 8 бит, однако это не так. Точнее, не совсем так.
Дело в том, что UTF-8 обеспечивает наилучшую совместимость со старыми системами, использовавшими 8-битные символы. Для кодирования одного символа в UTF-8 реально используется от 1 до 4 байт (гипотетически можно и до 6 байт).
В UTF-8 все латинские символы кодируются 8 битами, как и в кодировке ASCII. Иными словами, базовая часть кодировки ASCII (128 символов) перешла в UTF-8, что позволяет «тратить» на их представление всего 1 байт, сохраняя при этом универсальность кодировки, ради которой все и затевалось.
Итак, если первые 128 символов кодируются 1 байтом, то все остальные символы кодируются уже 2 байтами и более. В частности, каждый символ кириллицы кодируется именно 2 байтами.
Таким образом, мы получили универсальную кодировку, позволяющую охватить все возможные символы, которые требуется отобразить, не «утяжеляя» без необходимости файлы.
C BOM или без BOM?
Если вы работали с текстовыми редакторами (редакторами кода), например Notepad++, phpDesigner, rapid PHP и т.д., то, вероятно, обращали внимание на то, что при задании кодировки, в которой будет создана страница, можно выбрать, как правило, 3 варианта:
— ANSI
— UTF-8
— UTF-8 без BOM
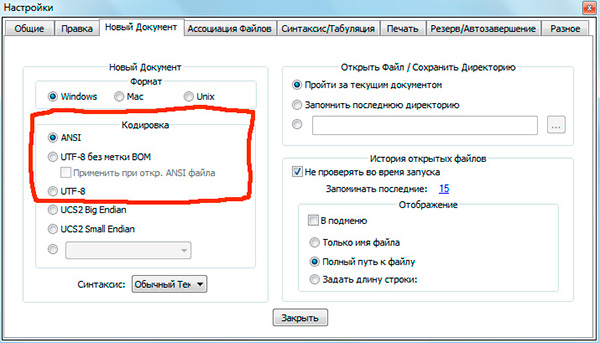
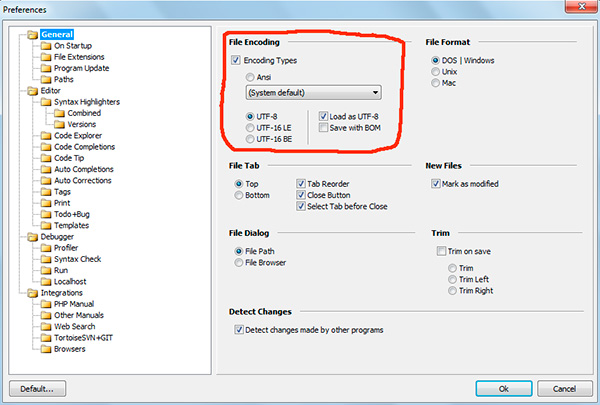
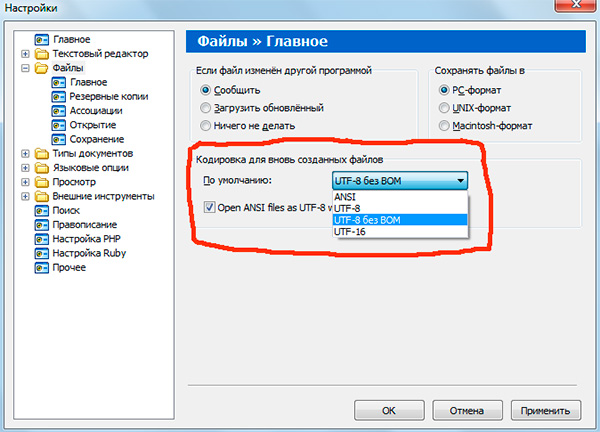
Сразу скажу, что выбирать всегда стоит именно последний вариант — UTF-8 без BOM.
Итак, что же такое BOM и почему нам это не нужно?
BOM расшифровывается как Byte Order Mark. Это специальный Unicode-символ, используемый для индикации порядка байтов текстового файла. По спецификации его использование не является обязательным, однако если BOM используется, то он должен быть установлен в начале текстового файла.
Не будем вдаваться в детали работы BOM. Для нас главный вывод следующий: использование этого служебного символа вместе с UTF-8 мешает программам считывать кодировку нормальным образом, в результате чего возникают ошибки в работе скриптов.
Поэтому, при работе с UTF-8 используйте именно вариант «UTF-8 без BOM». Также лучше не используйте редакторы, в которых в принципе нельзя указать кодировку (скажем, Блокнот из стандартных программ в Windows).
Кодировка текущего файла, открытого в редакторе кода, как правило, указывается в нижней части окна.

Обратите внимание, что запись «ANSI as UTF-8» в редакторе Notepad++ означает то же самое, что и «UTF-8 без BOM». Это одно и то же.

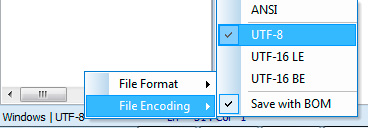
В программе phpDesigner нельзя сразу точно сказать, используется BOM, или нет. Для этого нужно кликнуть правой кнопкой мыши по надписи «UTF-8», после чего во всплывающем окне можно увидеть, используется ли BOM (опция Save with BOM).

В редакторе rapid PHP кодировка UTF-8 без BOM обозначается как «UTF-8*».
Как вы понимаете, в разных редакторах все выглядит немного по-разному, однако главную идею вы поняли.
После того, как документ сохранен в UTF-8 без BOM, нужно также убедиться, что верная кодировка указана в специальном метатэге в секции head вашего html-документа:
Соблюдение этих простых правил уже позволит вам избежать многих пробелем с кодировками.
На этом все, надеюсь, что данный небольшой экскурс и пояснения помогли вам лучше понять, что такое кодировки, какие они бывают и как работают.
Если вам интересна эта тема с более прикладной точки зрения, то рекомендую вам изучить мой видеоурок Полный UTF-8: чеклист для начинающих.
P.S. Присмотритесь к премиум-урокам по различным аспектам сайтостроения, а также к бесплатному курсу по созданию своей CMS-системы на PHP с нуля. Все это поможет вам быстрее и проще освоить различные технологии веб-разработки.
Понравился материал и хотите отблагодарить?
Просто поделитесь с друзьями и коллегами!
Старый DOS
Сайт старых программ
- Список форумов‹Другое‹Флейм
- Изменить размер шрифта
- Для печати
- FAQ
- Регистрация
- Вход
Зачем нужны разные кодировки OEM и ANSI, все эти 866 и 1251
Зачем нужны разные кодировки OEM и ANSI, все эти 866 и 1251
Freeman » 15 июл 2014, 00:48
Ух, какая тема! Не смог пройти мимо. Вынес во флейм, чтобы не флудить в основной.
Пруфы на доказательства абсурдности, пожалуйста. Мож я чего не знаю? Для меня смысл существования разных кодировок для OEM и ANSI прозрачен и лежит на поверхности. Сначала хочу услышать другие мнения, потом выскажу свое.
Re: Зачем нужны разные кодировки OEM и ANSI, все эти 866 и 1251
nongrato » 15 июл 2014, 01:22
Re: Зачем нужны разные кодировки OEM и ANSI, все эти 866 и 1251
SokilOff » 15 июл 2014, 01:54
Дело совсем не в смысле. Просто «так исторически сложилось» С тем же успехом можно спросить «какой смысл в существовании разных дагерротипов/фотопластин/фотопленки (нужное подчеркнуть), когда есть отличные цифровые камеры».
На самом деле те, кто хоть немножко интересовался историей DOS и Windows прекрасно знают, как, когда и почему возникли OEM и ANSI-кодировки. А также почему они получились именно такими, какими получились. И вообще рекомендую к прочтению.
Re: Зачем нужны разные кодировки OEM и ANSI, все эти 866 и 1251
Freeman » 15 июл 2014, 03:07
Re: Зачем нужны разные кодировки OEM и ANSI, все эти 866 и 1251
Nika » 15 июл 2014, 06:10
Порассматривайте пока картинки.
Особенно обратите внимание на жёлтый квадратик с восклицательным знаком на второй картинке (1251) — Украинские буковки I,i .
Это всё шитая белыми нитками лажа. Причём лажа огромных масштабов и приведшая к огромным неудобствам.
Зато в микрософте говнюки оказались вполне довольны своей проделкой. Туеву хучу работающего софта угробили одним махом.
Такова селяви.
И не нужно мне рассказывать про «интегралы», «корни» и «градусы» — кому требуются эти символы, те никогда в тексте их и не набирали,
а пользовались графическими редакторами типа Чиврайтера, Маткада и того же МСВорда.
Теперь об Украинской буковке I,i .
Самое правильное — не заморачиваться, а использовать обычную латинскую I,i (Как я и сделал сейчас в этом тексте).
Но нет — то была бы не микрософт. Поэтому они выделили под неё (в Win1251) отдельный код.
Который сами-же не могут теперь верно взаимно-обратно конвертировать 866 1251.
В результате файлы, имеющие в имени хоть одну украинскую буковку i , я уже в сеансе DOS (c VC или FAR’ом) не могу ни удалить, ни переименовать, ни получить к ним доступа. Потому что при конвертировании имени в DOS-OEM этот символ заменяется вопросительным знаком. А в DOS, как известно, вопросительные знаки в именах запрещены. Так что, пользуемся эксплорером. А чо — тоже очень хорошая программа. Тёткам всем знакомым нравится..
(Кстати, давно собирался сделать WIN32-утилиту, которая бы искала файлы с украинскими i в имени и заменяла бы их на обычные латинские i .Да всё не соберусь. Переименовываю ручками).
866 в WinME
SergeCpp » 15 июл 2014, 07:05
866 таблица в WinME
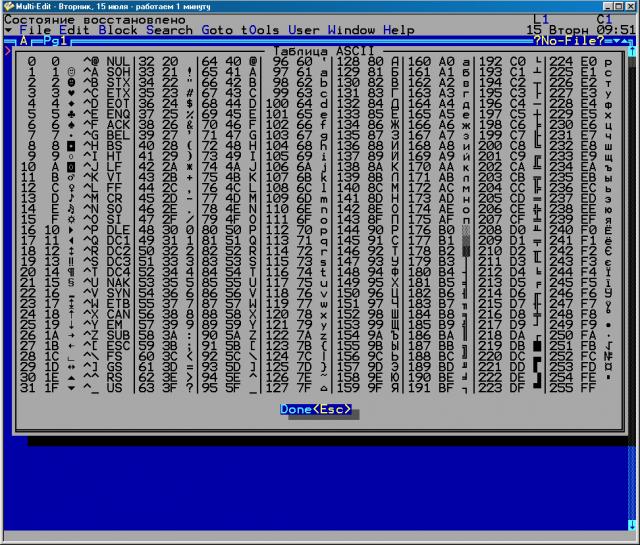
В полный размер: http://old-dos.ru/screens/1328/me_ascii_in_win_me.png
Re: Зачем нужны разные кодировки OEM и ANSI, все эти 866 и 1251
Nika » 15 июл 2014, 07:13
Да, вы видите, что у меня вместо их белорусских УВ,ув — наша украинская ГЕ,ге.
А под УВ,ув можно выделить пару кодов, обведённых синим квадратом. Или любую другую пару кодов.
То-есть, можно все символы нормально разместить, если не заморачиваться «интегралами», «градусами», «корнями» и «плюсами-минусами».
Я акцентирую внимание на том, что замена кодировки 866->1251 НИКАКИХ выгод никому не принесла. Кроме фирмы микрософт.
У остальных — только никому не нужный головняк от всего от этого.
(Кстати, обратите внимание, на фотографии экрана — в обычном хекс-вьювере от VC файл размером 256 байтов с байтами 00..FF
И во втором случае я просто переключил раскладку экранных шрифтов, файл тот же самый.
Только SNARF’ом мне не удалось заскриншотить экран с раскладкой 1251, поэтому пришлось фотографировать его телефоном).
Сперва я тоже хотел запустить MEL.EXE и следом MEW.EXE — было бы то же самое, но не так наглядно.
WinME — Ї и ї
SergeCpp » 15 июл 2014, 07:38
Большая ( Ї ): Alt+0175 в Windows.
Маленькая ( ї ): Alt+0191 в Windows.
В дос-окно переносил мышкой и убирал потом путь (для большей ясности).
В Фаре тоже переименовывается, скрины я уж не стал делать.
Re: Зачем нужны разные кодировки OEM и ANSI, все эти 866 и 1251
Nika » 15 июл 2014, 07:45
Re: Зачем нужны разные кодировки OEM и ANSI, все эти 866 и 1251
SergeCpp » 15 июл 2014, 08:02
Да, я сделал файл Іі (0xB2,0xB3 -Win1251), он имеет короткое имя DOS: «__
1″, а длинное в DOS: «__» (там и там — по два подчёркивания).
ME7 этот файл показывает, открывает (как «__
1″), можно изменить, сохраняет (имя в Windows сохраняется прежнее), но не переименовывает . DOS-окно и Far — тоже не переименовывает. Удалить в Far — можно (только заметно дольше /секунды три-четыре!/ «обычного файла». )! В ME7 — не удаляется.
Re: Зачем нужны разные кодировки OEM и ANSI, все эти 866 и 1251
Nika » 15 июл 2014, 08:07
Ну, а в WinXP полный ступор.
Я ж говорю, надо делать примитивную утититу — чтобы только тыц — и украинская буковка в имени заменилась на латинскую.
— Добавлено —
Кстати, если помните, были такие программы — шутки — перекодировали в тексте всю кириллицу
в сходные по очертаниям латинские символы. Поиск в таком тексте переставал работать.
Этого же можно добиться и простым перекодировщиком типа XLAT.COM
— только нужно подсунуть ему соответствующую перекодировочную таблицу.
Re: Зачем нужны разные кодировки OEM и ANSI, все эти 866 и 1251
SergeCpp » 15 июл 2014, 08:13
1 SUCCESS Іі
30 11:03:36.669 Far:FFF68451 FindClose C:\Z\TEST\__
1 SUCCESS
31 11:03:36.669 Far:FFF68451 Delete C:\Z\TEST\__
Re: Зачем нужны разные кодировки OEM и ANSI, все эти 866 и 1251
Nika » 15 июл 2014, 08:17
Re: Зачем нужны разные кодировки OEM и ANSI, все эти 866 и 1251
SergeCpp » 15 июл 2014, 08:22
В ME у меня для проверки такого есть специальное регулярное выражение с собственным названием , см. Control+F, [X] Сокращения, F3, «English-Russian mix», F3.
В TODO есть запись, что надо бы и команду такую сделать, но пока и рег.выр. хватает.
Re: Зачем нужны разные кодировки OEM и ANSI, все эти 866 и 1251
Nika » 15 июл 2014, 08:29



