- Кривые файлы txt. Или как настроить кодировку на Mac
- Решение проблемы
- FAQ: Как подружить TextEdit с текстовыми файлами, созданными в Windows
- Какая кодировка правильно открывает CSV-файлы в Excel как на Mac, так и на Windows?
- 15 ответов:
- Кодировки Excel
- Преобразование
- Приводим русские тексты на Mac OS X в одну кодировку Python-скриптом
Кривые файлы txt. Или как настроить кодировку на Mac

Скорее всего многим пользователям Mac приходилось работать с файлами txt. Чаще всего в этом формате представлены различные мануалы, readme, инструкции и т.д. И если эти документы были созданы в Windows среде, то при открытии их на Mac, может возникнуть небольшая, но в тоже время крайне неприятная проблема с кодировкой.
Давайте вместе разберёмся как научить Mac на 100% распознавать txt файл созданный на «Винде».
Дело в том, что операционные системы Apple и Microsoft руководствуется разными стандартами при кодировании кириллицы, отсюда и проблемы с её отображением. Существуют специальные утилиты призванные подружить кодировку Windows с Mac OS X, но предлагаю обойтись штатными средствами.
Решение проблемы
Исходную кодировку на Mac нужно сменить на Windows Cyrillic. Для этого находим в домашней папке скрытый файл .CFUsertextEncoding.

Для отображения скрытых файлов необходимо зайти в Терминал (программы > утилиты) и ввести команду (можете скопировать).
и нажать enter.
Далее, для того чтобы изменения вступили в силу, нужно перезапустить Finder. Вводим команду.
и опять enter.
Для того чтобы опять сделать файлы скрытыми, нужно заменить в первой команде true на false, а затем опять перезапустить Finder.
Итак, кликаем по этому файлу правой кнопкой и в подразделе «открыть в программе» выбираем TextEdit. В документе присутствует только одна строка, в которой нужно значение 0x7 заменить на 0x502. После чего сохраняем файл, перезагружаем Mac и радуемся.
Если помогла статья, не ленись. Нажми кнопку — поделись! )
FAQ: Как подружить TextEdit с текстовыми файлами, созданными в Windows
 Если вы хотите увидеть на нашем сайте ответы на интересующие вас вопросы обо всём, что связано с техникой Apple, операционной системой Mac OS X (и её запуском на PC), пишите нам через форму заявки на обзор или форму обратной связи.
Если вы хотите увидеть на нашем сайте ответы на интересующие вас вопросы обо всём, что связано с техникой Apple, операционной системой Mac OS X (и её запуском на PC), пишите нам через форму заявки на обзор или форму обратной связи.
К нам поступил следующий вопрос:
недавно купил себе iMac, я новичок в мире Маков, так что извините за глупый вопрос. всё замечательно, но жутко раздражает, что MacOS не умеет нормально открывать текстовые файлы на русском. всегда какие-то закорюки показывает. как это можно исправить? или в какой-то другой программе открывать надо?
Этот вопрос, пожалуй, нужно включать в инструкцию к каждому новому Маку, продаваемому в России. Действительно, то ли по недосмотру, то ли от лени разработчиков Mac OS X встроенный в систему текстовый редактор TextEdit не умеет работать с русскими кодировками текста. Из-за этого все текстовый файлы txt, созданные или отредактированные в Windows, на Маках выглядят совершенно нечитаемыми.
К счастью, проблема поправима — достаточно лишь заглянуть в настройки TextEdit. Зайдите на вторую их вкладку, которая называется «Открытие и сохранение»:
 Нас интересует выпадающий список «Открытие файлов». Как видите, по умолчанию здесь выбран пункт «Автоматически», и зря. Более того, если посмотреть на содержимое списка, там вы не увидите Windows-кодировок вообще. Но это не значит, что их туда нельзя добавить. В выпадающем списке выберите самый нижний пункт — «Настроить список кодировок». Откроется ещё одно окошко:
Нас интересует выпадающий список «Открытие файлов». Как видите, по умолчанию здесь выбран пункт «Автоматически», и зря. Более того, если посмотреть на содержимое списка, там вы не увидите Windows-кодировок вообще. Но это не значит, что их туда нельзя добавить. В выпадающем списке выберите самый нижний пункт — «Настроить список кодировок». Откроется ещё одно окошко:
 Пометьте в нём галочками пункты «Кириллическая (Windows)» и «Кириллическая (KOI8-R)». Можно заодно выбрать и все остальные русские и кириллические кодировки. После этого есть шанс, что TextEdit заработает нормально. Если нет, то в уже упомянутом списке «Открытие файлов» вместо «Автоматически» выберите «Кириллическая (Windows)». Тогда проблемы с русскими текстами точно исчезнут.
Пометьте в нём галочками пункты «Кириллическая (Windows)» и «Кириллическая (KOI8-R)». Можно заодно выбрать и все остальные русские и кириллические кодировки. После этого есть шанс, что TextEdit заработает нормально. Если нет, то в уже упомянутом списке «Открытие файлов» вместо «Автоматически» выберите «Кириллическая (Windows)». Тогда проблемы с русскими текстами точно исчезнут.
Какая кодировка правильно открывает CSV-файлы в Excel как на Mac, так и на Windows?
У нас есть веб-приложение, которое экспортирует CSV-файлы, содержащие иностранные символы с UTF-8, без BOM. Пользователей Windows и Mac сделать символы в Excel. Я попробовал конвертировать в UTF-8 с помощью BOM; Excel / Win-это нормально, Excel/Mac показывает тарабарщину. Я использую Excel 2003 / Win, Excel 2011 / Mac. Вот все кодировки, которые я пробовал:
Лучшим является UTF-16LE с BOM, но CSV не распознается как таковой. Разделитель полей-запятая, но точка с запятой не меняется вещи.
Есть ли кодировка, которая работает в обоих мирах?
15 ответов:
Кодировки Excel
Я нашел кодировку WINDOWS-1252 наименее неприятной при работе с Excel. Так как его в основном Microsofts собственный проприетарный набор символов, можно предположить, что он будет работать как на Mac, так и на Windows версии MS-Excel. Обе версии, по крайней мере, включают соответствующий селектор «происхождение файла» или «кодирование файла», который правильно считывает данные.
В зависимости от вашей системы и используемых инструментов, эта кодировка также может быть названа CP1252 , ANSI , Windows (ANSI) , MS-ANSI или Просто Windows , среди прочих вариантов.
Эта кодировка является надмножеством ISO-8859-1 (он же LATIN1 и другие), так что вы можете вернуться к ISO-8859-1 , Если вы не можете использовать WINDOWS-1252 по какой-то причине. Имейте в виду, что ISO-8859-1 не хватает некоторых символов из WINDOWS-1252 , как показано здесь:
Обратите внимание, что знак евроотсутствует . Эту таблицу можно найти по адресу Alan Wood.
Преобразование
Преобразование выполняется по-разному в каждом инструменте и языке. Однако предположим, что вы имейте файл query_result.csv , который, как вы знаете, закодирован UTF-8 . Преобразуйте его в WINDOWS-1252 , используя iconv :
Для UTF-16LE с BOM если вы используете символы табуляции в качестве разделителей вместо запятых Excel распознает поля. Причина, по которой это работает, заключается в том, что Excel фактически использует свой Unicode *.txt парсер.
Примечание : Если файл отредактирован в Excel и сохранен, он будет сохранен как разделенный табуляцией ASCII. Проблема теперь в том, что при повторном открытии файла Excel предполагает, что это настоящий CSV (с запятыми), видит, что это не Юникод, поэтому анализирует его как разделенный запятыми — и, следовательно, сделает гашиш из него!
Update : по крайней мере, в Excel 2010 (Windows) вышеприведенная оговорка не происходит для меня сегодня, хотя, похоже, есть разница в поведении сохранения, если:
- изменения и закройте Excel (пытается сохранить как Юникод *.txt’)
- редактирование и закрытие только файла (работает, как и ожидалось).
Самое низкое: нет никакого решения. Excel 2011 / Mac не может правильно интерпретировать CSV-файл, содержащий умлауты и диакритические знаки, независимо от того, какую кодировку или прыжки с обручами вы делаете. Я был бы рад услышать, что кто-то говорит мне другое!
Вы пробовали только CSV-файлы, разделенные запятыми и точками с запятой. Если бы вы попробовали разделенный вкладками CSV (также называемый TSV) , вы бы нашли ответ:
UTF-16LE с BOM (метка порядка байтов), tab-separated
Но : в комментарии вы упоминаете, что TSV-это не вариант для вас (хотя я не смог найти это требование в вашем вопросе). Какая жалость. Это часто означает, что вы разрешаете ручное редактирование файлов TSV, которые вероятно, это не очень хорошая идея. Визуальная проверка файлов TSV не является проблемой. Кроме того, редакторы могут быть настроены на отображение специального символа для обозначения вкладок.
И да, я попробовал это на Windows и Mac.
Лучшим решением для чтения CSV-файлов с помощью UTF-8 на Mac является их преобразование в формат XLSX. Я нашел сценарий, сделанный Конрадом Ферстнером, который я немного улучшил, добавив поддержку различных символов-разделителей.
Загрузите скрипт с Github https://github.com/brablc/clit/blob/master/csv2xlsx.py . для его запуска вам потребуется установить модуль python openpyxl для работы с файлами Excel: sudo easy_install openpyxl .
Вот решающий аргумент при импорте CSV в кодировке utf8 в Excel 2011 для Mac: Microsoft говорит: «Excel для Mac в настоящее время не поддерживает UTF-8.»Excel для Mac 2011 и UTF-8
Мне кажется, что Excel 2011 для Mac OS не использует кодировку.GetEncoding («10000»), как я и думал, потратил впустую 2 дня с тем же iso, что и на Microsoft OS. Лучшим доказательством этого является создание файла в Excel 2011 для MAC со специальными символами, сохранение его в формате CSV, а затем открытие его в текстовом редакторе MAC, и символы скремблируются.
Для меня этот подход работал-это означает, что экспорт csv в Excel 2011 на MAC OS имеет специальные западноевропейские символы внутри:
UTF-8 без BOM в настоящее время работает для меня в Excel Mac 2011 14.3.2.
UTF-8 + BOM вроде работает, но BOM передается как тарабарщина.
UTF-16 работает, если вы импортируете файл и завершаете работу мастера, но не если вы просто дважды щелкните его.
Следующее работало для меня в Excel для Mac 2011 и Windows Excel 2002:
Используя iconv на Mac, преобразуйте файл в UTF-16 Little-Endian + name it *.txt (the .расширение txt заставляет Excel запустить мастер импорта текста):
iconv -f UTF-8 -t UTF-16LE filename.csv >filename_UTF-16LE.csv.txt
Откройте файл в Excel и в Мастере импорта текста выберите:
- Шаг 1: происхождение файла : игнорируйте его, не имеет значения, что вы выберете
- Шаг 2: Выберите правильные значения для разделители и квалификатор текста Шаг 3: при необходимости выберите форматы столбцов
PS UTF-16LE, созданный iconv, имеет BOM байты FF FE в начале.
PPS мой оригинальный csv-файл был создан на компьютере с Windows 7, в формате UTF-8 (с байтами BOM EF BB BF в начале) и использовал разрывы строк CRLF. В качестве разделителя полей использовалась запятая, а в качестве квалификатора текста-одинарная кавычка. Он содержал буквы ASCII плюс другую латынь буквы с тильдами, умлаутом и т.д., Плюс немного кириллицы. Все правильно отображается как в Excel для Win, так и в Mac.
Точные версии программного обеспечения PPPS:
* Mac OS X 10.6.8
* Excel для Mac 2011 V. 14. 1. 3
* Windows Server 2003 SP2
* Окна Excel 2002 г. в. 10.2701.2625
В моем случае это сработало (Mac, Excel 2011, Как кириллические, так и латинские символы с чешскими диакритиками):
- кодировка UTF-16LE (просто UTF-16 было недостаточно)
- BOM «\xFF\xFE «
- \t (tab) как разделитель
- Не забудьте также закодировать разделитель и CRLFs: -)
- Используйте iconv вместо mb_convert_encoding
На моем Mac OS Text Wrangler идентифицировал CSV-файл, созданный с помощью Excel, как имеющий «Западную» кодировку.
После некоторого гугления я сделал этот небольшой скрипт (я не уверен в доступности Windows, может быть, с Cygwin ?):
Вместо csv, попробуйте вывести html с расширением XLS и mime-типом «application / excel». Я знаю, что это будет работать в Windows, но не могу говорить за MacOS
- Откройте файл в BBEdit или TextWrangler*.
- задайте файл как Unicode (UTF-16 Little-Endian) (окончания строк могут быть Unix или Windows). Спасите!
- В Excel: Данные > Получить Внешние Данные > Импортировать Текстовый Файл.
Теперь ключевой момент, выберите MacIntosh В качестве источника файла (это должен быть первый выбор).
Используется Excel 2011 (версия 14.4.2)
*в нижней части окна есть небольшое выпадающее меню
Решите это с помощью java (UTF-16LE с BOM ):
Обратите внимание, что CSV-файл должен использовать TAB в качестве разделителя. Вы можете прочитать файл CSV как на windows, так и на MAC OS X.
В моем случае добавление преамбулы к файлу решило мою проблему:
Приводим русские тексты на Mac OS X в одну кодировку Python-скриптом
Случилось мне иметь ноут на OS X, комп на Linux и одного из друзей с Windows. И вот через dropbox обмениваются все эти три компа документами разными. В том числе и текстовыми, в которых хранятся разные заметки, задачи и т.п. И вот незадача: тексты написанные на MacOSx плохо читаются в блокноте Винды, а виндовые в textedit на MacOSx.
И вся причина в том, что на винде блокнот использует кодировку Windows 1251, а на OS X используется по умолчанию MACCYRILLIC. Причем обе программы без проблем работают с UTF-8 кодировкой.
Вот только конвертировать из одной кодировки в другую как-то неудобно, лишнее время тратить на открытие терминала и набор заветных команд iconv…
Пораздумав, написал небольшой скрипт, который сам определяет используемую кодировку и конвертирует в UTF-8 все txt-файлы.
Что использую для всего:
Python 2.7
Mac OS X 10.7.5
PyCharm IDE
Изначально сделал определение кодировки самостоятельно, без дополнительных модулей. Но по совету ad3w решил переписать с использованием готового модуля chardet для определения кодировки.
Кому интересно, предыдущий
Определение происходит простым перебором кодировок и выбором той, в которой не будет лишних символов. А набор символов определяете Вы. Конечно этот способ не подойдет для файлов с DOS-графикой, но в обычных целях использования txt его вполне хватит.
Скачиваем модуль chardet 1.1,
Распаковываем и устанавливаем:
Создаем свой скрипт для перекодировки файлов:
Далее необходимо сделать удобным запуск данного скрипта прямо из папки в OS X.
Открываем Automator и создаем Службу.
Вверху выбираем пункты, чтобы получилось «Служба получает файлы и папки в Finder.app».
Далее ставим действие «получить выбранные объекты Finder».
Далее «Запустить Shell-скрипт» в настройках его «Передать ввод: как аргументы» и в нем содержание:
Дописал 2>/dev/null, чтобы автоматор не останавливал выполнение при выводе ошибки модуля chardet.
И последний пункт «Show Growl Notification» (в нем можно написать, что конвертация произведена). 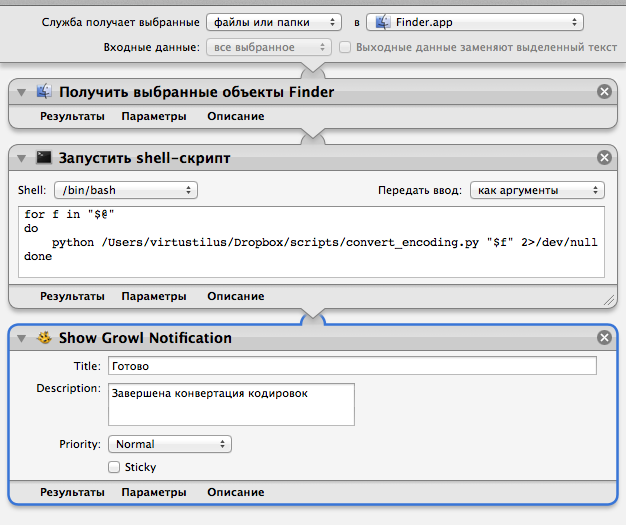
Сохраняем с именем латинскими буквами (с русскими у меня почему-то пункт в меню не появлялся, пока не переименовал) и проверяем.
Новый пункт меню появится в Finder в меню файлов и папок в подменю Сервисы.



