- Favicon
- Обучаем вместе с Tesseract OCR
- 0. Что нам нужно
- 1. Создаём и редактируем box-файл
- Как установить tesseract ocr для windows
- Ответы (3)
- Распознавание текста с картинки. Python Tesseract ORC + OpenCV
- Что сделаем за урок?
- Установка библиотеки
- Разработка проекта
- Начало работы с оптическим распознаванием символов (OCR) с Tesseract в Symfony 3
- 1. Установите Tesseract в вашей системе
- Windows
- Ubuntu
- MacOS
- MacPorts
- Homebrew
- 2. Установите PHP-оболочку Tesseract
- 3. Реализация в контроллере
- 4. Поддержка языков
- 5. Пользовательские параметры
- Изменить путь к исполняемому файлу
- Сегментация страницы
- Установите языки для распознавания
- Используйте слова из списка
- Белый список персонажей
- Установить значение конфигурации
Favicon
Блог по web технологиям. Веб студия г. Воронеж. Создание и поддержка сайтов на заказ.
- Главная
- /
- Разное
- /
- Обучаем вместе с Tesseract OCR
Обучаем вместе с Tesseract OCR
Tesseract — свободная платформа для оптического распознавания текста, исходники которой Google подарил сообществу в 2006 году. Если вы пишете софт для распознавания текста, то вам наверняка приходилось обращаться к услугам этой мощной библиотеки. И если она не справилась с вашим текстом (а скорее всего это именно так), то выход у вас остаётся один — научить её. Процесс этот достаточно сложный и изобилует не очевидными, а порой и прям-таки магическими действиями.
Оригинальный проект находится на гитхабе, а скачать установщик можно здесь, На момент написания статьи версия установщика была 3.05.01. Мне понадобилось немало времени на постижение всей его глубины, поэтому я решил написать что и как, вдруг забуду что-то в будущем, а также чтобы помочь другим пройти этот путь в следующий раз быстрее.
0. Что нам нужно
- Tesseract собственно.
Сборки этой библиотеки есть под windows (можно скачать установщик отсюда) и под linux. Для большинства linux-дистрибутивов установить tesseract можно просто через sudo apt-get install tesseract-ocr.
- Изображение с текстом для тренировки
Желательно чтобы это был реальный текст, который потом придётся распознавать. Важно, чтобы каждый символ шрифта встречался в сканированном фрагменте не менее 5 раз, а желательно — 20 раз. Использовать будем формат tiff, без сжатия, желательно не многостраничный, но можно и многостраничный. Создать многостраничный tiff можно с помощью просмотрщика IrfanView .
Между всеми символами должны быть чётко различимые промежутки. Кладём наше изображение в отдельную директорию и называем в виде . .exp .tif. Изображение может быть не одно и отличаться они должны только номером в наименовании файла. Формат наименований файлов очень важен. На файлы с неверными наименованиями утилиты, которые мы будем использовать будут ругаться ошибками сегментирования и т.п. Для определённости будем считать, что изучаем мы язык ссс и шрифт eee. Таким образом называем файл со сканом тренировочного образца ccc.eee.exp0.tif
1. Создаём и редактируем box-файл
Для того чтобы отметить символы на изображении и задать им соответствие utf-8 символам текста служат box-файлы. Это обычные текстовые файлы, в которых каждому символу соответствует строка с символом и координатами прямоугольника в пикселях. Первоначально файл генерируем утилитой из пакета tesseract:
tesseract ccc.eee.exp0.tif ccc.eee.exp0 batch.nochop makebox
получим файл
в текущей директории. Заглянем в него. Да, чуть не забыл, не забудьте прописать адрес установленной Tesseract-OCR в переменную среды Path в windows, иначе команда tesseract не будет работать в консоли.
Символы в начале строки полностью соответствуют символам в файле? Если это так, то тренировать ничего не нужно, вы можете спать спокойно. В нашем случае скорее всего символы не будут совпадать ни по существу ни по количеству. Т.е. tesseract со словарём по умолчанию не распознал не только символы, но и посчитал некоторые из них за два или больше. Возможно часть символов у нас «слипнется», т.е. попадёт в общую коробку и будет распознано как один. Это всё нужно поправить прежде чем идти дальше.
Работа нудная и кропотливая, но к счастью для этого есть ряд сторонних утилит. Я например пользовался jTessBoxEditor. Открываем им изображение, box-файл с таким же именем он сам подтянет (главное чтобы всё лежало в одной папке).
Переходим на вкладку Box Editor перетаскиваем туда наше изображение, либо жмем Open . Поигравшись немного с вкладками Box Coordinates , где с помощью кнопок Merge , Split , Insert , Delete можно соответственно объединить, разделить, добавить или удалить символы, дабы привести все в соответствии с изображением справа. Во вкладке Box View можно поправить координаты распознаваемого символа.
Прошло полдня… Вы с чувством глубокого удовлетворения закрываете jTessBoxEditor (вы ведь не забыли сохранить результат, верно?) и у вас есть корректный box-файл. Теперь можно переходить к следующему этапу.
Как установить tesseract ocr для windows
4469 просмотра
3 ответа
Я скачал исполняемый файл tesseract-OCR и установил его. С другой стороны, я также скачал zip-файл leptonica с http://www.leptonica.com/download.html . Он включает в себя два каталога, который есть lib и include .
Затем я попытался сделать pip install tesserocr в Python virtualenvironment и он вернул ошибку
Я заметил, что allheaders.h находится в include каталоге из файла leptonica, который я скачал ранее. Как мне это решить? Где я должен положить каталог, include и lib я получил от лептоники, чтобы сделать эту работу?
Есть ли другой способ правильно установить tesseract-ocr и использовать tesserocr на компьютере с Windows? В настоящее время я использую Windows 10 для запуска своего скрипта на python, который использует tesseract-ocr для распознавания некоторых символов на изображении. Я также планирую запустить скрипт на компьютере с Windows 7 позже.
Спасибо за помощь.
Ответы (3)
4 плюса
Используйте Anaconda для установки TesserOCR в среде с именем OCR
- Установите Anaconda для Windows отсюда
Откройте Anaconda Prompt:
conda create -n OCR python=3.6
Для тессеракт 3.5.1 (стабильный):
conda install -c simonflueckiger tesserocr
ИЛИ для tesseract 4.0.0 (экспериментальный):
conda install -c simonflueckiger/label/tesseract-4.0.0-master tesserocr
ИЛИ загрузите файл wheel, соответствующий вашей платформе Windows и установке Python, отсюда и установите его через:
0 плюса
Этот метод отлично работает для меня: используйте Anaconda для установки TesserOCR в среде с именем OCR
-1 плюса
В основном, чтобы установить любой пакет на Windows, перейдите в папку LIBS и выполните команду
Распознавание текста с картинки. Python Tesseract ORC + OpenCV
Сегодня мы с вами поговорим на тему языка Python и рассмотрим пример создания крутого приложения. Наша программа будет способна считывать текст из любой фотографии.
Что сделаем за урок?
Мы с вами рассмотрим пример работы с библиотекой Tesseract ORC и на её основе построим приложение для распознавания текста с фото.
Что забавно, так это возраст библиотеки. Tesseract — является программой, разрабатывавшейся компанией Hewlett-Packard с середины 1980-х по середину 1990-х годов. Затем программа около 10 лет «пролежала на полке» и в августе 2006 года её купила Google. Google открыл исходный код под лицензией Apache 2.0 для продолжения разработки.
На сегодняшний день библиотека является наиболее крутым решением, если вам требуется считать данные из какого-либо фото.
Установка библиотеки
Первое, что необходимо сделать, то это выполнить установку Tesseract ORC. Установка Tesseract удобна на Маке и Линукс. Если вы на Windows, то придется выполнить на одно движение больше.
Если вы на Маке, то скачайте HomeBrew и далее в терминале пропишите brew install tesseract . Если вы на Линукс, тогда в зависимости от операционной системы вам нужно прописать соответствующую команду в терминале.
И если вы на Windows, то вам нужно скачать приложение на ПК. Вам нужно скачать файл Windows Installer . После скачивания выполните установку данной программы.
С самой программой вам никак не придется взаимодействовать, а лишь скопировать её расположение. Обычно оно устанавливается на диск С в Program files. Найдите вашу программу и скопируйте путь к этой папке.
Разработка проекта
Полная разработка проекта показывается в видео. Вы можете просмотреть его ниже:
Начало работы с оптическим распознаванием символов (OCR) с Tesseract в Symfony 3
Давайте представим, что вам нужно оцифровать страницу книги или печатного документа, вы будете использовать сканер для создания изображения реальной страницы. Однако, несмотря на то, что у вас есть права на редактирование содержимого отсканированной книги, вы не можете редактировать его на своем компьютере, потому что это изображение, и вы не можете просто отредактировать изображение, как если бы это был цифровой документ. Да, пользователь может использовать программы, которые создают PDF с возможностью выбора текста, а затем они могут делать то, что хотят, однако, как разработчик, вы можете предложить своему пользователю возможность извлекать текст из изображений с помощью технологии оптического распознавания символов. Чтобы достичь цели преобразования изображений в текст, мы собираемся использовать Tesseract, написанный на C ++, установить его в системе, а затем использовать командную строку с оболочкой PHP.
В этой статье вы узнаете, как извлечь текст из изображения в проекте Symfony с помощью Tesseract.
1. Установите Tesseract в вашей системе
Чтобы использовать API оптического распознавания символов, как упоминалось в статье, мы собираемся использовать Tesseract. Тессеракт является механизмом оптического распознавания символов (OCR) с открытым исходным кодом, доступным по лицензии Apache 2.0. Его можно использовать напрямую с помощью API для извлечения печатного, рукописного или печатного текста из изображений. Он поддерживает широкий спектр языков (которые должны быть установлены). Tesseract поддерживает различные форматы вывода: обычный текст, hocr (html) и pdf.
Процесс установки Tesseract в вашей системе зависит от используемой вами операционной системы:
Windows
Процесс установки очень прост, просто следуйте инструкциям мастера. Однако мы рекомендуем вам установить в настройках непосредственно все языки, которые вам нужны для tesseract (только те, которые вам нужны, в противном случае процесс загрузки займет много времени) и зарегистрировать tesseract в PATH:
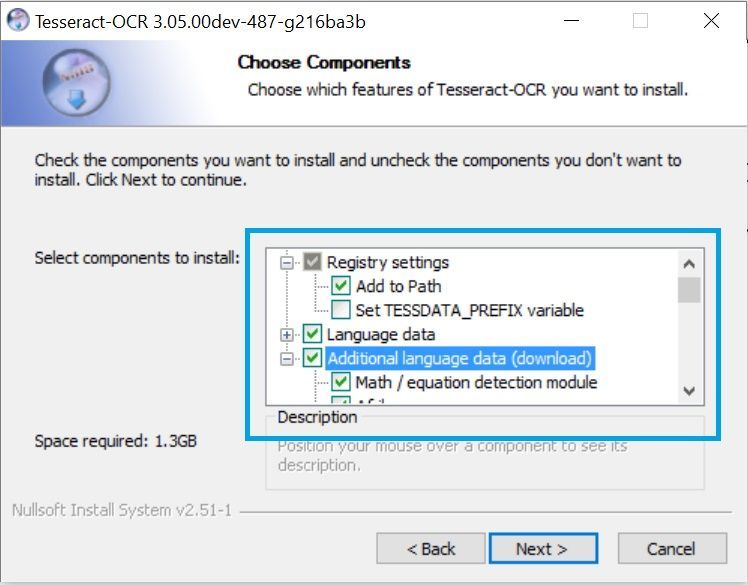
Подождите, пока установка закончится, и вы готовы к работе. Вы можете проверить, правильно ли он был установлен, запустив новое окно командной строки. tesseract -v (это должно вывести установленную версию).
Ubuntu
Установите Tesseract с помощью следующей команды:
Затем установите языки, которые необходимо распознать (например, -deu, -fra, -eng, -spa требуемый английский):
Тогда tesseract должен быть доступен на любом терминале и, следовательно, доступен для наших сценариев PHP позже.
MacOS
Если вы используете Mac OS X, вы можете установить tesseract, используя либо MacPorts или же Homebrew:
MacPorts
Чтобы установить Tesseract, запустите эту команду:
Чтобы установить любые языковые данные, выполните:
Полный список доступных langcodes можно найти на Страница тессеракт MacPorts.
Homebrew
Чтобы установить Tesseract, запустите эту команду:
Если вам нужна дополнительная информация или вашей операционной системы нет в списке, обратитесь к Установка вики репозитория Tesseract в Github здесь.
2. Установите PHP-оболочку Tesseract
Для работы с Tesseract с помощью PHP мы будем использовать самый известный Wrapper of Tesseract, написанный @thiagoalessio. Тессеракт OCR для PHP является полезной и очень простой в использовании оболочкой инструкций командной строки для Tesseract OCR внутри PHP.
Предпочтительный способ установки — через композитор, вы можете выполнить следующую команду прямо в терминале:
Или, если хотите, отредактируйте composer.json файл и добавьте следующую зависимость и выполните затем composer install :
После установки вы сможете использовать Wrapper в ваших контроллерах Symfony.
Замечания: вам нужно установить указанную версию, как в документации библиотеки, метод распознавания текста на изображении с использованием Tesseract $tesseract->run() , В старых версиях вам нужно использовать $tesseract->recognize() вместо.
3. Реализация в контроллере
Использование библиотеки довольно просто и легко понять:
В следующем примере показано, как распознать текст следующего изображения:

Обратите внимание, что файл будет находиться в /your-project/web/text.jpeg :
Перейдите к маршруту, который соответствует действию индекса этого контроллера, и вы увидите, как выводится распознанный текст изображения.
4. Поддержка языков
Как вы знаете, в мире есть другие языки, в которых используются специальные символы, поэтому Tesseract предлагает различные языковые пакеты. Например, если вы попытаетесь распознать следующее изображение без немецкого пакета:

В результате вы получите «грифон». Это совсем не так, это происходит потому, что эти персонажи немецкого языка. Чтобы решить эту проблему, вам нужно добавить немецкий пакет (обозначается как deu ):
Теперь, как результат, вы должны получить «grüßen», как и ожидалось. Вы можете настроить одновременную работу нескольких языков, указав несколько аргументов:
Замечания: чтобы использовать разные языки, вам также понадобятся соответствующие пакеты.
5. Пользовательские параметры
Если вы уже прочитали некоторое содержание документация по использованию Tesseract с командной строкой, Вы знаете, что есть много свойств, которые вы можете изменить. Оболочка PHP tesseract предоставляет несколько методов для наиболее часто используемых опций:
Изменить путь к исполняемому файлу
По разным причинам у вас может не быть доступного tesseract непосредственно в переменной окружения PATH, поэтому выполнение команды с помощью оболочки php « tesseract imagename.jpeg outputbase «не будет работать. Вы можете указать расположение исполняемого файла tesseract с помощью исполняемого метода:
Сегментация страницы
Вы можете установить режим сегментации страницы с помощью ->psm($mode) инструкция, которая инструктирует тессеракт, как интерпретировать данное изображение:
Возможные значения для сегментации страницы:
| Значение | Описание |
| Только ориентация и обнаружение сценариев (OSD). | |
| 1 | Автоматическая сегментация страницы с помощью экранного меню. |
| 2 | Автоматическая сегментация страницы, но без OSD или OCR. |
| 3 | Полностью автоматическая сегментация страниц, но без OSD. (Это значение используется по умолчанию, если ни один не предоставлен) |
| 4 | Предположим, что один столбец текста переменного размера. |
| 5 | Предположим, что один однородный блок текста вертикально выровнен. |
| 6 | Предположим, что один единый блок текста. |
| 7 | Рассматривайте изображение как одну текстовую строку. |
| 8 | Рассматривайте изображение как одно слово. |
| 9 | Рассматривайте изображение как одно слово в кругу. |
| 10 | Относитесь к изображению как к одному персонажу. |
Установите языки для распознавания
Вы можете определить один или несколько языков, которые будут использоваться во время распознавания, используя ->lang($lang1, $lang2) метод. Вы можете получить список все поддерживаемые языки по tesseract в документации здесь:
Используйте слова из списка
Вы можете предоставить список. этот список должен быть простым текстовым файлом, содержащим список слов, которые вы хотите, чтобы tesseract считал обычными словарными словами, например ( mywords.txt ):
И добавьте это с оберткой:
Этот список действительно полезен при работе с контентом, который содержит техническую терминологию.
Белый список персонажей
Вы можете даже ограничить символы, которые распознает tesseract, например, с помощью следующего изображения:
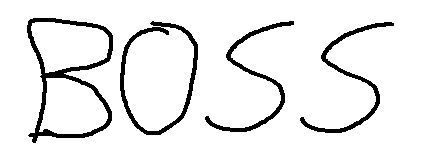
Тессеракт узнает «BOSS» , Это здорово, потому что на картинке кажется, что кто-то написал БОСС, но пользователь (вероятно, ребенок или кто-то с плохой каллиграфией) написал число «8055» ? Вот где белый список пригодится, в этом случае мы можем ограничить символы для распознавания только чисел, используя диапазон от 0 до 9:
Предоставление в результате ожидаемого числа «8055».
Установить значение конфигурации
Tesseract предлагает более 600 настраиваемых свойств (вы можете перечислить их, используя в консоли tesseract —print-parameters ) что вы можете изменить с помощью ->config($propertyName, $value) :
Если вам нужна дополнительная информация о поддерживаемых методах этой оболочки, пожалуйста, посетите официальный репозиторий здесь.



