- How to Count lines in a file in UNIX/Linux
- Using “wc -l”
- Using awk
- Using sed
- Using grep
- Some more commands
- How to Count the Lines of a File in Linux
- The Linux Command to Count Lines
- Counting the Occurrences of a Pattern in a File
- Counting the Number of Files with a Specific Extension
- Output of the wc Command Without Flags
- Count the Lines in a Zipped File in Linux
- Count Empty Lines in a File
- Conclusion
- Read and count lines of large files in 2019 Linux
- Count number of lines in one large file
- Count number of lines in multiple files
- Search huge files by keyword
- Split huge files
- Read big files
- Working with JSON files and JQ
- For JL JSON lines files
- Modify large files
- Using python for huge files
- Count number of lines with python
- Python read first N lines of huge file
- how to count characters, words and lines in a text file in linux
- Counting Lines
- Counting Words
- Counting Characters
How to Count lines in a file in UNIX/Linux
Question: I have a file on my Linux system having a lot of lines. How do I count the total number of lines in the file?
Using “wc -l”
There are several ways to count lines in a file. But one of the easiest and widely used way is to use “wc -l”. The wc utility displays the number of lines, words, and bytes contained in each input file, or standard input (if no file is specified) to the standard output.
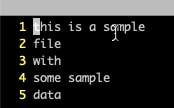
So consider the file shown below:
1. The “wc -l” command when run on this file, outputs the line count along with the filename.
2. To omit the filename from the result, use:
3. You can always provide the command output to the wc command using pipe. For example:
You can have any command here instead of cat. Output from any command can be piped to wc command to count the lines in the output.
Using awk
If you must want to use awk to find the line count, use the below awk command:
Using sed
Use the below sed command syntax to find line count using GNU sed:
Using grep
Our good old friend «grep» can also be used to count the number of lines in a file. These examples are just to let you know that there are multiple ways to count the lines without using «wc -l». But if asked I will always use «wc -l» instead of these options as it is way too easy to remember.
With GNU grep, you can use the below grep syntax:
Here is another version of grep command to find line count.
Some more commands
Along with the above commands, its good to know some rarely used commands to find the line count in a file.
1. Use the nl command (line numbering filter) to get each line numbered. The syntax for the command is:
Not so direct way to get line count. But you can use awk or sed to get the count from last line. For example:
2. You can also use vi and vim with the command «:set number» to set the number on each line as shown below. If the file is very big, you can use «Shift+G» to go to the last line and get the line count.
3. Use the cat command with -n switch to get each line numbered. Again, here you can get the line count from the last line.
4. You can also use perl one lines to find line count:
Источник
How to Count the Lines of a File in Linux
Knowing how to count the lines of a file or from the output of a command is a must in Linux.
How to count the lines in a file with Linux?
Linux provides the wc command that allows to count lines, words and bytes in a file or from the standard input. It can be very useful in many circumstances, some examples are: getting the number of errors in a log file or analysing the output coming from other Linux commands.
How many errors can you see in the logs of your application? How many unique users have used your application today?
These are just two examples of scenarios in which you need to be able to count the lines of a file.
So, how can you count the lines of a file using Linux?
Let’s find out how!
The Linux Command to Count Lines
The most used command to do that is the wc (word count) command.
Let’s say we want to count the lines in the /var/log/messages file.
This file contains global system messages and it’s very useful to troubleshoot issues with your Linux system.
To count the number of lines we will use the following syntax:
The -l flag is used to get the number of lines, the reason for this flag is that the wc command allows to do a lot more than just counting lines…
As you can see in this case the number of lines in the file is 2094.
Counting the Occurrences of a Pattern in a File
Now, let’s say we want to count the number of errors in the same file.
We can use the grep command followed by the wc command using the pipe.
The pipe is used to send the standard output of the command before the pipe to the standard input of the command after the pipe.
Here the output of the grep command becomes the input of the wc command.
The output of the grep command without pipe would be:
So we have two lines that contain the string ERROR.
If we use the pipe followed by the wc command we won’t see anymore the lines but just the number of lines:
I want to know how many times the Apache web server on my Linux machine has been restarted.
First we look for all the lines in /var/log/messages containing the word ‘Apache’:
We use the -i flag in the grep command to ignore the case when looking for a match, so our grep would match lines containing the text ‘apache’ or ‘Apache’.
We can see that Apache logs the following message when it starts successfully:
So our grep command becomes:
Two grep commands?
Yes, you can use the pipe to concatenate multiple commands, even if they are the same command, like in this case.
And finally we can add wc to get the total count:
So, our Apache has been restarted successfully 13 times.
You can also get the same result of the command above using the -c flag for the grep command.
The command above becomes:
The wc command can be also used to count the number of lines in multiple files:
Counting the Number of Files with a Specific Extension
If we want to count the number of files with extension .log inside the /var/log/ directory, we can use:
The wildcard *.log is used to match all the files with extension .log.
What do we do if we want to get the actual number of files?
We use once again the pipe and the wc command:
The power of wc together with other Linux commands is endless!
Output of the wc Command Without Flags
Let’s execute the previous command:
But this time without passing any flags to the wc command.
We see three numbers in the output…what do they represent?
They are the total numbers of lines, words and bytes.
From the previous example we can already see that 5 is the number of lines. Let’s confirm that 45 and 321 are the number of words and bytes.
The -m flag for the wc command allows to get just the number of words:
And the -c flag to get the number of bytes:
Count the Lines in a Zipped File in Linux
So far we have seen how to count the lines of files in Linux.
What if I want to count the number of lines in a zipped file?
First of all we can use the zcat command to print the content of a zipped file.
Let’s say we have a zipped file called app_logs.gz, I can use the following command to see its content:
To see the number of lines in this file I can simply use the pipe followed by the wc command in the same way we have seen in the previous sections:
So, no need to use the gunzip command to decompress the file before counting its lines!
This article gives more details about compressing files in Linux.
Count Empty Lines in a File
I have showed you few things you can do with grep, wc and other commands.
And I want to show you something else that can be useful.
Let’s say I want to count the number of empty lines in a file.
The syntax is similar to other commands we have seen so far with a difference in the pattern matched via the grep command to identify empty lines.
The pattern to identify an empty line with grep is:
This represents an empty line because ^ is the beginning of the line, $ is the end of the line and there’s nothing between them.
So taking as an example a file called app_error.log, the full command to identify the number of empty lines in this file is:
That as we have seen before can also be written using the -c flag for grep:
If I want to print the number of lines that are not empty I can simply add the -v flag for the grep command that inverts the sense of the matching.
It basically selects the lines that don’t match the pattern specified:
Conclusion
There are many ways you can use the wc command on your Linux system.
You have learned how you can use it to count lines in a file…
How to mix it with the grep command using the pipe, to count the occurrences of a specific pattern in a normal file and in a zipped one…
And how to get the number of files in a directory with a specific extension.
And there are so many other ways in which you can use it.
Источник
Read and count lines of large files in 2019 Linux

Reading and counting lines of huge files could be easy or nightmare. It depends on your knowledge and tools. In this article you can learn how to ease your life with huge files by using next tools:
- sed , a stream editor
- split — split a file into pieces
- grep — prints lines that contain a match
- cat — concatenate files and print
- JQ — is like sed for JSON data
- python fileinput
Topics in the article:
Count number of lines in one large file
You can count number of lines of huge files ( > 30 GB) with simple commands like(for Linux like systems) very fast:
-l, —lines — print the newline counts
Count number of lines in multiple files
To count number of lines in multiple files you can pipe several commands in Linux. For example cat and wc :
or for csv files:
Search huge files by keyword
Sometimes you need to read and return the files which has a given keyword in the file content. In this example we list all files where a keyword is present in the file:
Counting number of files where the keyword is found:
-R —dereference-recursive — For each directory operand, read and process all files in that directory, recursively, following all symbolic links.
-l —files-with-matches — Suppress normal output; instead print the name of each input file from which output would normally have been printed. The scanning of each file stops on the first match. (-l is specified by POSIX.)
Search and return the lines where a given keyword is found. Searching all JSON line files in the current folder and search for keyword id in each file:
Another solution for search in multiple large files is sed :
-n, —quiet, —silent — suppress automatic printing of pattern space
-e script, —expression=script — add the script to the commands to be execute
Split huge files
If you need to split huge file into smaller chunks then you can use command split . You can use the count from the previous section and divide the file based on the number of lines. For example diving the csv file in 5,000,000 lines per chunk:
You can also split the file by size. For example diving the same file in 1GB chunks:
the equivalent for MB:
You can see the second name — my_split.csv which is optional and can be used for naming pattern of the new files.
Split can works and for JSON line files:
-l, —lines=NUMBER — put NUMBER lines/records per output file
-b, —bytes=SIZE — put SIZE bytes per output file
Read big files
You can read YY number of lines starting from XX position with a command like:
tail -n +XX normal_json.json | head -nYY
Working with JSON files and JQ
JQ is advertised as:
jq is like sed for JSON data — you can use it to slice and filter and map and transform structured data with the same ease that sed , awk , grep and friends let you
It can be used for efficient work with huge JSON files(ends on .json):
JQ read XX-YY lines from JSON file:
Search for items which has given value in JSON array file. Finally return the whole record:
Search by key and return only one value:
For JL JSON lines files
Reading first lines of large JSON lines file. This files ends usually on .jl :
Searching by key in huge .jl files can be done by:
Modify large files
If you need to correct large file you can use command like sed. For example simple replacement: id -> pid :
Using python for huge files
Reading number of lines in a file by using python can be done in many ways. Here you can find some typical examples like:
Count number of lines with python
Note: This might return wrong value for json file. In order to get the correct value for JSON files you can change it to:
Python read first N lines of huge file
this is the modification for line from XX to YY
Источник
how to count characters, words and lines in a text file in linux
Many modern day graphical text editors have the functionality to count characters, words and lines of the text file that it is being edited. But sometimes you would want to see the statistics of the text file from the command line. It is also useful when you want to see and compare these for several different files.
The most common command used in Linux for this purpose is wc. This command can print out byte, character, word and line counts of a text file or the standard input. The command is simple with just a few command line options.
Counting Lines
To count the number of lines in a text file, where the lines are separated by the end of line (EOF) character, use the wc command with the –lines or -l option. The EOF character is the default line separator used in text files.
The –lines (or -l) option prints out the newline count which is equal to the number of lines in the file. The in the above example refers to the path to the text file that you want to analyze.
Remember that the blank (or empty) lines in the file will count as a line as well. If you find a discrepancy between what you expected and what is printed out, then it could be a reason.
Counting Words
In order to count the words in the text file across all lines, you can use the –words (or -w) option of the wc command. The words in the text files are considered to be separated by white spaces, which are known word separators such as spaces, tabs, line breaks etc.
The wc command by default uses the standard white spaces as delimiters or separators. If you wish to use another character as a delimiter, then you will need to pipe the content of the text file through the tr command before sending to the wc.
For example, Let’s say you have a csv (comma separated file) as input and you want to get a word count on that file. Being a CSV, the appropriate word delimiter is the comma. So, you will need to consider the comma (,) as a word delimiter in addition to the white space. The example below shows you how you can do this by using tr and wc.
bash$ cat | tr «,» » » | wc -w
You can use any character as a custom delimiter using the above method. You just need to substitute the comma (,) in the above example with the desired character.
Counting Characters
You can again use the wc command to count the number of characters in a text file. The option –chars (or -m) can be used to print out the character count.
You may also use the –bytes (or -c) option to get the same information. In almost all scenarios, the -m and -c option prints out the same count unless you have double bytes characters in the text file or something similar.
The wc command will count the spaces or blanks in the file as a character. You can omit the space from being counted by using the tr command to substitute and delete the spaces from the text file. So, to count the characters without the spaces you can use
bash$ cat |tr -d [:blank:] | wc -m
This will delete all the horizontal spaces in the file and count the rest of the characters in the file.
If you like to count the occurrence of a single character rather than all the characters in the text file, then you will need to use fgrep to print just the desired character out and then pipe it to the wc command.
bash$ fgrep -o | wc -l
here, denotes the character that you want to count. So, as an example if you want to count how many occurrences of character t is in the text file sample.txt then you can use the example below.
bash$ fgrep -o t sample.txt | wc -l
Using various commands such as tr, fgrep, grep, cut and awk you can convert pretty much filter any content to just the desired text that you want to analyze and then run the wc command on the result to count characters, words and lines either separately or together.
Just as with any other Linux command, you can use multiple files as argument and the wc command will print out the word or line count for all of them individually and also provide a total for all files combined. You can also use regular expressions to match just the files you need. This can be a good tool to compare the content in several text files.
Источник



