- Делаем свой десктопный GUI к Apache Kafka или Conduktor для обездоленных
- Используй layout Люк
- Twist таблицы и списка
- Ещё раз о таблицах
- Про окна
- Заключение
- GUI for Apache Kafka
- Overview
- “Kafka Tool” overview and installation.
- Consuming from the topics in “Kafka tool”.
- Creating a new topic in “Kafka tool”.
- “Conduktor” overview and installation.
- Adding of new Kafka cluster in “Conduktor”.
- Consuming from the topics in “Conduktor”
- Creating a new topic in “Conduktor”.
- Conclusion.
- The Ultimate UI Tool for Kafka
- The Ultimate UI Tool for Kafka
- Download
- Offset Explorer 2.2
- [For Kafka version 0.11 and later]
- linux-notes.org
- Установка Kafka в Unix/Linux
- Установка Kafka на Debian/Ubuntu
- Установка Kafka на CentOS/Fedora/RHEL
- Установка Kafka на Mac OS X
- One thought on “ Установка Kafka в Unix/Linux ”
- Добавить комментарий Отменить ответ
Делаем свой десктопный GUI к Apache Kafka или Conduktor для обездоленных
— Я духов вызывать могу из бездны!
— И я могу, и всякий это может. Вопрос лишь, явятся ль они на зов.
Как-то так сложилось, что у нас не так много UI для Apache Kafka. А если хочется именно desktop, то Offset Explorer и упомянутый Conduktor. Первый имеет морально устаревший интерфейс 2000х, а второй не оправдано дорогой, т. к. не использую весь его богатый функционал. Вооружившись Qt и librdkafka, набросал conduktor на минималках.
Используй layout Люк

Сложный выпадающий элемент, имеющий множество состояний. Как съесть слона? По кусочкам маленького размера. Лайауты умеют отслеживать изменение видимости компонентов, и высчитывать размеры на основе implicit size объекта. Более мелки компоненты строятся следующим образом
Сворачивающая левая панель построена на манипуляции с размерами
И для сравнения как сделано в Qt Quick Controls
Twist таблицы и списка
Твист заключается в переключении между двумя режимами отображения
Достигается это наложением таблицы со списком, с последующей синхронизации полосы прокрутки. Делается через StackLayout,фиксации высоты делегата и двух ScrollBar
Делегат для таблицы выглядит следующим образом
Нехитрая схема, которая позволяет настраивать вид каждой колонки. Если не боитесь дополнительных зависимостей, то можете взять DelegateChooser и DelegateChoice.
Ещё раз о таблицах
Изменение количества колонок в таблице и их размер, это привычный функционал и что-то само собой разумеется. Что может пойти не так? TableView позволяет задавать функцию columnWidthProvider , которая позволяет устанавливать ширину столбца. Начиная с Qt 5.13 если вернуть 0, колонка будет скрыта.
Что бы применить изменения, дергаем forceLayout , как это сделано в документации
В моём случае это выглядит так
Осталось за малым, вывести заголовок таблицы и сделать изменение размера столбца. Естественно нашелся компонент под это дело, а именно HorizontalHeaderView
Да, это работает. Беремся за splitter и двигаем влево, вправо. Какие тут подводные камни? Понимающие люди обратили внимание на reuseItems: false . HorizontalHeaderView это view, а в view используется пул элементов(reusing items), что бы сэкономить на создание и удалении. Документация не рекомендует иметь делегаты с состоянием.
На что влияет reuseItems: true в данном примере. Представьте, вы взялись за splitter и растягиваете колонку, которая имеет ширину 300. В какой-то момент view решает пере использовать элемент, возвращает в пул, достаёт от туда, и вставляет в другое место и инициализирует шириной 40. Получаем не очень понятное поведение. В моём случае такое поведение проявляется при вставке/удалении строк таблицы.
Про окна
Заключение
Получился прототип, который можно развивать до полноценного MVP. Из ближайших планов настроить какой-нибудь CI для сборок под Windows и Mac OS X. Весь код доступен на Git Hub.
Передаю пламенный привет Антону Водостоеву из 2ГИС
Источник
GUI for Apache Kafka


Overview
Nowadays Apache Kafka becoming more and more popular in the Big Data world. More than 30% of Fortune 500 companies are already using Kafka. It’s a fast, durable and scalable publish-subscribe messaging system.
In this article I want to take a look at Kafka GUI, that can make a life of Big Data engineer easier.
“Kafka Tool” overview and installation.
First tool of my choice is “Kafka Tool”, sorry for tautology. It’s free for personal use and you can download it from http://www.kafkatool.com/
Also if you use Apache Avro message type it’s very useful to download Avro plugin, that will help to see actual contents of the Avro objects in a JSON format. https://github.com/laymain/kafka-tool-avro
Once you are done, open the “Kafka Tool” installation folder and put the downloaded .jar file to the
Connecting to the Kafka cluster in “Kafka tool”.
Open “Kafka Tool” append and on the left side you will see folder “Clusters”. Right Click on it and choose “Add New Connection” from the drop-down list. It should open this window with cluster’s settings
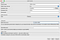
You can name your cluster with any name and add a Bootstrap Server endpoint. In my case, I have Kafka Docker image running on my PC on port 9092 . Click “Add” and now you are connected to your Kafka cluster.
Then specify your schema registry endpoint. By default it’s http://localhost:8081
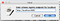
Now in the “Clusters” folder newly created cluster should appear. And you can see a folder “Topics” inside. If you’ll click on it, you’ll see all the topics that exist on your cluster.
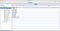
Consuming from the topics in “Kafka tool”.
Click on the topic you’re interested in and then click on the play button on the left.
In the tab “Properties” you can choose Key and message content type. If you added Avro plugin, as was described above you’ll see Avro type as well.
Choose the type used for your messages and go to the “Data” tab.
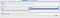
Now you can see all messages that are in the selected topic.
Creating a new topic in “Kafka tool”.
You can create a new topic as well. Just click on the folder “Topics” and then on the green positive sign.

Choose the name, partition count and replica count for your topic. If you need additional configurations — click on the left “Add” button and enter your configuration name and value.
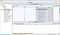
Once you are done click on the right “Add” button and the topic will be created and will appear in your “Topics” folder.
“Conduktor” overview and installation.
“Conduktor” is the second Kafka GUI on my list. You can download it here https://www.conduktor.io
It’s free for now and you don’t need to install anything for schema registry since it’s already built-in.
Let’s open it.

Adding of new Kafka cluster in “Conduktor”.
Click on “Add new cluster”.
Type any cluster name and you Bootstrap Servers endpoints. Then go to “Schema Registry” tab and put in Schema Registry’s URL. It always should start from “http” or “https”
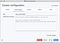
Save your configuration and the newly added cluster should appear on the left. Click on it and you should the window with all the information about your Kafka cluster: brokers, topics, consumers, etc.
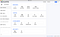
Consuming from the topics in “Conduktor”
Click on the Topics tab and you will see all topics that exist on your cluster.
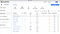
If you want to see the content of the specific topic click on it. In a new window, you can choose your topic’s key and value format and start consuming from it.

Now you can see all your records and their number. If you want to see a specific message just click on it.
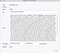
In the opened window you will see all the needed information about your message: name of the topic, partition, offset, key and value of the message, timestamp, and headers if they are present.
Creating a new topic in “Conduktor”.
For creating a new topic in the “Conduktor”. Press the “+CREATE” button on the right.
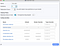
Type in the name of the topic, number of partitions, replication factor. Also, you can override other values if needed. Tap on “Create” and newly added topic should appear in your “Topics” list.
Conclusion.
Both of reviewed tools are free for personal use and runs on all OS. You can connect to your Kafka cluster, see your existing topic. Also, you can see a number of records in each topic, record’s offset, timestamp key, value, and headers. Also, you can create and configure a new topic.
From Kafka tool advantages, you can write your own plugin for it, which can be pretty useful in some cases.
From “Conduktor” advantages, just in my personal opinion, it is more user-friendly and its design is nicer.
Источник
The Ultimate UI Tool for Kafka
Offset Explorer (formerly Kafka Tool) is a GUI application for managing and using Apache Kafka ® clusters. It provides an intuitive UI that allows one to quickly view objects within a Kafka cluster as well as the messages stored in the topics of the cluster. It contains features geared towards both developers and administrators. Some of the key features include
- Quickly view all your Kafka clusters, including their brokers, topics and consumers
- View contents of messages in your partitions and add new messages
- View offsets of the consumers, including Apache Storm Kafka spout consumers
- Show JSON, XML and Avro messages in a pretty-printed format
- Add and drop topics plus other management features
- Save individual messages from your partitions to local hard drive
- Write your own plugins that allow you to view custom data formats
- Offset Explorer runs on Windows, Linux and Mac OS
Offset Explorer is free for personal use only. Any non-personal use, including commercial, educational and non-profit work is not permitted without purchasing a license. Non-personal use is allowed for evaluation purposes for 30 days following the download of Offset Explorer, after which you must purchase a valid license or remove the software.
UI Tool for Apache Kafka
© 2015-2021 DB Solo, LLC. All rights reserved.
Apache Kafka is a trademark of the Apache Software Foundation. Offset Explorer is not produced by or affiliated with the Apache Software Foundation.
Источник
The Ultimate UI Tool for Kafka
Download
To download the Offset Explorer (formerly Kafka Tool) for your operating system, use the links below. All versions of Offset Explorer come with a bundled JRE with the exception of the Linux version. For Linux, you must have Java 8 installed on your operating system before using Offset Explorer. After downloading, refer to the Documentation to configure Offset Explorer correctly. View change history to see recent updates to Offset Explorer.
Before clicking on the download button below, carefully read the terms of the license agreement. By clicking and downloading the software you are consenting to be bound by the license agreement. Do not click on download unless you agree to all terms of the license agreement.
Offset Explorer is free for personal use only.
Offset Explorer supports Apache Kafka ® version 0.8.1 and above.
Offset Explorer 2.2
[For Kafka version 0.11 and later]
| Platform | Size | ||
| Windows 32-Bit | 35 MB | Download |  |
| Windows 64-Bit | 34 MB | Download | |
| macOS | 55 MB | Download |  |
| Linux | 16 MB | Download |  |
UI Tool for Apache Kafka
© 2015-2021 DB Solo, LLC. All rights reserved.
Apache Kafka is a trademark of the Apache Software Foundation. Offset Explorer is not produced by or affiliated with the Apache Software Foundation.
Источник
linux-notes.org

Kafka (Apache Kafka) — Является популярным распределенным брокером сообщений, разработанным для эффективного управления большими объемами данных в режиме реального времени. Кластер Kafka не только хорошо масштабируется (настраивается отказоустойчивость), но также имеет гораздо более высокую пропускную способность по сравнению с другими подобными технологиями, — такими как ActiveMQ и RabbitMQ. Хотя он обычно используется в качестве системы обмена сообщениями pub/sub, многие организации также используют его для агрегирования логов, поскольку он обеспечивает постоянное хранение опубликованных сообщений.
Установка Kafka в Unix/Linux
В данной статье, я расскажу как можно установить kafka на различные Unix/Linux ОС.
Установка Kafka на Debian/Ubuntu
Создаем kafka пользователя
Поскольку Kafka может обрабатывать запросы через сеть, вам следует создать для нее выделенного пользователя.
Примечание. После настройки Apache Kafka рекомендуется создать другого пользователя без полномочий root для выполнения других задач на этом сервере.
В качестве пользователя root создайте пользователя с именем kafka с помощью команды:
Назначим пароль для созданного пользователя:
После этого, созданного юзера вносим в группу sudo( чтобы иметь привилегии, необходимые для установки зависимостей Кафки). Это можно сделать с помощью команды:
Теперь ваш пользователь готов. Залогинимся в него:
Устанавка Java
Если не знаете как выполнить установку Java, JRE — вот мануалы:
Устанавка ZooKeeper
Если не знаете как выполнить установку ZooKeeper — вот мануал:
По умолчанию он будет прослушивать 2181 порт. Чтобы убедиться, что он работает, подключитесь к нему через Telnet:
Вводим слово и нажимаем «enter»:
Если все работает, то должны получить:
После чего, сеанс сам завершиться.
Устанавка Kafka
Теперь, когда установлены Java и ZooKeeper, настало время загрузить и распаковать Kafka.
PS: Вышла новая версия ПО и ее можно скачать (на момент обновления статьи):
PS: Опция «—strip 1» дает возможность не создавать папку, а распаковать все содержимое в текущее место.
Переименуем папку для удобства использования:
Переходим к настройке.
Настройка Kafka
По умолчанию, Kafka не позволяет удалять темы. Чтобы иметь возможность удалять темы, добавьте следующую строку в конец файла или, найдите и расскоментируйте данную строку (у меня это 24-я строка):
Сохраняем и закрываем файл.
Запускаем скрипт kafka-server-start.sh, используя nohup, чтобы запустить сервер Kafka (также называемый брокер Kafka) в качестве фонового процесса, который не зависит от сеанса оболочки:
Подождите несколько секунд и сервер запустится. Чтобы быть уверенным что сервер успешно запущен, проверим kafka.log лог-файл:
Теперь у вас есть сервер Kafka, который прослушивает 9092 порт.
Тестирование Kafka
Давайте теперь опубликуем и используем сообщение «Hello, man», чтобы убедиться, что сервер Kafka работает правильно.
Для публикации сообщений вы должны создать «продюсера» для Kafka. Вы можете легко создать это прямо из командной строки, используя скрипт kafka-console-producer.sh:
Поскольку темы не существует, Кафка создаст ее автоматически.
Чтобы потреблять сообщения, вы можете создать потребителя Kafka, используя kafka-console-consumer.sh скрипт.
Следующая команда использует сообщения из опубликованной темы. Обратите внимание на использование флага -from-beginning, который присутствует. Данный параметр покажет сообщение до запуска самого потребителя:
Т.к я запускал несколько раз kafka-console-producer.sh, то получил следующее:
Как видим, что все работает отлично!
Установка KafkaT
KafkaT — это небольшой инструмент от Airbnb, который упрощает просмотр информации о вашем кластере Kafka, а также выполняет несколько административных задач из командной строки. Поскольку он написанный на Ruby, то для его использования вам понадобится Ruby. Вам также понадобится пакет build-essential. Установите все необходимое с помощью следующей команды:
И сейчас, выполняем установку KafkaT:
Используйте текстовый редактор для создания нового файла:
Это файл конфигурации, который KafkaT использует для определения каталогов установки и папки, где находятся логи от Kafka. Соответственно, добавьте следующие строки:
Теперь вы готовы использовать KafkaT. Для начала рассмотрим, как вы будете использовать его для просмотра деталей всех разделов Kafka:
Вы должны увидеть следующий результат:
PS: Можно построить multi-broker кластер. Кроме того, вы должны внести следующие изменения в файл server.properties в каждом из них:
- Значение свойства broker.id должно быть изменено таким образом, чтобы оно было уникальным во всем кластерах
- Значение свойства zookeeper.connect должно быть изменено таким образом, чтобы все узлы указывали на тот же экземпляр ZooKeeper
- Если вы хотите иметь несколько экземпляров ZooKeeper для вашего кластера, значение свойства zookeeper.connect на каждом узле должно быть идентичным, разделенным запятыми строкой, в которой перечислены IP-адреса и номера портов для всех экземпляров ZooKeeper.
Теперь, когда все установки сделаны, вы можете снять права администратора (суперпользователя) kafka. Для начала выйдите с оболочки или используйте другого пользователя чтобы сделать следующее действия. Удаляем пользователя kafka из группы sudo:
Чтобы еще больше повысить безопасность вашего сервера Kafka, заблокируйте пароль пользователя kafka с помощью команды passwd. Это гарантирует, что никто не сможет напрямую войти через данного пользователя:
На данный момент только root или пользователь sudo могут войти в систему под именем kafka, введя следующую команду:
В будущем, если вы хотите разблокировать его, используйте passwd с ключом «-u»:
Установка Kafka на CentOS/Fedora/RHEL
Создаем пользователя
Поскольку Kafka может обрабатывать запросы через сеть, вам следует создать для нее выделенного пользователя.
Примечание. После настройки Apache Kafka рекомендуется создать другого пользователя без полномочий root для выполнения других задач на этом сервере.
В качестве пользователя root создайте пользователя с именем kafka с помощью команды:
Назначим пароль для созданного пользователя:
После этого, созданного юзера вносим в группу sudo( чтобы иметь привилегии, необходимые для установки зависимостей Кафки). Это можно сделать с помощью команды:
Теперь ваш пользователь готов. Залогинимся в него:
Устанавка Java
Если не знаете как выполнить установку Java, JRE — вот мануалы:
Устанавка ZooKeeper
Если не знаете как выполнить установку ZooKeeper — вот мануал:
По умолчанию он будет прослушивать 2181 порт. Чтобы убедиться, что он работает, подключитесь к нему через Telnet:
Вводим слово и нажимаем «enter»:
Если все работает, то должны получить:
После чего, сеанс сам завершиться.
Устанавка Kafka
Теперь, когда установлены Java и ZooKeeper, настало время загрузить и распаковать Kafka.
PS: Вышла новая версия ПО и ее можно скачать (на момент обновления статьи):
PS: Опция «—strip 1» дает возможность не создавать папку, а распаковать все содержимое в текущее место.
Переименуем папку для удобства использования:
Переходим к настройке.
Настройка Kafka
По умолчанию, Kafka не позволяет удалять темы. Чтобы иметь возможность удалять темы, добавьте следующую строку в конец файла или, найдите и расскоментируйте данную строку (у меня это 24-я строка):
Сохраняем и закрываем файл.
Запускаем скрипт kafka-server-start.sh, используя nohup, чтобы запустить сервер Kafka (также называемый брокер Kafka) в качестве фонового процесса, который не зависит от сеанса оболочки:
Подождите несколько секунд и сервер запустится. Чтобы быть уверенным что сервер успешно запущен, проверим kafka.log лог-файл:
Теперь у вас есть сервер Kafka, который прослушивает 9092 порт.
Тестирование Kafka
Давайте теперь опубликуем и используем сообщение «Hello, man», чтобы убедиться, что сервер Kafka работает правильно.
Для публикации сообщений вы должны создать «продюсера» для Kafka. Вы можете легко создать это прямо из командной строки, используя скрипт kafka-console-producer.sh:
Поскольку темы не существует, Кафка создаст ее автоматически.
Чтобы потреблять сообщения, вы можете создать потребителя Kafka, используя kafka-console-consumer.sh скрипт.
Следующая команда использует сообщения из опубликованной темы. Обратите внимание на использование флага -from-beginning, который присутствует. Данный параметр покажет сообщение до запуска самого потребителя:
Т.к я запускал несколько раз kafka-console-producer.sh, то получил следующее:
Как видим, что все работает отлично!
Установка KafkaT
KafkaT — это небольшой инструмент от Airbnb, который упрощает просмотр информации о вашем кластере Kafka, а также выполняет несколько административных задач из командной строки. Поскольку он написанный на Ruby, то для его использования вам понадобится Ruby. Вам также понадобится необходимые пакеты. Установите все необходимое с помощью следующей команды:
И сейчас, выполняем установку KafkaT:
Используйте текстовый редактор для создания нового файла:
Это файл конфигурации, который KafkaT использует для определения каталогов установки и папки, где находятся логи от Kafka. Соответственно, добавьте следующие строки:
PS: Директория «/tmp/kafka-logs» должна быть созданной и иметь чтение-запись!
Теперь вы готовы использовать KafkaT. Для начала рассмотрим, как вы будете использовать его для просмотра деталей всех разделов Kafka:
Вы должны увидеть следующий результат:
PS: Можно построить multi-broker кластер. Кроме того, вы должны внести следующие изменения в файл server.properties в каждом из них:
- Значение свойства broker.id должно быть изменено таким образом, чтобы оно было уникальным во всем кластерах
- Значение свойства zookeeper.connect должно быть изменено таким образом, чтобы все узлы указывали на тот же экземпляр ZooKeeper
- Если вы хотите иметь несколько экземпляров ZooKeeper для вашего кластера, значение свойства zookeeper.connect на каждом узле должно быть идентичным, разделенным запятыми строкой, в которой перечислены IP-адреса и номера портов для всех экземпляров ZooKeeper.
Теперь, когда все установки сделаны, вы можете снять права администратора (суперпользователя) kafka. Для начала выйдите с оболочки или используйте другого пользователя чтобы сделать следующее действия. Удаляем пользователя kafka из группы sudo:
Чтобы еще больше повысить безопасность вашего сервера Kafka, заблокируйте пароль пользователя kafka с помощью команды passwd. Это гарантирует, что никто не сможет напрямую войти через данного пользователя:
На данный момент только root или пользователь sudo могут войти в систему под именем kafka, введя следующую команду:
В будущем, если вы хотите разблокировать его, используйте passwd с ключом «-u»:
Установка Kafka на Mac OS X
Для поиска используем команду:
И, устанавливаем нужные пакеты. Я не использовал kafka на Mac OS X. По этому, не могу описать подробную инструкцию.
Статья «Установка Kafka в Unix/Linux» завершена. В следующих статьях, я планировал собрать кластер с Kafka. Но на все времени нет, напишу когда будет время 😉
One thought on “ Установка Kafka в Unix/Linux ”
Обновите пожалуйста (при установке) команду:
PS: Tсли я не ошибаюсь то вышла новая версия.
спасибо )
Добавить комментарий Отменить ответ
Этот сайт использует Akismet для борьбы со спамом. Узнайте, как обрабатываются ваши данные комментариев.
Источник



