- Определение разрыва TCP-соединения
- Введение
- Таймер keep-alive
- Заключение
- SO_KEEPALIVE socket option
- Socket option value
- Syntax
- Parameters
- Return value
- Remarks
- Keepalived: настройка высокой доступности и плавающих IP адресов в CentOS 7
- Принципы работы протокола VRRP
- Установка и настройка keepalived на CentOS
- Keepalived: отслеживание состояния приложений и интерфейсов
- Keepalived: тестирование переключения при отказе
Определение разрыва TCP-соединения
Автор: Андрей Елсуков
Источник: RSDN Magazine #1-2004
Опубликовано: 03.10.2004
Исправлено: 10.12.2016
Версия текста: 1.0
Введение
Протокол TCP, в отличие от UDP, осуществляет доставку дейтаграмм, называемых сегментами, в виде байтовых потоков с установлением соединения. TCP применяется в тех случаях, когда требуется гарантированная доставка сообщений. Он использует контрольные суммы пакетов для проверки их целостности, контролирует последовательность передаваемых данных и избавляет программиста от многих рутинных задач. В качестве примеров прикладных протоколов, использующих TCP, можно назвать протокол FTP, HTTP, SMTP и многие другие.
| ПРИМЕЧАНИЕ В данной статье речь будет идти о реализациях стека TCP/IP в Microsoft Windows NT/2000/XP и более поздних версиях, а также реализации Windows Sockets версии 2 и более поздних. Будучи однажды создан, канал TCP может существовать «вечно». Если клиент и сервер пассивны, то при разрыве соединения, например, при проблемах со средой передачи, сетевой атаке, крахе сервера или клиента, участники соединения (либо один из них) не подозревают о возникших проблемах. Конечно, проблема рано или поздно будет выявлена — когда клиент или сервер попытаются послать какую-то информацию. В архитектуре клиент-сервер довольно часто встречаются реализации, в которых клиент, отправив запрос на сервер, долгое время ожидает ответа сервера. Еще более актуальная ситуация — в реализациях TCP-сервера необходимо точно знать, сколько из соединившихся клиентов реально существуют. Многие из прикладных протоколов применяют для этого «пустую операцию» (NOP), которая время от времени производится между клиентом и сервером для проверки наличия соединения. Данный подход хорош тем, что он не зависит от реализации стека TCP/IP. Есть и другой метод – таймер контроля работоспособности (keep-alive). Таймер keep-aliveПринцип работы этого таймера предельно прост. Если канал между клиентом и сервером пассивен некоторое время (по умолчанию 2 часа), то посылается служебное сообщение, если ответа на него не поступило, через 75 секунд (обычно) сообщение посылается повторно и так несколько раз. Если ответ получен – таймер сбрасывается, и отчёт начинается заново. Если после нескольких повторов ответа так и не поступило, то соединение разрывается. Число повторов зависит от реализации стека TCP/IP, в некоторых реализациях может изменяться, в некоторых – нет… При использовании сокетов в Windows keep-alive сообщения по умолчанию выключены. Включить их можно с помощью функции setsockopt : В качестве параметров в функцию передаются:
Для включения/выключения посылки keep-alive используется опция SO_KEEPALIVE уровня SOL_SOCKET. Параметр optval интерпретируется функцией как булево значение, для включения посылки он должен иметь значение TRUE, иначе – FALSE. На практике нет никакого смысла ждать 2 часа до посылки keep-alive сообщения, куда интереснее более реальные интервалы времени (несколько десятков секунд или минут). Для изменения этого интервала в Winsock2 предусмотрена функция WSAIoctl : В качестве параметров в функцию передаются:
Для изменения интервалов времени нужно передать функции структуру tcp_keepalive с кодом операции SIO_KEEPALIVE_VALS, которые определены в заголовочном файле mstcpip.h . Поле onoff отвечает за включение/выключение посылки keep-alive сообщений. Если его значение отлично от нуля – посылка будет осуществляться, иначе — нет. Поле keepalivetime определяет интервал между посылкой сообщений при пассивном состоянии канала. Поле keepaliveinterval определяет интервал посылки сообщений, если ответ не получен. Интервалы задаются в миллисекундах. Значения интервалов имеют силу только в пределах соединения, связанного с сокетом s. ЗаключениеВ MSDN очень скупо описано все, что связано с keep-alive. После практических испытаний я обнаружил, что функция WSAIoctl перекрывает действие setsockopt . Точнее, действие setsockopt мною не проверено, потому как ждать 2 часа у меня терпения не хватает. А вызов setsockopt после WSAIoctl ни к чему не приводит. Если кто-то осведомлён о работе этих функций больше меня, буду рад выслушать пояснения. Для проверки работы keep-alive я написал простенькую программку, которая соединяется с 21-м портом по заданному адресу. Интервал посылки keep-alive сообщений устанавливается равным 10 секундам, с повтором через 1 секунду. Далее я пользовался анализатором трафика и пакетным фильтром. С помощью пакетного фильтра создал ситуацию потери связи с сервером, в результате которой после нескольких безответных посылок keep-alive возникает событие FD_CLOSE. Исходник проекта (MSVC 7.0) прилагается в архиве. SO_KEEPALIVE socket optionThe SO_KEEPALIVE socket option is designed to allow an application to enable keep-alive packets for a socket connection. To query the status of this socket option, call the getsockopt function. To set this option, call the setsockopt function with the following parameters. Socket option valueThe constant that represents this socket option is 0x0008. SyntaxParametersA descriptor identifying the socket. The level at which the option is defined. Use SOL_SOCKET for this operation. The socket option for which the value is to be set. Use SO_KEEPALIVE for this operation. A pointer to the buffer containing the value for the option to set. This parameter should point to buffer equal to or larger than the size of a DWORD value. This value is treated as a boolean value with 0 used to indicate FALSE (disabled) and a nonzero value to indicate TRUE (enabled). A pointer to the size, in bytes, of the optval buffer. This size must be equal to or larger than the size of a DWORD value. Return valueIf the operation completes successfully, setsockopt returns zero. If the operation fails, a value of SOCKET_ERROR is returned and a specific error code can be retrieved by calling WSAGetLastError.
RemarksThe getsockopt function called with the SO_KEEPALIVE socket option allows an application to retrieve the current state of the keepalive option, although this is feature not normally used. If an application needs to enable keepalive packets on a socket, it justs calls the setsockopt function to enable the option. The setsockopt function called with the SO_KEEPALIVE socket option allows an application to enable keep-alive packets for a socket connection. The SO_KEEPALIVE option for a socket is disabled (set to FALSE) by default. When this socket option is enabled, the TCP stack sends keep-alive packets when no data or acknowledgement packets have been received for the connection within an interval. For more information on the keep-alive option, see section 4.2.3.6 on the Requirements for Internet Hosts—Communication Layers specified in RFC 1122 available at the IETF website. (This resource may only be available in English.) The SO_KEEPALIVE socket option is valid only for protocols that support the notion of keep-alive (connection-oriented protocols). For TCP, the default keep-alive timeout is 2 hours and the keep-alive interval is 1 second. The default number of keep-alive probes varies based on the version of Windows. The SIO_KEEPALIVE_VALS control code can be used to enable or disable keep-alive, and adjust the timeout and interval, for a single connection. If keep-alive is enabled with SO_KEEPALIVE, then the default TCP settings are used for keep-alive timeout and interval unless these values have been changed using SIO_KEEPALIVE_VALS. The default system-wide value of the keep-alive timeout is controllable through the KeepAliveTime registry setting which takes a value in milliseconds. The default system-wide value of the keep-alive interval is controllable through the KeepAliveInterval registry setting which takes a value in milliseconds. On WindowsВ Vista and later, the number of keep-alive probes (data retransmissions) is set to 10 and cannot be changed. On Windows ServerВ 2003, WindowsВ XP, and WindowsВ 2000, the default setting for number of keep-alive probes is 5. The number of keep-alive probes is controllable through the TcpMaxDataRetransmissions and PPTPTcpMaxDataRetransmissions registry settings. The number of keep-alive probes is set to the larger of the two registry key values. If this number is 0, then keep-alive probes will not be sent. If this number is above 255, then it is adjusted to 255. On WindowsВ Vista and later, the SO_KEEPALIVE socket option can only be set using the setsockopt function when the socket is in a well-known state not a transitional state. For TCP, the SO_KEEPALIVE socket option should be set either before the connect function (connect, ConnectEx, WSAConnect, WSAConnectByList, or WSAConnectByName) is called, or after the connection request is actually completed. If the connect function was called asynchronously, then this requires waiting for the connection completion before trying to set the SO_KEEPALIVE socket option. If an application attempts to set the SO_KEEPALIVE socket option when a connection request is still in process, the setsockopt function will fail and return WSAEINVAL. On Windows ServerВ 2003, WindowsВ XP, and WindowsВ 2000, the SO_KEEPALIVE socket option can be set using the setsockopt function when the socket is a transitional state (a connection request is still in progress) as well as a well-known state. Keepalived: настройка высокой доступности и плавающих IP адресов в CentOS 7В этой статье мы рассмотрим настройку отказоустойчивой конфигурации из двух прокси серверов squid для доступа пользователей в Интернет из корпоративной сети с простой балансировкой нагрузки через Round Robin DNS. Для построения отказоустойчивой конфигурации мы создадим HA-кластер с помощью keepalived. HA-кластер — это группа серверов с заложенной избыточностью, которая создается с целью минимизации времени простоя приложения, в случае аппаратных или программных проблем одного из членов группы. Исходя из этого определения, для работы HA-кластера необходимо реализовать следующее:
Обе эти задачи позволяет выполнить keepalived. Keepalived – системный демон на Linux системах, позволяющего организовать отказоустойчивость сервиса и балансировку нагрузки. Отказоустойчивость достигается за счет “плавающего» IP адреса, который переключается на резервный сервер в случае отказа основного. Для автоматического переключения IP адреса между серверами keepalived используется протокол VRRP (Virtual Router Redundancy Protocol), он стандартизирован, описан в RFC (https://www.ietf.org/rfc/rfc2338.txt). Принципы работы протокола VRRPВ первую очередь нужно рассмотреть теорию и основные определения протокола VRRP.
Общий алгоритм работы:
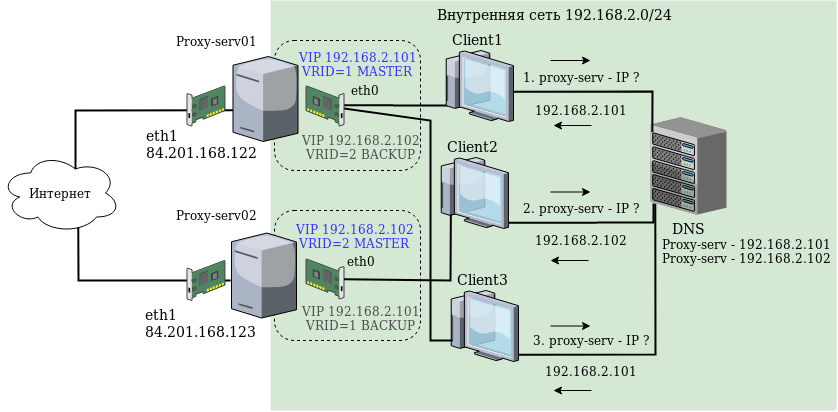
Установка и настройка keepalived на CentOSУстановку и настройку будем проводить на примере серверов proxy-serv01 и proxy-serv02 на Centos 7 с установленным Squid. В нашей схеме мы будем использовать простейший способ распределения (балансировки) нагрузки — Round Robin DNS. Этот способ предполагает, что для одного имени в DNS регистрируется несколько IP адресов, и клиенты, при запросе получают поочередно сначала один адрес, потом другой. Поэтому нам понадобится два виртуальных IP адреса, которые будут зарегистрированы в DNS на одно имя и на которые в итоге будут обращаться клиенты. Схема сети:
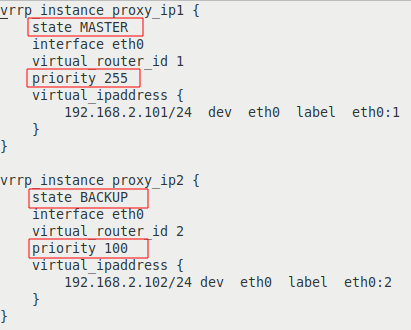
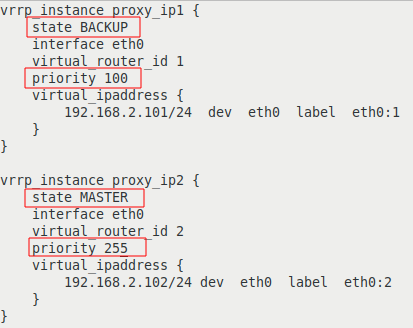
У каждого Linux сервера есть два физических сетевых интерфейса: eth1 с белым IP адресом и доступом в Интернет, и eth0 в локальной сети. В качестве реальных IP адресов серверов используются: В качестве виртуальных IP адресов, которые будут автоматически переключаться между серверами в случае сбоев используются: Установить пакет keepalived нужно на обоих серверах, командой: yum install keepalived После завершения установки на обоих серверах правим конфигурационный файл Цветом выделены строки с отличающимися параметрами:
Разберем опции более подробно:
Если текущая сетевая конфигурация не позволяет использовать multicast, в keepalived есть возможность использовать unicast, т.е. передавать VRRP пакеты напрямую серверам, которые задаются списком. Чтобы использовать unicast, понадобятся опции:
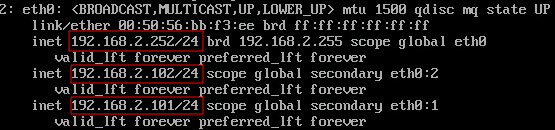
Таким образом, наша конфигурация определяет два VRRP экземпляра, proxy_ip1 и proxy_ip2. При штатной работе, сервер proxy-serv01 будет MASTER для виртуального IP 192.168.2.101 и BACKUP для 192.168.2.102, а сервер proxy-serv02 наоборот, будет MASTER для виртуального IP 192.168.2.102, и BACKUP для 192.168.2.101. Если на сервере активирован файрвол, то нужно добавить разрешающие правила для multicast траффика и vrrp протокола с помощью iptables: iptables -A INPUT -i eth0 -d 224.0.0.0/8 -j ACCEPT Активируем автозагрузки и запустим службу keepalived на обоих серверах: systemctl enable keepalived После запуска службы keepalived, виртуальные IP будут присвоены интерфейсам из конфигурационного файла. Посмотрим текущие IP адреса на интерфейсе eth0 серверов: На сервере proxy-serv01:
На сервере proxy-serv02:
Keepalived: отслеживание состояния приложений и интерфейсовБлагодаря протоколу VRRP штатно обеспечивается мониторинг состояния сервера, например, при полном физическом отказе сервера, или сетевого порта на сервере или коммутаторе. Однако, возможны и другие проблемные ситуации:
Для обработки перечисленных выше ситуаций, воспользуемся следующими опциями:
Обновим конфигурацию, добавим мониторинг интерфейса eth1 (по умолчанию, VRRP экземпляр будет проверять интерфейс, к которому он привязан, т.е. в текущей конфигурации eth0): Директива track_script запускает скрипт с параметрами, определенными в блоке vrrp_script, который имеет следующий формат: Настроим мониторинг работы Squid. Проверить, что процесс активен, можно командой: Создадим vrrp_script, с параметрами периодичности выполнения каждые 3 секунды. Этот блок определяется за пределами блоков vrrp_instance. Добавим наш скрипт в мониторинг, внутри обоих блоков vrrp_instance: Теперь при ошибке в работе службы прокси Squid, виртуальный IP адрес переключится на другой сервер. Вы можете добавить дополнительные действия при изменении состояния сервера. Если Squid настроен на прием подключений с любого интерфейса, т.е. http_port 0.0.0.0:3128, то при переключении виртуального IP адреса, никаких проблем не возникнет, Squid будет принимать подключения на новом адресе. Но, если настроены конкретные IP адреса, например: то Squid не узнает о том, что в системе появился новый адрес, на котором нужно слушать запросы от клиентов. Для обработки подобных ситуаций, когда нужно выполнить дополнительные действия при переключении виртуального IP адреса, в keepalived заложена возможность выполнения скрипта при наступлении события изменения состояния сервера, например, с MASTER на BACKUP, или наоборот. Реализуется опцией: Keepalived: тестирование переключения при отказеПосле настройки виртуальных IP, проверим, насколько корректно происходит обработка сбоев. Первая проверка — имитация сбоя одного из серверов. Отключим от сети внутренний сетевой интерфейс eth0 сервера proxy-serv01, при этом он перестанет отправлять VRRP пакеты и сервер proxy-serv02 должен активировать у себя виртуальный IP адрес 192.168.2.101. Результат проверим командой: На сервере proxy-serv01:
На сервере proxy-serv02:
Как и ожидалось, сервер proxy-serv02 активировал у себя виртуальный IP адрес 192.168.2.101. Посмотрим, что при этом происходило в логах, командой: cat /var/log/messages | grep -i keepalived
И проверим, что после включения в сеть интерфейса eth0 на сервере proxy-serv01, виртуальный IP 192.168.2.101 переключится обратно.
Вторая проверка – имитация сбоя интерфейса внешний сети, для этого отключим от сети внешний сетевой интерфейс eth1 сервера proxy-serv01. Результат проверки проконтролируем по логам.
Третья проверка — имитация сбоя работы службы прокси Squid, для этого вручную оставим службу командой: systemctl stop squid Результат проверки проконтролируем по логам.
Все три проверки пройдены успешно, keepalived настроен корректно. В продолжении этой статьи будет произведена настройка HA-кластера с помощью Pacemaker, и рассмотрена специфика каждого из этих инструментов. |