- Информация об оперативной памяти в Linux. Свободная, занятая и тип памяти
- Свободная и занятая оперативная память
- Команда free
- Команда vmstat
- Команда top
- Команда htop
- Файл /proc/meminfo
- Тип памяти и частота
- Заключение
- Что такое оперативная память linux
- Какая бывает память?
- Физическая и виртуальная
- Файловая и анонимная
- Вытесняемая и нет
- Методы управления подсистемой памяти
- mlock
- OOM killer
- cgroups
- Операции с памятью
- Итого
Информация об оперативной памяти в Linux. Свободная, занятая и тип памяти

В этой статье мы рассмотрим, как получить информацию об оперативной памяти (RAM) в Linux.
Мы воспользуемся утилитами командной строки доступными для большинства Linux дистрибутивов.
Свободная и занятая оперативная память
Для получения информации о количестве свободной и занятой оперативной памяти в Linux можно использовать различные утилиты и команды. Рассмотрим несколько распространенных способов.
Команда free
Команда free очень простая, она выводит информацию о общем количестве оперативной памяти, о количестве занятой и свободной памяти, а также об использовании файла подкачки.
По умолчанию объем памяти выводится в килобайтах. Используя опции, можно выводить объем памяти в других форматах. Некоторые опции:
- -m — в мегабайтах
- -g — в гигабайтах
- -h — автоматически определить формат
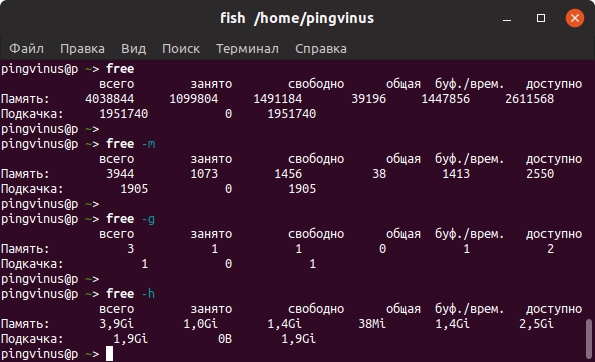
Команда vmstat
Команда vmstat выводит различную статистику по использованию памяти. Используя ключ -s можно вывести подробную статистику в табличном виде.
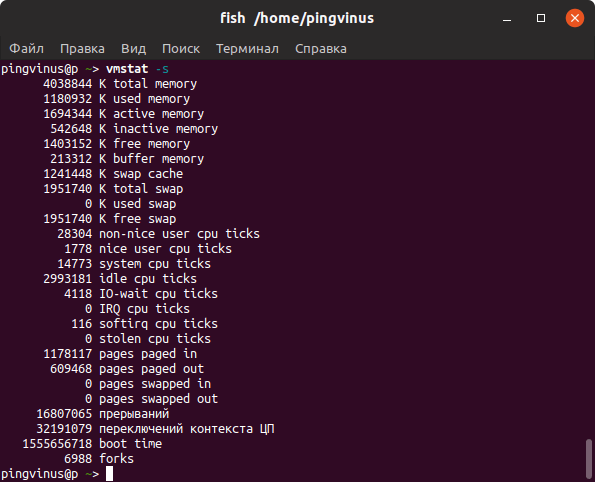
Команда top
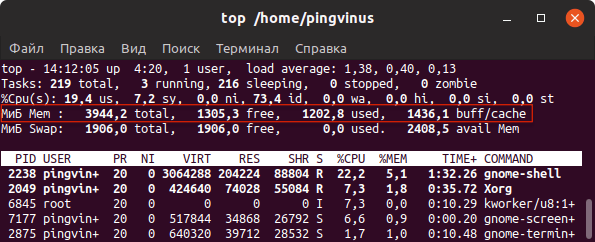
top — это утилита командной строки, которая используется для мониторинга процессов и используемых ресурсов компьютера.
Запуск утилиты top :
В заголовке выводится информация об использованной оперативной памяти.
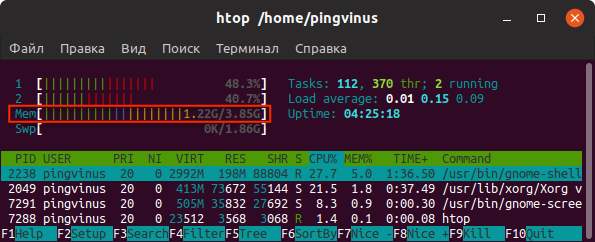
Команда htop
Утилита htop, также как и top, используется для мониторинга ресурсов и процессов.
Для установки утилиты htop в Ubuntu Linux (Linux Mint и других Ubuntu/Debian-дистрибутивах) выполните команду:
Запуск утилиты htop :
Файл /proc/meminfo
Описанные выше команды, в качестве источника информации используют системные файлы из файлов, хранящихся в виртуальной файловой системе /proc . В файле /proc/meminfo содержится информация об использовании памяти. Выведем содержимое файла /proc/meminfo :
Тип памяти и частота
Рассмотрим, как получить информацию об установленных в компьютер модулях оперативной памяти. Воспользуемся командной dmidecode
Используем следующую команду:
В выводе команды будет информация о слотах оперативной памяти. Для каждого слота отображается установленный модуль оперативной памяти, его тип (поле Type ), размер (поле Size ), скорость/частота (поле Speed ) и другая информация.
В зависимости от системы и оборудования не всегда удается получить все данные, поэтому некоторые поля могут быть пустыми или иметь надписи Not provided/Unknown.
Заключение
Мы рассмотрели различные способы для просмотра информации о доступной и занятой оперативной памяти, а также показали, как вывести информацию об установленных модулях оперативной памяти.
Для отслеживания использования ресурсов компьютера существует множество графических программ. Найти их можно в нашем каталоге программ для Linux в разделе Система/Мониторинг.
Источник
Что такое оперативная память linux

Подсистема работы с оперативной памятью в Linux — достаточно многогранная конструкция. Чтобы разобраться в её деталях нужно целенаправленно погрузиться в тему, с обязательным чтением исходников ядра, но это нужно не каждому. Для разработки и эксплуатации серверного программного обеспечения важно иметь хотябы базовое предстваление о том, как она работает, но меня не перестает удивлять насколько небольшая доля людей им обладает. В этом посте я постараюсь кратко пробежаться по основным вещам, без понимания которых на мой взгляд очень легко натворить глупостей.
Какая бывает память?
Физическая и виртуальная
Начнем издалека. В спецификации любого компьютера и в частности сервера непременно числится надпись «N гигабайт оперативной памяти» — именно столько в его распоряжении находится физической памяти.
Задача распределения доступных ресурсов между исполняемым программным обеспечением, в том числе и физической памяти, лежит на плечах операционной системы, в нашем случае Linux. Для обеспечения иллюзии полной независимости, она предоставляет каждой из программ свое независимоевиртуальное адресное пространство и низкоуровневый интерфейс работы с ним. Это избавляет их от необходимости знать друг о друге, размере доступной физической памяти и текущей её занятости. Адреса в виртуальном пространстве процессов называют логическими.
Для отслеживания соответствия между физической и виртуальной памятью ядро Linux использует иерархический набор структур данных в своей служебной области физической памяти (только оно работает с ней напрямую), а также специализированные аппаратные контуры, которые в совокупности называют MMU .
Следить за каждым байтом памяти в отдельности было бы накладно, по-этому ядро оперирует достаточно большими блоками памяти — страницами, типовой размер которых составляет 4 килобайта.
Также стоит упомянуть, что на аппаратном уровне как правило есть поддержка дополнительного уровня абстракции в виде «сегментов» оперативной памяти, с помощью которых можно разделять программы на части. В отличии от других операционных систем, в Linux она практически не используется — логический адрес всегда совпадает с линейным (адресом внутри сегмента, которые сконфигурированы фиксированным образом).
Файловая и анонимная
У приложений существует много способов выделить себе память для тех или иных нужд. Высокоуровневые языки программирования и библиотеки часто прячут от разработчиков какой из них в реальности использовался и другие детали (хотя их всегда можно «раскусить» с помощью strace ). Если углубляться в особенности каждого доступного варианта, эта статья быстро бы превратилась в книгу. Вместо этого предлагаю разделить их на две, на мой взгляд, крайне важные группы по тому, какую память они выделяют:
- Файловой памяти однозначно соответствует какой-либо файл или его часть в файловой системе. Первым делом в ней как правило находится исполняемый код самой программы. Для прикладных задач можно запросить отображение файла в виртуальное адресное пространство процесса с помощью системного вызова mmap — после чего с ним можно работать как с любой другой областью памяти без явного чтения/записи, что будет при этом происходить с данными в файловой системе и что будут видеть другие процессы «отобразившие» этот же файл зависит от настроек.
- Любую другую выделенную память называют анонимной, так как ей не соответствует никакой файл, которые как известно именованы. Сюда попадают как переменные на стеке, так и области, выделенные с помощью функций вроде malloc (к слову, за сценой для выделения больших блоков памяти они обычно тоже используют mmap с особым набором настроек, а для всего остального — brk/sbrk или выдают ранее освобожденную память).
На первый взгляд отличия не выглядят чем-то особенным, но тот факт, что области файловой памяти именованы, позволяет операционной системе экономить физическую память, порой очень значительно, сопоставляя виртуальные адреса нескольких процессов, работающих с одним и тем же файлом, одной физической странице в памяти. Это работает прозрачно, начиная от кода запущенных нескольких копий приложений, заканчивая специально сконструированными под эту оптимизацию систем.
Вытесняемая и нет
Суммарный объем используемой виртуальной памяти всех программ запросто может превышать объем доступной физической памяти. При этом в каждый конкретный момент времени приложениями может использоваться лишь небольшое подмножество хранимых по виртуальным адресам данных. Это означает, что операционная система может откладывать не используемые в данный момент данные из оперативной памяти на жесткий диск («вытесняя»» их из памяти), а затем при попытке к этим данным обратиться — скопировать обратно в физическую оперативную память. Этот механизм официально называется major page fault, но под просто page fault как правило подразумевают тоже её, так как minor page fault мало кого заботит (отличие в том, что в случае minor ядру удается найти запрашиваемые данные уже загруженными в память с какой-то другой целью и обращения к диску в итоге не происходит).
На время восстановления запрашиваемых приложением данных его выполнение прерывается и управление передается ядру для выполнения соответствующей процедуры. Время, которое потребуется, чтобы приложение смогло продолжить свою работу, напрямую зависит от типа используемого жесткого диска:
- Прочитать 4Кб данных с обычного серверного жесткого диска 7200rpm занимает порядка 10 мс, при хорошем стечении обстоятельств чуть меньше.
- Если вытесненных страниц оказывается много, запросто могут набегать заметные доли секунды (как условным пользователям, так и на внутренних приборах, в зависимости от задачи).
- Особенно опасны циклические pagefaults, когда есть две или более регулярно используемые области памяти, которые вместе не помещаются в физическую память, по-этому бесконечно вытесняют друг друга туда-обратно.
- При этом диск вынужден делать честный seek, что само по себе тоже может быть не кстати. Например, если с этим же диском работает какая-либо база данных.
- Если используется SSD , то ситуация несколько более радужная — из-за отсутствия механического движения аналогичная операция занимает примерно на порядок меньше, около 1 мс или её доли, в зависимости от типа и конкретной модели диска. Но годы идут, а SSD так и остаются нишевым компромиссным продуктом по цене-объему.
- А теперь для сравнения: если бы страница уже была в памяти, то при обращении к ней счет шел бы на сотни наносекунд. Это почти на 4 порядка быстрее, чем pagefault, даже на SSD .
Стоит отметить, что с точки зрения приложения всё это прозрачно и является внешним воздействием, то есть может происходить в самый не подходящий, с точки зрения решаемой им задачи, момент.
Думаю понятно, что приложения, которым важна высокая производительность и стабильное время отклика, должны избегать pagefault’ов всеми доступными методами, к ним и перейдем.
Методы управления подсистемой памяти
С файловой памятью всё просто: если данные в ней не менялись, то для её вытеснения делать особо ничего не нужно — просто перетираешь, а затем всегда можно восстановить из файловой системы.
С анонимной памятью такой трюк не работает: ей не соответствует никакой файл, по-этому чтобы данные не пропали безвозвратно, их нужно положить куда-то ещё. Для этого можно использовать так называемый «swap» раздел или файл. Можно, но на практике не нужно. Если swap выключен, то анонимная память становится невытесняемой, что делает время обращения к ней предсказуемым.
Может показаться минусом выключенного swap, что, например, если у приложения утекает память, то оно будет гарантированно зря держать физическую память (утекшая не сможет быть вытеснена). Но на подобные вещи скорее стоит смотреть с той точки зрения, что это наоборот поможет раньше обнаружить и устранить ошибку.
mlock
По-умолчанию вся файловая память является вытесняемой, но ядро Linux предоставляет возможность запрещать её вытеснение с точностью не только до файлов, но и до страниц внутри файла.
Для этого используется системный вызов mlock на области виртуальной памяти, полученной с помощью mmap . Если спускаться до уровня системных вызовов не хочется, рекомендую посмотреть в сторону консольной утилиты vmtouch , которая делает ровно то же самое, но снаружи относительно приложения.
Несколько примеров, когда это может быть целесообразно:
- У приложения большой исполняемый файл с большим количеством ветвлений, некоторые из которых срабатывают редко, но регулярно. Такого стоит избегать и по другим причинам, но если иначе никак, то чтобы не ждать лишнего на этих редких ветках кода — можно запретить им вытесняться.
- Индексы в базах данных часто физически представляют собой именно файл, с которым работают через mmap , а mlock нужен чтобы минимизировать задержки и число операций ввода-вывода на и без того нагруженном диске(-ах).
- Приложение использует какой-то статический словарь, например с соответствием подсетей IP-адресов и стран, к которым они относятся. Вдвойне актуально, если на одном сервере запущено несколько процессов, работающих с этим словарем.
OOM killer
Перестаравшись с невытесняемой памятью не трудно загнать операционную систему в ситуацию, когда физическая память кончилась, а вытеснять ничего нельзя. Безысходной она выглядит лишь на первый взгляд: вместо вытеснения память можно освободить.
Происходит это достаточно радикальными методами: послуживший названием данного раздела механизм выбирает по определенному алгоритму процесс, которым наиболее целесообразно в текущий момент пожертвовать — с остановкой процесса освобождается использовавшаяся им память, которую можно перераспределить между выжившими. Основной критерий для выбора: текущее потребление физической памяти и других ресурсов, плюс есть возможность вмешаться и вручную пометить процессы как более или менее ценные, а также вовсе исключить из рассмотрения. Если отключить OOM killer полностью, то системе в случае полного дефицита ничего не останется, как перезагрузиться.
cgroups
По-умолчанию все пользовательские процессы наравне претендуют на почти всю физически доступную память в рамках одного сервера. Это поведение редко является приемлемым. Даже если сервер условно-однозадачный, например только отдает статические файлы по HTTP с помощью nginx, всегда есть какие-то служебные процессы вроде syslog или какой-то временной команды, запущенной человеком. Если же на сервере одновременно работает несколько production процессов, например, популярный вариант — подсадить к веб-серверу memcached, крайне желательно, чтобы они не могли начать «воевать» друг с другом за память в случае её дефицита.
Но на мой взгляд именно контроль за потреблением памяти — самый необходимый минимум, который определенно стоит настроить, остальное уже по желанию/необходимости.
В многопроцессорных системах не вся память одинакова. Если на материнской плате предусмотрено N процессоров (например, 2 или 4), то как правило все слоты для оперативной памяти физически разделены на N групп так, что каждая из них располагается ближе к соответствующему ей процессору — такую схему называют NUMA .
Таким образом, каждый процессор может обращаться к определенной 1/N части физической памяти быстрее (примерно раза в полтора), чем к оставшимся (N-1)/N .
Ядро Linux самостоятельно умеет это всё определять и по-умолчанию достаточно разумным образом учитывать при планировании выполнения процессоров и выделении им памяти. Посмотреть как это все выглядит и подкорректировать можно с помощью утилиты numactl и ряда доступных системных вызовов, в частности get_mempolicy / set_mempolicy .
Операции с памятью
Есть несколько тем, с которыми в реальности сталкиваются лишь C/C++ разработчики низкоуровневых систем, и не мне им про это рассказывать. Но даже если напрямую с этим не сталкиваться на мой взгляд полезно в общих чертах знать, какие бывают нюансы:
- Операции, работающие с памятью:
- В большинстве своем не атомарны (то есть другой поток может их «увидеть» на полпути), без явной синхронизации атомарность возможна только для блоков памяти не больше указателя (т.е. как правило 64 бита) и то при определенных условиях.
- В реальности происходят далеко не всегда в том порядке, в котором они написаны в исходном коде программы: процессоры и компиляторы на правах оптимизации могут менять их порядок, как считают нужным. В случае многопоточных программ эти оптимизации часто могут приводить к нарушению логики их работы. Для предотвращения подобных ошибок разработчики могут использовать специальные инструменты, в частности барьеры памяти — инструкции, которые запрещают переносить операции с памятью между частями программы до неё и после.
- Новые процессы создаются с помощью системного вызова fork , который порождает копию текущего процесса (чтобы запустить другую программу в новом процессе существует отдельное семейство системных вызовов — exec ), у которого виртуальное пространство практически полностью идентично родительскому, что не потребляет дополнительной физической памяти до тех пор, пока тот или другой не начнут его изменять. Этот механизм называется copy on write и на нем можно играть для создания большого числа однотипных независимых процессов (например, обрабатывающих какие-то запросы), с минимумом дополнительных расходов физической памяти — в некоторых случаях так жить удобнее, чем с многопоточным приложением.
- Между процессором и оперативной памятью находится несколько уровней кешей, обращение к которым ещё на порядки быстрее, чем к оперативной памяти. К самому быстрому — доли наносекунд, к самому медленному единицы наносекунд. На особенностях их работы можно делать микро оптимизации, но из высокоуровневых языков программирования до них толком не добраться.
Итого
Подсистему памяти в Linux нельзя бросать на произвол судьбы. Как минимум, стоит следить за следующими показателями и вывести на приборы (как суммарно, так и по процессам или их группам):
В штатном режиме все три показателя должны быть стабильны (а первые два — близки к нулю). Всплески или плавный рост стоит рассматривать как аномалию, в причинах которой стоит разобраться. Какими методами — надеюсь я показал достаточно направлений, куда можно по-копать.
- Статья написана с ориентиром на современные Debian-like дистрибутивы Linux и физическое оборудование с двумя процеcсорами Intel Xeon. Общие принципы ортогональны этому и справедливы даже для других операционных систем, но вот детали могут сильно разниться даже в зависимости от сборки ядра или конфигурации.
- У большинства упомянутых выше системных вызовов, функций и команд есть man , к которому рекомендую обращаться за подробностями об их использовании и работе. Если под рукой нет linux-машины, где можно набрать man foo — они обычно легко ищутся с таким же запросом.
- Если есть желание углубиться в какую-либо из затронутых вскользь тем — пишите об этом в комментариях, любая из них может стать заголовком отдельной статьи.
На последок ещё раз повторю цифры, которые настоятельно рекомендую запомнить:
Источник



